
12.1.1: Scatterplots
- Page ID
- 34783

A scatterplot shows the relationship between two quantitative variables measured on the same individuals.
- The predictor variable is labeled on the horizontal or \(x\)-axis.
- The response variable is labeled on the vertical or \(y\)-axis.
How to Interpret a Scatterplot:
- Look for the overall pattern and for deviations from that pattern.
- Look for outliers, individual values that fall outside the overall pattern of the relationship.
- A positive linear relation results when larger values of one variable are associated with larger values of the other.
- A negative linear relation results when larger values of one variable are associated with smaller values of the other.
- A scatterplot has no association if no obvious linear pattern is present.
Use technology to make a scatterplot for the following sample data set:
.png?revision=1)
.png?revision=1)
.png?revision=1)
.jpg?revision=1&size=bestfit&width=995&height=741)
Correlation Coefficient
The sample correlation coefficient measures the direction and strength of the linear relationship between two quantitative variables. There are several different types of correlations. We will be using the Pearson Product Moment Correlation Coefficient (PPMCC). The PPMCC is named after biostatistician Karl Pearson. We will just use the lower-case \(r\) for short when we want to find the correlation coefficient, and the Greek letter \(\rho\), pronounced “rho,” (rhymes with sew) when referring to the population correlation coefficient.

Interpreting the Correlation:
- A positive \(r\) indicates a positive association (positive linear slope).
- A negative \(r\) indicates a negative association (negative linear slope).
- \(r\) is always between \(-1\) and \(1\), inclusive.
- If \(r\) is close to \(1\) or \(-1\), there is a strong linear relationship between \(x\) and \(y\).
- If \(r\) is close to \(0\), there is a weak linear relationship between \(x\) and \(y\). There may be a non-linear relation or there may be no relation at all.
- Like the mean, \(r\) is strongly affected by outliers. Figure 12-1 gives examples of correlations with their corresponding scatterplots.
.png?revision=1)
When you have a correlation that is very close to \(-1\) or \(1\), then the points on the scatter plot will line up in an almost perfect line. The closer \(r\) gets to \(0\), the more scattered your points become.
Take a moment and see if you can guess the approximate value of \(r\) for the scatter plots below.
.png?revision=1)
Solution
Scatterplot A: \(r = 0.98\), Scatterplot B: \(r = 0.85\), Scatterplot C: \(r = -0.85\).
When \(r\) is equal to \(-1\) or \(1\) all the dots in the scatterplot line up in a straight line. As the points disperse, \(r\) gets closer to zero. The correlation tells the direction of a linear relationship only. It does not tell you what the slope of the line is, nor does it recognize nonlinear relationships. For instance, in Figure 12-2, there are three scatterplots overlaid on the same set of axes. All three data sets would have \(r = 1\) even though they all have different slopes.
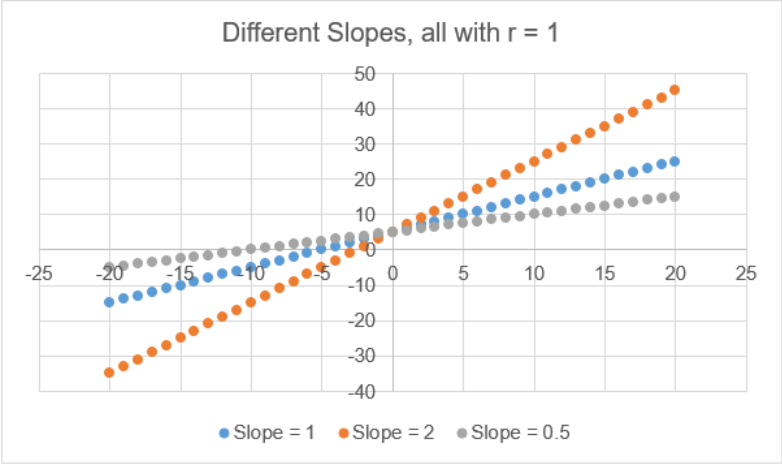.png?revision=1)
For the next example in Figure 12-3, \(r = 0\) would indicate no linear relationship; however, there is clearly a non-linear pattern with the data.
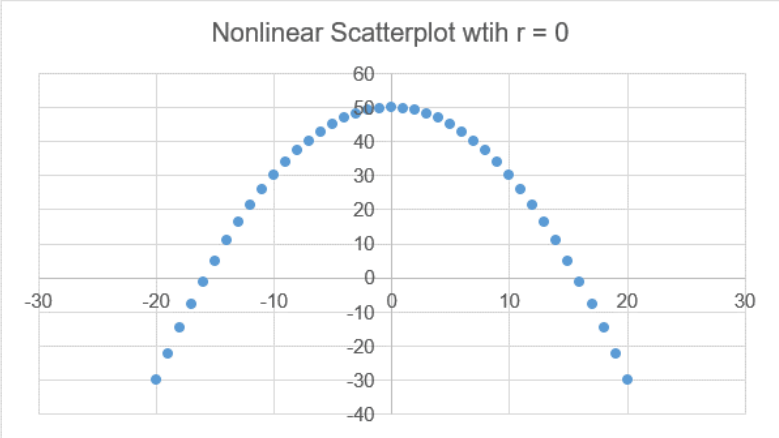.png?revision=1)
Figure 12-4 shows a correlation \(r = 0.874\), which is pretty close to one, indicating a strong linear relationship. However, there is an outlier, called a leverage point, which is inflating the value of the slope. If you remove the outlier then \(r = 0\), and there is no up or down trend to the data.
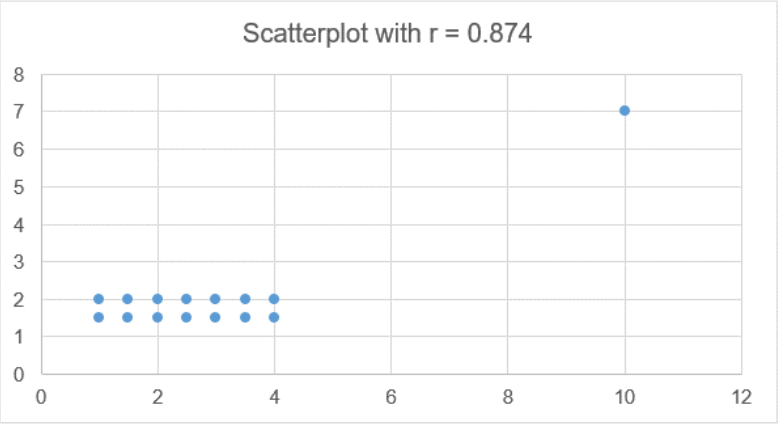.png?revision=1)
Calculating Correlation
To calculate the correlation coefficient by hand we would use the following formula.
\[r = \frac{\sum \left( \left(x_{i} - \bar{x}\right) \left(y_{i} - \bar{y}\right) \right)}{\sqrt{ \left( \left(\sum \left(x_{i} - \bar{x}\right)^{2}\right) \left(\sum \left(y_{i} - \bar{y}\right)^{2}\right) \right)} } = \frac{SS_{xy}}{\sqrt{ \left(SS_{xx} \cdot SS_{yy}\right) }}\]
Instead of doing all of these sums by hand we can use the output from summary statistics. Recall that the formula for a variance of a sample is \(s_{x}^{2} = \frac{\sum \left(x_{i} - \bar{x}\right)^{2}}{n-1}\). If we were to multiply both sides by the degrees of freedom, we would get \(\sum \left(x_{i} - \bar{x}\right)^{2} = (n-1) s_{x}^{2}\).
We use these sums of squares \(\sum \left(x_{i} - \bar{x}\right)^{2}\) frequently, so for shorthand we will use the notation \(SS_{xx} = \sum \left(x_{i} - \bar{x}\right)^{2}\). The same would hold true for the \(y\) variable; just changing the letter, the variance of \(y\) would be \(s_{y}^{2} = \frac{\sum \left(y_{i} - \bar{y}\right)^{2}}{n-1}\), therefore \(SS_{yy} = (n-1) s_{y}^{2}\).
The numerator of the correlation formula is taking in the horizontal distance of each data point from the mean of the \(x\) values, times the vertical distance of each point from the mean of the \(y\) values. This is time-consuming to find so we will use an algebraically equivalent formula \(\sum \left(\left(x_{i} - \bar{x}\right) \left(y_{i} - \bar{y}\right) \right) = \sum (xy) - n \cdot \bar{x} \bar{y}\), and for short we will use the notation \(SS_{xy} = \sum (xy) - n \cdot \bar{x} \bar{y}\).
To start each problem, use descriptive statistics to find the sum of squares.
| \(SS_{xx} = (n-1) s_{x}^{2}\) | \(SS_{yy} = (n-1) s_{y}^{2}\) | \(SS_{xy} = sum (xy) - n \cdot \bar{x} \bar{y}\) |
Use the following data to calculate the correlation coefficient.
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
When is a correlation statistically significant? The next subsection shows how to run a hypothesis test for correlations.