
16.3: Tukey Ladder of Powers
- Page ID
- 2182

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Learning Objectives
- Give the Tukey ladder of transformations
- Find a transformation that reveals a linear relationship
- Find a transformation to approximate a normal distribution
Introduction
We assume we have a collection of bivariate data
\[(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\]
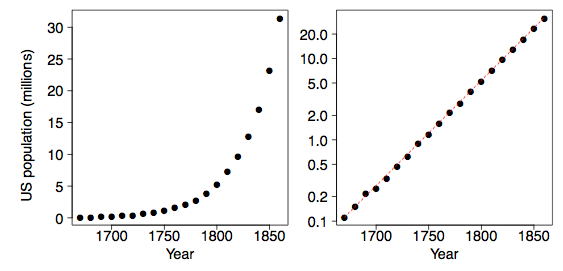
and that we are interested in the relationship between variables \(x\) and \(y\). Plotting the data on a scatter diagram is the first step. As an example, consider the population of the United States for the \(200\) years before the Civil War. Of course, the decennial census began in \(1790\). These data are plotted two ways in Figure \(\PageIndex{1}\). Malthus predicted that geometric growth of populations coupled with arithmetic growth of grain production would have catastrophic results. Indeed the US population followed an exponential curve during this period.
Tukey's Transformation Ladder
Tukey (\(1977\)) describes an orderly way of re-expressing variables using a power transformation. You may be familiar with polynomial regression (a form of multiple regression) in which the simple linear model \(y = b_0 + b_1X\) is extended with terms such as \(b_2X^2 + b_3X^3 + b_4X^4\). Alternatively, Tukey suggests exploring simple relationships such as
\[y = b_0 + b_1X^λ\]
or
\[y^λ = b_0 + b_1X \label{eq1}\]
where \(λ\) is a parameter chosen to make the relationship as close to a straight line as possible. Linear relationships are special, and if a transformation of the type \(x^\lambda\) or yλworks as in Equation \ref{eq1}, then we should consider changing our measurement scale for the rest of the statistical analysis.
There is no constraint on values of \(λ\) that we may consider. Obviously choosing \(λ = 1\) leaves the data unchanged. Negative values of \(λ\) are also reasonable. For example, the relationship
\[y = b_0 + \dfrac{b_1}{x}\]
would be represented by \(λ = −1\). The value \(λ = 0\) has no special value, since \(X^0 = 1\), which is just a constant. Tukey (\(1977\)) suggests that it is convenient to simply define the transformation when \(λ = 0\) to be the logarithm function rather than the constant \(1\). We shall revisit this convention shortly. The following table gives examples of the Tukey ladder of transformations.
| \(\lambda\) | \(-2\) | \(-1\) | \(-1/2\) | \(0\) | \(1/2\) | \(1\) | \(2\) |
| \(y\) | \(\tfrac{1}{x^2}\) | \(\tfrac{1}{x}\) | \(\tfrac{1}{\sqrt{x}}\) | \(\log x\) | \(\sqrt{x}\) | \(x\) | \(x^2\) |
If \(x\) takes on negative values, then special care must be taken so that the transformations make sense, if possible. We generally limit ourselves to variables where \(x > 0\) to avoid these considerations. For some dependent variables such as the number of errors, it is convenient to add \(1\) to \(x\) before applying the transformation.
Also, if the transformation parameter \(λ\) is negative, then the transformed variable \(x^\lambda\) is reversed. For example, if \(x\) is increasing, then \(1/x\) is decreasing. We choose to redefine the Tukey transformation to be \(-x^\lambda\) if \(λ < 0\) in order to preserve the order of the variable after transformation. Formally, the Tukey transformation is defined as
\[y=\left\{\begin{matrix} x^\lambda & if & \lambda >0\\ \log x & if & \lambda =0\\ -(x^\lambda) & if & \lambda <0 \end{matrix}\right.\]
In Table \(\PageIndex{2}\) we reproduce Table \(\PageIndex{1}\) using the modified definition when \(λ < 0\).
| \(\lambda\) | \(-2\) | \(-1\) | \(-1/2\) | \(0\) | \(1/2\) | \(1\) | \(2\) |
| \(y\) | \(\tfrac{-1}{x^2}\) | \(\tfrac{-1}{x}\) | \(\tfrac{-1}{\sqrt{x}}\) | \(\log x\) | \(\sqrt{x}\) | \(x\) | \(x^2\) |
The Best Transformation for Linearity
The goal is to find a value of \(λ\) that makes the scatter diagram as linear as possible. For the US population, the logarithmic transformation applied to \(y\) makes the relationship almost perfectly linear. The red dashed line in the right frame of Figure \(\PageIndex{1}\) has a slope of about \(1.35\); that is, the US population grew at a rate of about \(35\%\) per decade.
The logarithmic transformation corresponds to the choice \(λ = 0\) by Tukey's convention. In Figure \(\PageIndex{2}\), we display the scatter diagram of the US population data for \(λ = 0\) as well as for other choices of \(λ\).
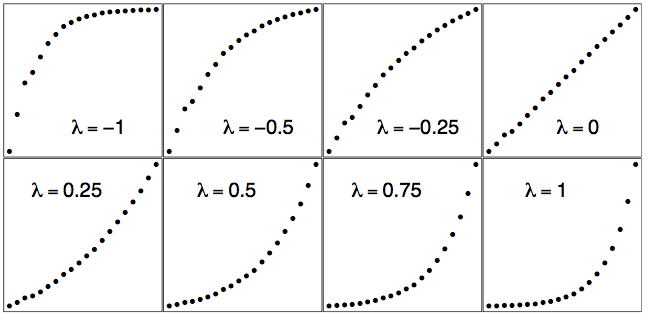
The raw data are plotted in the bottom right frame of Figure \(\PageIndex{2}\) when \(λ = 1\). The logarithmic fit is in the upper right frame when \(λ = 0\). Notice how the scatter diagram smoothly morphs from convex to concave as \(λ\) increases. Thus intuitively there is a unique best choice of \(λ\) corresponding to the "most linear" graph.
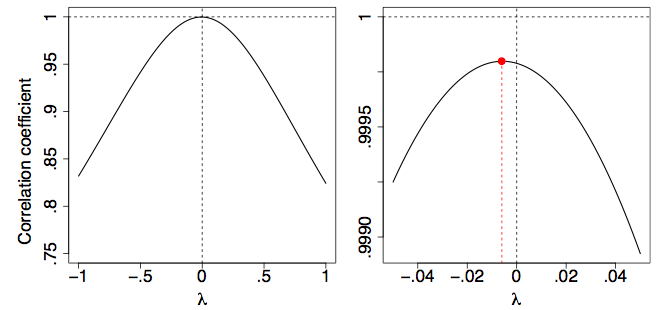
One way to make this choice objective is to use an objective function for this purpose. One approach might be to fit a straight line to the transformed points and try to minimize the residuals. However, an easier approach is based on the fact that the correlation coefficient, \(r\), is a measure of the linearity of a scatter diagram. In particular, if the points fall on a straight line then their correlation will be \(r = 1\). (We need not worry about the case when \(r = −1\) since we have defined the Tukey transformed variable \(x_\lambda\) to be positively correlated with \(x\) itself.)
In Figure \(\PageIndex{3}\), we plot the correlation coefficient of the scatter diagram \((x,y_\lambda )\) as a function of \(λ\). It is clear that the logarithmic transformation (\(λ = 0\)) is nearly optimal by this criterion.
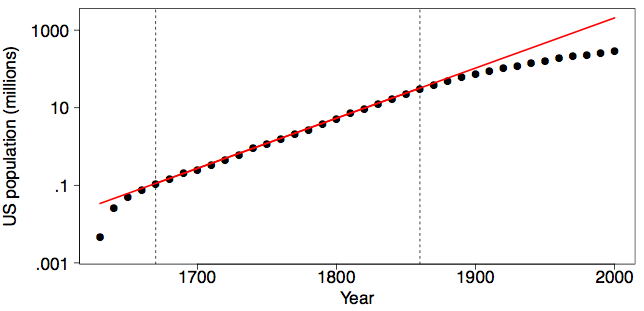
Is the US population still on the same exponential growth pattern? In Figure \(\PageIndex{4}\), we display the US population from \(1630\) to \(2000\) using the transformation and fit used in the right frame of Figure \(\PageIndex{1}\). Fortunately, the exponential growth (or at least its rate) was not sustained into the Twentieth Century. If it had, the US population in the year \(2000\) would have been over \(2\) billion (\(2.07\) to be exact), larger than the population of China.
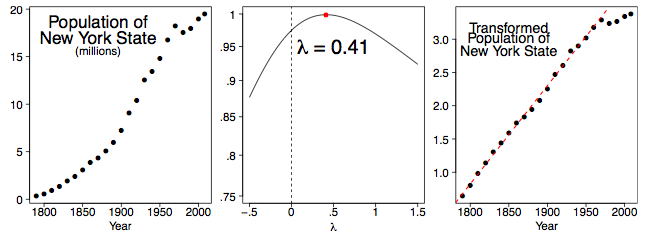
We can examine the decennial census population figures of individual states as well. In Figure \(\PageIndex{5}\), we display the population data for the state of New York from \(1790\) to \(2000\), together with an estimate of the population in \(2008\). Clearly something unusual happened starting in \(1970\). (This began the period of mass migration to the West and South as the rust belt industries began to shut down.) Thus, we compute the best \(λ\) value using the data from \(1790\)-\(1960\) in the middle frame of Figure \(\PageIndex{5}\). The right frame displays the transformed data, together with the linear fit for the \(1790-1960\) period. The value of \(λ = 0.41\) is not obvious and one might reasonably choose to use \(λ = 0.50\) for practical reasons.
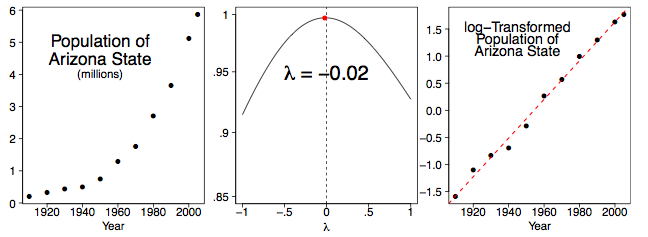
If we look at one of the younger states in the West, the picture is different. Arizona has attracted many retirees and immigrants. Figure \(\PageIndex{6}\) summarizes our findings. Indeed, the growth of population in Arizona is logarithmic, and appears to still be logarithmic through \(2005\).
Reducing Skew
Many statistical methods such as \(t\) tests and the analysis of variance assume normal distributions. Although these methods are relatively robust to violations of normality, transforming the distributions to reduce skew can markedly increase their power.
As an example, the data in the "Stereograms" case study are very skewed. A t test of the difference between the two conditions using the raw data results in a p value of \(0.056\), a value not conventionally considered significant. However, after a log transformation (\(λ = 0\)) that reduces the skew greatly, the \(p\) value is \(0.023\) which is conventionally considered significant.
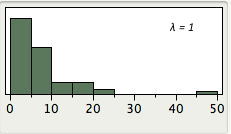
The demonstration in Figure \(\PageIndex{7}\) shows distributions of the data from the Stereograms case study as transformed with various values of \(λ\). Decreasing \(λ\) makes the distribution less positively skewed. Keep in mind that \(λ = 1\) is the raw data. Notice that there is a slight positive skew for \(λ = 0\) but much less skew than found in the raw data (\(λ = 1\)). Values of below 0 result in negative skew.
References
Tukey, J. W. (1977). Exploratory Data Analysis. Addison-Wesley, Reading, MA.