
10.2: Correlation
- Page ID
- 5221

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)A correlation exists between two variables when the values of one variable are somehow associated with the values of the other variable.
When you see a pattern in the data you say there is a correlation in the data. Though this book is only dealing with linear patterns, patterns can be exponential, logarithmic, or periodic. To see this pattern, you can draw a scatter plot of the data.
Remember to read graphs from left to right, the same as you read words. If the graph goes up the correlation is positive and if the graph goes down the correlation is negative.
The words “ weak”, “moderate”, and “strong” are used to describe the strength of the relationship between the two variables.
.png?revision=1)
The linear correlation coefficient is a number that describes the strength of the linear relationship between the two variables. It is also called the Pearson correlation coefficient after Karl Pearson who developed it. The symbol for the sample linear correlation coefficient is r. The symbol for the population correlation coefficient is \(\rho\) (Greek letter rho).
The formula for r is
\(r=\dfrac{S S_{x y}}{\sqrt{S S_{x} S S_{y}}}\)
Where
\(\begin{array}{l}{S S_{x}=\sum(x-\overline{x})^{2}} \\ {S S_{y}=\sum(y-\overline{y})^{2}} \\ {S S_{x y}=\sum(x-\overline{x})(y-\overline{y})}\end{array}\)
Assumptions of linear correlation are the same as the assumptions for the regression line:
- The set (x, y) of ordered pairs is a random sample from the population of all such possible (x, y) pairs.
- For each fixed value of x, the y -values have a normal distribution. All of the y -distributions have the same variance, and for a given x-value, the distribution of y-values has a mean that lies on the least squares line. You also assume that for a fixed y, each x has its own normal distribution. This is difficult to figure out, so you can use the following to determine if you have a normal distribution.
- Look to see if the scatter plot has a linear pattern.
- Examine the residuals to see if there is randomness in the residuals. If there is a pattern to the residuals, then there is an issue in the data.
Note
Interpretation of the correlation coefficient
r is always between -1 and 1. r = -1 means there is a perfect negative linear correlation and r = 1 means there is a perfect positive correlation. The closer r is to 1 or -1, the stronger the correlation. The closer r is to 0, the weaker the correlation.
CAREFUL: r = 0 does not mean there is no correlation. It just means there is no linear correlation. There might be a very strong curved pattern.
r
How strong is the positive relationship between the alcohol content and the number of calories in 12-ounce beer? To determine if there is a positive linear correlation, a random sample was taken of beer’s alcohol content and calories for several different beers ("Calories in beer," 2011), and the data are in Table \(\PageIndex{1}\). Find the correlation coefficient and interpret that value.
| Brand | Brewery | Alcohol Content | Calories in 12 oz |
|---|---|---|---|
| Big Sky Scape Goat Pale Ale | Big Sky Brewing | 4.70% | 163 |
| Sierra Nevada Harvest Ale | Sierra Nevada | 6.70% | 215 |
| Steel Reserve | MillerCoors | 8.10% | 222 |
| Coors Light | MillerCoors | 4.15% | 104 |
| Genesee Cream Ale | High Falls Brewing | 5.10% | 162 |
| Sierra Nevada Summerfest Beer | Sierra Nevada | 5.00% | 158 |
| Michelob Beer | Anheuser Busch | 5.00% | 155 |
| Flying Dog Doggie Style | Flying Dog Brewery | 4.70% | 158 |
| Big Sky I.P.A. | Big Sky Brewing | 6.20% | 195 |
Solution
State random variables
x = alcohol content in the beer
y = calories in 12 ounce beer
Assumptions check:
From Example \(\PageIndex{2}\), the assumptions have been met.
To compute the correlation coefficient using the TI-83/84 calculator, use the LinRegTTest in the STAT menu. The setup is in Figure \(\PageIndex{2}\). The reason that >0 was chosen is because the question was asked if there was a positive correlation. If you are asked if there is a negative correlation, then pick <0. If you are just asked if there is a correlation, then pick \(\neq 0\). Right now the choice will not make a different, but it will be important later.
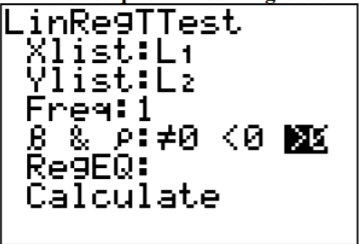.png?revision=1)
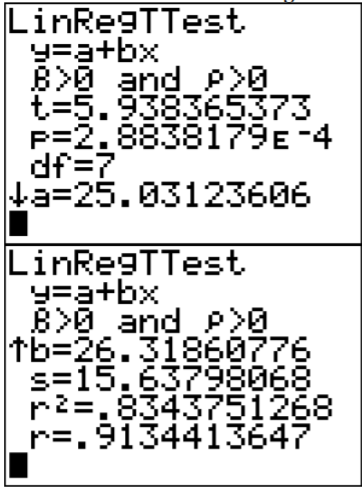.png?revision=1)
To compute the correlation coefficient in R, the command is cor(independent variable, dependent variable). So for this example the command would be cor(alcohol, calories). The output is
[1] 0.9134414
The correlation coefficient is r = 0.913. This is close to 1, so it looks like there is a strong, positive correlation.
Causation
One common mistake people make is to assume that because there is a correlation, then one variable causes the other. This is usually not the case. That would be like saying the amount of alcohol in the beer causes it to have a certain number of calories. However, fermentation of sugars is what causes the alcohol content. The more sugars you have, the more alcohol can be made, and the more sugar, the higher the calories. It is actually the amount of sugar that causes both. Do not confuse the idea of correlation with the concept of causation. Just because two variables are correlated does not mean one causes the other to happen.
Example \(\PageIndex{2}\) correlation versus Causation
- A study showed a strong linear correlation between per capita beer consumption and teacher’s salaries. Does giving a teacher a raise cause people to buy more beer? Does buying more beer cause teachers to get a raise?
- A study shows that there is a correlation between people who have had a root canal and those that have cancer. Does that mean having a root canal causes cancer?
Solution
a. There is probably some other factor causing both of them to increase at the same time. Think about this: In a town where people have little extra money, they won’t have money for beer and they won’t give teachers raises. In another town where people have more extra money to spend it will be easier for them to buy more beer and they would be more willing to give teachers raises.
b. Just because there is positive correlation doesn’t mean that one caused the other. It turns out that there is a positive correlation between eating carrots and cancer, but that doesn’t mean that eating carrots causes cancer. In other words, there are lots of relationships you can find between two variables, but that doesn’t mean that one caused the other.
Remember a correlation only means a pattern exists. It does not mean that one variable causes the other variable to change.
Explained Variation
As stated before, there is some variability in the dependent variable values, such as calories. Some of the variation in calories is due to alcohol content and some is due to other factors. How much of the variation in the calories is due to alcohol content?
When considering this question, you want to look at how much of the variation in calories is explained by alcohol content and how much is explained by other variables. Realize that some of the changes in calories have to do with other ingredients. You can have two beers at the same alcohol content, but beer one has higher calories because of the other ingredients. Some variability is explained by the model and some variability is not explained. Together, both of these give the total variability. This is
\(\begin{array}{ccccc} {\text{(total variation)}}&{=}&{\text{(explained variation)}}&{+}&{\text{(unexplained variation)}}\\ {\sum(y-\overline{y})^{2}}&{=}& {\sum(\hat{y}-\overline{y})^{2}}&{+}&{\sum(y-\hat{y})^{2}} \end{array}\)
Note
The proportion of the variation that is explained by the model is
\(r^{2}=\dfrac{\text { explained variation }}{\text { total variation }}\)
This is known as the coefficient of determination.
To find the coefficient of determination, you square the correlation coefficient. In addition, \(r^{2}\) is part of the calculator results.
Example \(\PageIndex{3}\) finding the coefficient of determination
Find the coefficient of variation in calories that is explained by the linear relationship between alcohol content and calories and interpret the value.
Solution
From the calculator results,
\(r^{2} = 0.8344\)
Using R, you can do (cor(independent variable, dependent variable))^2. So that would be (cor(alcohol, calories))^2, and the output would be
[1] 0.8343751
Or you can just use a calculator and square the correlation value.
Thus, 83.44% of the variation in calories is explained to the linear relationship between alcohol content and calories. The other 16.56% of the variation is due to other factors. A really good coefficient of determination has a very small, unexplained part.
and \(r^{2}\)
How strong is the relationship between the alcohol content and the number of calories in 12-ounce beer? To determine if there is a positive linear correlation, a random sample was taken of beer’s alcohol content and calories for several different beers ("Calories in beer," 2011), and the data are in Example \(\PageIndex{1}\). Find the correlation coefficient and the coefficient of determination using the formula.
Solution
From Example \(\PageIndex{2}\), \(S S_{x}=12.45, S S_{y}=10335.5556, S S_{x y}=327.6667\)
Correlation coefficient:
\(r=\dfrac{S S_{x y}}{\sqrt{S S_{x} S S_{y}}}=\dfrac{327.6667}{\sqrt{12.45 * 10335.5556}} \approx 0.913\)
Coefficient of determination:
\(r^{2}=(r)^{2}=(0.913)^{2} \approx 0.834\)
Now that you have a correlation coefficient, how can you tell if it is significant or not? This will be answered in the next section.
Homework
Exercise \(\PageIndex{1}\)
For each problem, state the random variables. Also, look to see if there are any outliers that need to be removed. Do the correlation analysis with and without the suspected outlier points to determine if their removal affects the correlation. The data sets in this section are in section 10.1 and will be used in section 10.3.
- When an anthropologist finds skeletal remains, they need to figure out the height of the person. The height of a person (in cm) and the length of their metacarpal bone 1 (in cm) were collected and are in Example \(\PageIndex{5}\) ("Prediction of height," 2013). Find the correlation coefficient and coefficient of determination and then interpret both.
- Example \(\PageIndex{6}\) contains the value of the house and the amount of rental income in a year that the house brings in ("Capital and rental," 2013). Find the correlation coefficient and coefficient of determination and then interpret both.
- The World Bank collects information on the life expectancy of a person in each country ("Life expectancy at," 2013) and the fertility rate per woman in the country ("Fertility rate," 2013). The data for 24 randomly selected countries for the year 2011 are in Example \(\PageIndex{7}\). Find the correlation coefficient and coefficient of determination and then interpret both.
- The World Bank collected data on the percentage of GDP that a country spends on health expenditures ("Health expenditure," 2013) and also the percentage of women receiving prenatal care ("Pregnant woman receiving," 2013). The data for the countries where this information is available for the year 2011 are in Example \(\PageIndex{8}\). Find the correlation coefficient and coefficient of determination and then interpret both.
- The height and weight of baseball players are in Example \(\PageIndex{9}\) ("MLB heightsweights," 2013). Find the correlation coefficient and coefficient of determination and then interpret both.
- Different species have different body weights and brain weights are in Example \(\PageIndex{10}\). ("Brain2bodyweight," 2013). Find the correlation coefficient and coefficient of determination and then interpret both.
- A random sample of beef hotdogs was taken and the amount of sodium (in mg) and calories were measured. ("Data hotdogs," 2013) The data are in Example \(\PageIndex{11}\). Find the correlation coefficient and coefficient of determination and then interpret both.
- Per capita income in 1960 dollars for European countries and the percent of the labor force that works in agriculture in 1960 are in Example \(\PageIndex{12}\) ("OECD economic development," 2013). Find the correlation coefficient and coefficient of determination and then interpret both.
- Cigarette smoking and cancer have been linked. The number of deaths per one hundred thousand from bladder cancer and the number of cigarettes sold per capita in 1960 are in Example \(\PageIndex{13}\) ("Smoking and cancer," 2013). Find the correlation coefficient and coefficient of determination and then interpret both.
- The weight of a car can influence the mileage that the car can obtain. A random sample of cars weights and mileage was collected and are in Example \(\PageIndex{14}\) ("Passenger car mileage," 2013). Find the correlation coefficient and coefficient of determination and then interpret both.
- There is a negative correlation between police expenditure and crime rate. Does this mean that spending more money on police causes the crime rate to decrease? Explain your answer.
- There is a positive correlation between tobacco sales and alcohol sales. Does that mean that using tobacco causes a person to also drink alcohol? Explain your answer.
- There is a positive correlation between the average temperature in a location and the morality rate from breast cancer. Does that mean that higher temperatures cause more women to die of breast cancer? Explain your answer.
- There is a positive correlation between the length of time a tableware company polishes a dish and the price of the dish. Does that mean that the time a plate is polished determines the price of the dish? Explain your answer.
- Answer
-
Only the correlation coefficient and coefficient of determination are given. See solutions for the entire answer.
1. r = 0.9578, \(r^{2}\) = 0.7357
3. r = -0.9313, \(r^{2}\) = 0.8674
5. r = 0.6605, \(r^{2}\) = 0.4362
7. r = 0.8871, \(r^{2}\) = 0.7869
9. r = 0.7036, \(r^{2}\) = 0.4951
11. No, see solutions.
13. No, see solutions.