
10.8: t Distribution
- Page ID
- 2629

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Learning Objectives
- State the difference between the shape of the \(t\) distribution and the normal distribution
- State how the difference between the shape of the \(t\) distribution and normal distribution is affected by the degrees of freedom
- Use a \(t\) table to find the value of \(t\) to use in a confidence interval
- Use the \(t\) calculator to find the value of \(t\) to use in a confidence interval
In the introduction to normal distributions it was shown that \(95\%\) of the area of a normal distribution is within \(1.96\) standard deviations of the mean. Therefore, if you randomly sampled a value from a normal distribution with a mean of \(100\), the probability it would be within \(1.96\sigma \) of \(100\) is \(0.95\). Similarly, if you sample \(N\) values from the population, the probability that the sample mean (\(M\)) will be within \(1.96\sigma _M\) of \(100\) is \(0.95\).
Now consider the case in which you have a normal distribution but you do not know the standard deviation. You sample \(N\) values and compute the sample mean (\(M\)) and estimate the standard error of the mean (\(\sigma _M\)) with \(s_M\). What is the probability that \(M\) will be within \(1.96 s_M\) of the population mean (\(\mu\))?
This is a difficult problem because there are two ways in which \(M\) could be more than \(1.96 s_M\) from \(\mu\):
- \(M\) could, by chance, be either very high or very low and
- \(s_M\) could, by chance, be very low.
Intuitively, it makes sense that the probability of being within \(1.96\) standard errors of the mean should be smaller than in the case when the standard deviation is known (and cannot be underestimated). But exactly how much smaller? Fortunately, the way to work out this type of problem was solved in the early \(20^{th}\) century by W. S. Gosset who determined the distribution of a mean divided by an estimate of its standard error. This distribution is called the Student's \(t\) distribution or sometimes just the \(t\) distribution. Gosset worked out the \(t\) distribution and associated statistical tests while working for a brewery in Ireland. Because of a contractual agreement with the brewery, he published the article under the pseudonym "Student." That is why the \(t\) test is called the "Student's \(t\) test."
The \(t\) distribution is very similar to the normal distribution when the estimate of variance is based on many degrees of freedom, but has relatively more scores in its tails when there are fewer degrees of freedom. Figure \(\PageIndex{1}\) shows \(t\) distributions with \(2\), \(4\), and \(10\) degrees of freedom and the standard normal distribution. Notice that the normal distribution has relatively more scores in the center of the distribution and the \(t\) distribution has relatively more in the tails. The \(t\) distribution is therefore leptokurtic. The \(t\) distribution approaches the normal distribution as the degrees of freedom increase.
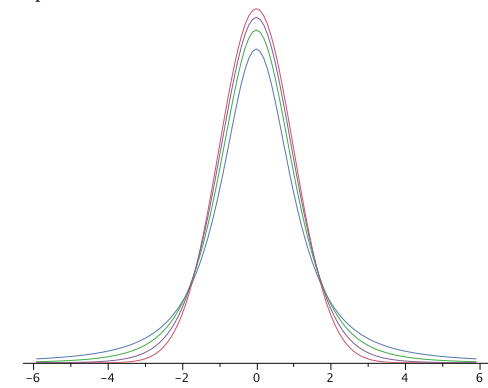
Since the \(t\) distribution is leptokurtic, the percentage of the distribution within \(1.96\) standard deviations of the mean is less than the \(95\%\) for the normal distribution. Table \(\PageIndex{1}\) shows the number of standard deviations from the mean required to contain \(95\%\) and \(99\%\) of the area of the \(t\) distribution for various degrees of freedom. These are the values of \(t\) that you use in a confidence interval. The corresponding values for the normal distribution are \(1.96\) and \(2.58\) respectively. Notice that with few degrees of freedom, the values of \(t\) are much higher than the corresponding values for a normal distribution and that the difference decreases as the degrees of freedom increase. The values in Table \(\PageIndex{1}\) can be obtained from the "Find \(t\) for a confidence interval" calculator.
Table \(\PageIndex{1}\): Abbreviated \(t\) table
| df | 0.95 | 0.99 |
|---|---|---|
| 2 | 4.303 | 9.925 |
| 3 | 3.182 | 5.841 |
| 4 | 2.776 | 4.604 |
| 5 | 2.571 | 4.032 |
| 8 | 2.306 | 3.355 |
| 10 | 2.228 | 3.169 |
| 20 | 2.086 | 2.845 |
| 50 | 2.009 | 2.678 |
| 100 | 1.984 | 2.626 |
Returning to the problem posed at the beginning of this section, suppose you sampled \(9\) values from a normal population and estimated the standard error of the mean (\(\sigma _M\)) with \(s_M\). What is the probability that \(M\) would be within \(1.96 s_M\) of \(\mu\)? Since the sample size is \(9\), there are \(N - 1 = 8 df\). From Table \(\PageIndex{1}\) you can see that with \(8 df\) the probability is \(0.95\) that the mean will be within \(2.306 s_M\) of \(\mu\). The probability that it will be within \(1.96 s_M\) of \(\mu\) is therefore lower than \(0.95\).
As shown in Figure \(\PageIndex{2}\), the "\(t\) distribution" calculator can be used to find that \(0.086\) of the area of a \(t\) distribution is more than \(1.96\) standard deviations from the mean, so the probability that \(M\) would be less than \(1.96 s_M\) from \(\mu\) is \(1 - 0.086 = 0.914\).
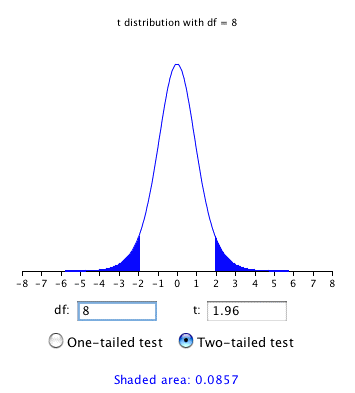
As expected, this probability is less than \(0.95\) that would have been obtained if \(\sigma _M\) had been known instead of estimated.