
12.1.2: Hypothesis Test for a Correlation
- Page ID
- 34784

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)One should perform a hypothesis test to determine if there is a statistically significant correlation between the independent and the dependent variables. The population correlation coefficient \(\rho\) (this is the Greek letter rho, which sounds like “row” and is not a \(p\)) is the correlation among all possible pairs of data values \((x, y)\) taken from a population.
We will only be using the two-tailed test for a population correlation coefficient \(\rho\). The hypotheses are:
\(H_{0}: \rho = 0\)
\(H_{1}: \rho \neq 0\)
The null-hypothesis of a two-tailed test states that there is no correlation (there is not a linear relation) between \(x\) and \(y\). The alternative-hypothesis states that there is a significant correlation (there is a linear relation) between \(x\) and \(y\).
The t-test is a statistical test for the correlation coefficient. It can be used when \(x\) and \(y\) are linearly related, the variables are random variables, and when the population of the variable \(y\) is normally distributed.
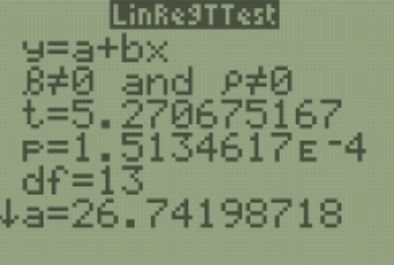
The formula for the t-test statistic is \(t = r \sqrt{\left( \dfrac{n-2}{1-r^{2}} \right)}\).
Use the t-distribution with degrees of freedom equal to \(df = n - 2\).
Note the \(df = n - 2\) since we have two variables, \(x\) and \(y\).
Test to see if the correlation for hours studied on the exam and grade on the exam is statistically significant. Use \(\alpha\) = 0.05.
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.jpg?revision=1)
Correlation is Not Causation
Just because two variables are significantly correlated does not imply a cause and effect relationship. There are several relationships that are possible. It could be that \(x\) causes \(y\) to change. You can actually swap \(x\) and \(y\) in the fields and get the same \(r\) value and \(y\) could be causing \(x\) to change. There could be other variables that are affecting the two variables of interest. For instance, you can usually show a high correlation between ice cream sales and home burglaries. Selling more ice cream does not “cause” burglars to rob homes. More home burglaries do not cause more ice cream sales. We would probably notice that the temperature outside may be causing both ice cream sales to increase and more people to leave their windows open. This third variable is called a lurking variable and causes both \(x\) and \(y\) to change, making it look like the relationship is just between \(x\) and \(y\).
There are also highly correlated variables that seemingly have nothing to do with one another. These seemingly unrelated variables are called spurious correlations.
The following website has some examples of spurious correlations (a slight caution that the author has some gloomy examples): http://www.tylervigen.com/spurious-correlations. Figure 12-7 is one of their examples:
.png?revision=1)
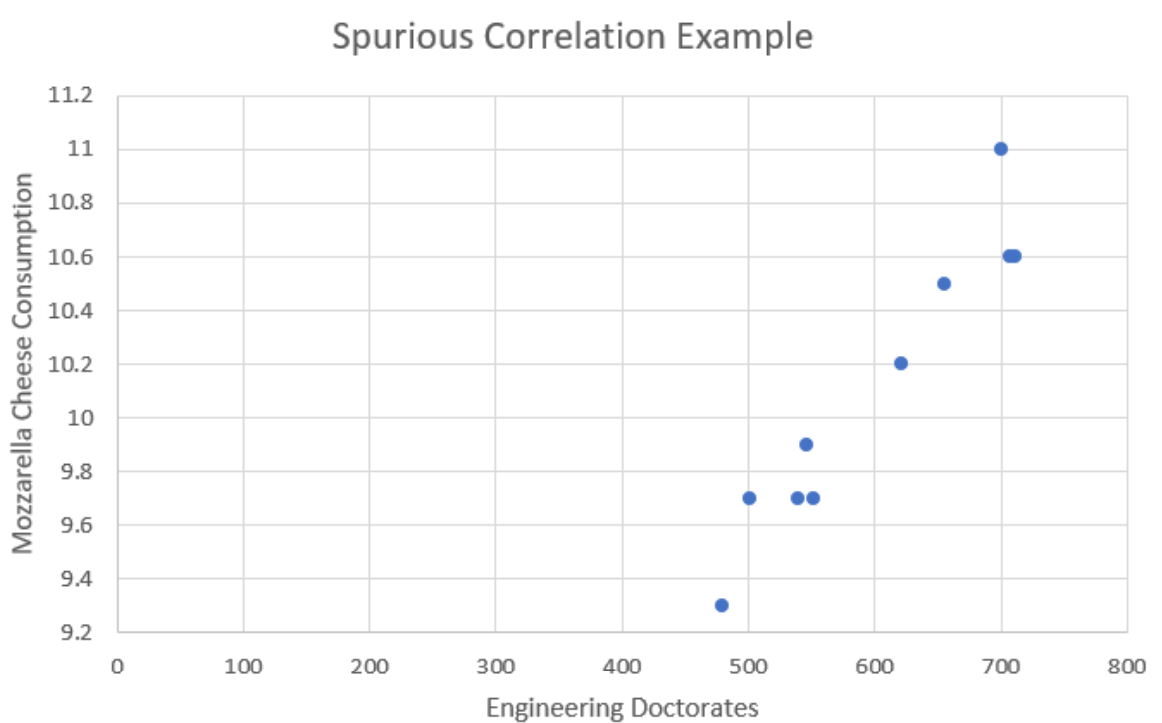
If we were to take out each pair of measurements by year from the time-series plot in Figure 12-7, we would get the following data.
| Year | Engineering Doctorates | Mozzarella Cheese Consumption |
|---|---|---|
| 2000 | 480 | 9.3 |
| 2001 | 501 | 9.7 |
| 2002 | 540 | 9.7 |
| 2003 | 552 | 9.7 |
| 2004 | 547 | 9.9 |
| 2005 | 622 | 10.2 |
| 2006 | 655 | 10.5 |
| 2007 | 701 | 11 |
| 2008 | 712 | 10.6 |
| 2009 | 708 | 10.6 |
Using Excel to find a scatterplot and compute a correlation coefficient, we get the scatterplot shown in Figure 12-8 and a correlation of \(r = 0.9586\).
.png?revision=1)
With \(r = 0.9586\), there is strong correlation between the number of engineering doctorate degrees earned and mozzarella cheese consumption over time, but earning your doctorate degree does not cause one to go eat more cheese. Nor does eating more cheese cause people to earn a doctorate degree. Most likely these items are both increasing over time and therefore show a spurious correlation to one another.
When two variables are correlated, it does not imply that one variable causes the other variable to change.
“Correlation is causation” is an incorrect assumption that because something correlates, there is a causal relationship. Causality is the area of statistics that is most commonly misused, and misinterpreted, by people. Media, advertising, politicians and lobby groups often leap upon a perceived correlation and use it to “prove” their own agenda. They fail to understand that, just because results show a correlation, there is no proof of an underlying causality. Many people assume that because a poll, or a statistic, contains many numbers, it must be scientific, and therefore correct. The human brain is built to try and subconsciously establish links between many pieces of information at once. The brain often tries to construct patterns from randomness, and may jump to conclusions, and assume that a cause and effect relationship exists. Relationships may be accidental or due to other unmeasured variables. Overcoming this tendency to jump to a cause and effect relationship is part of academic training for students and in most fields, from statistics to the arts.
Summary
When looking at correlations, start with a scatterplot to see if there is a linear relationship prior to finding a correlation coefficient. If there is a linear relationship in the scatterplot, then we can find the correlation coefficient to tell the strength and direction of the relationship. Clusters of dots forming a linear uphill pattern from left to right will have a positive correlation. The closer the dots in the scatterplot are to a straight line, the closer \(r\) will be to \(1\). If the cluster of dots in the scatterplots go downhill from left to right in linear pattern, then there is a negative relationship. The closer those dots in the scatterplot are to a straight line going downhill, the closer \(r\) will be to \(-1\). Use a t-test to see if the correlation is statistically significant. As sample sizes get larger, smaller values of \(r\) become statistically significant. Be careful with outliers, which can heavily influence correlations. Most importantly, correlation is not causation. When \(x\) and \(y\) are significantly correlated, this does not mean that \(x\) causes \(y\) to change.