
3.5: SAS Output for ANOVA
- Page ID
- 33438

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The first output of the ANOVA procedure as shown below, gives useful details about the model.
| Model Information | |
|---|---|
| Data Set | WORK.GREENHOUSE |
| Dependent Variable | Height |
| Covariance Structure | Diagonal |
| Estimation Method | Type 3 |
| Residual Variance Method | Factor |
| Fixed Effects SE Method | Model-Based |
| Degrees of Freedom Method | Residual |
| Class Level Information | ||
|---|---|---|
| Class | Levels | Values |
| fert | 4 | Control F1 F2 F3 |
| Dimensions | |
|---|---|
| Covariance Parameters | 1 |
| Columns in X | 5 |
| Columns in Z | 0 |
| Subjects | 0 |
| Max Obs Per Subject | 24 |
The output below titled ‘Type 3 Analysis of Variance’ is similar to the ANOVA table we are already familiar with. Note that it does not include the Total SS, however it can be computed as the sum of all SS values in the table.
| Type 3 Analysis of Variance | ||||||||
|---|---|---|---|---|---|---|---|---|
| Sources | DF | Sum of Squares | Mean Square | Expected Mean Square | Error Term | Error DF | F Value | Pr > F |
| fert | 3 | 251.440000 | 83.813333 | Var(Residual)+Q(fert) | MS(Residual) | 20 | 27.46 | <.0001 |
| Residual | 20 | 61.033333 | 3.051667 | Var(Residual) | ||||
| Covariance Parameter Estimates | |
|---|---|
| Cov Parm | Estimate |
| Residual | 3.0517 |
| Fit Statistics | |
|---|---|
| -2 Res Log Likelihood | 86.2 |
| AIC (smaller is better) | 88.2 |
| AICC (smaller is better) | 88.5 |
| BIC (smaller is better) | 89.2 |
| Type 3 Tests of Fixed Effects | ||||
|---|---|---|---|---|
| Effect | Num DF | Den DF | F Value | Pr > F |
| fert | 3 | 20 | 27.46 | <.0001 |
The output above titled “Type 3 Tests of Fixed Effects” will display the \(F_{calculated}\) and p-value for the test of any variables that are specified in the model statement. Additional information can also be requested. For example, the method = type 3 option will include the Expected Mean Squares for each source, which will prove to be useful and will be seen in Chapter 6.
The Mixed Procedure also produces the following diagnostic plots:


The following display is a result of the LSmeans statement in the PLM procedure which was included in the programming code.
| Differences of fert Least Squares Means | ||||||||
|---|---|---|---|---|---|---|---|---|
| fert | Estimate | Standard Error | DF | t Value | Pr > |t| | Alpha | Lower | Upper |
| Control | 21.0000 | 0.7132 | 20 | 29.45 | <.0001 | 0.05 | 19.5124 | 22.4876 |
| F1 | 28.6000 | 0.7132 | 20 | 40.10 | <.0001 | 0.05 | 27.1124 | 30.0876 |
| F2 | 25.8667 | 0.7132 | 20 | 36.27 | <.0001 | 0.05 | 24.3790 | 27.3543 |
| F3 | 29.2000 | 0.7132 | 20 | 40.94 | <.001 | 0.05 | 27.7124 | 30.6876 |
In the "Least Squares Means" table above, note that the \(t\)-value and \(Pr >|t|\) are testing null hypotheses that each group mean= 0. (These tests usually do not provide any useful information). The Lower and Upper values are the 95% confidence limits for the group means. Note also that the least square means are the same as the original arithmetic means that were generated in the Summary procedure in Section 3.3 because all 4 groups have the same sample sizes. With unequal sample sizes or if there is a covariate present, the least square means can differ from the original sample means.
Next, the Plot= mean plot option in the LSmeans statement yields a mean plot and also a diffogram, shown below. The confidence intervals in the mean plot are commonly used to identify the significantly different treatment levels or groups. If two confidence intervals do not overlap, then the difference between the two associated means is statistically significant, which is a valid conclusion. However, if they overlap, it may be the case that the difference might still be significant. Consequently, conclusions made based on the visual inspection of the mean plot may not match with those arrived at using the table of "Difference of Least Square Means", another output of the Tukey procedure, and is displayed below.
Notice that this is different from the previous table because it displays the results of each pairwise comparison. For example, the first row shows the comparison between the control and F1. The interpretation of these results is similar to any other confidence interval for the difference in two means—if the confidence interval does not contain zero, then the difference between the two associated means is statistically significant.
|
Differences of fert Least Squares Means Adjustment for Multiple Comparisons: Tukey |
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fert | _fert | Estimate | Standard Error | DF | t Value | Pr > |t| | Adj P | Alpha | Lower | Upper | Adj Lower | Adj Upper |
| Control | F1 | -7.6000 | 1.0086 | 20 | -7.54 | <.0001 | <.0001 | 0.05 | -9.7038 | -5.4962 | -10.4229 | -4.7771 |
| Control | F2 | -4.8667 | 1.0086 | 20 | -4.83 | 0.0001 | 0.0006 | 0.05 | -6.9705 | -2.7628 | -7.6896 | -2.0438 |
| Control | F3 | -8.2000 | 1.0086 | 20 | -8.13 | <.0001 | <.0001 | 0.05 | -10.3038 | -6.0962 | -11.0229 | -5.3771 |
| F1 | F2 | 2.7333 | 1.0086 | 20 | 2.71 | 0.0135 | 0.0599 | 0.05 | 0.6295 | 4.8372 | -0.08957 | 5.5562 |
| F1 | F3 | -0.6000 | 1.0086 | 20 | -0.59 | 0.5586 | 0.9324 | 0.05 | -2.7038 | 1.5038 | -3.4229 | 2.2229 |
| F2 | F3 | -3.3333 | 1.0086 | 20 | -3.30 | 0.0035 | .0171 | 0.05 | -5.4372 | -1.2295 | -6.1562 | -0.5104 |
This discrepancy between the mean plot and the "Difference of Least Square Means" results occurs because the testing is done in terms of the difference of two means, using the standard error of the difference of the two-sample means, but the confidence intervals of the mean plot are computed for the individual means which are in terms of the standard error of individual sample means. Consistent results can be achieved by using the diffogram as discussed below or the confidence intervals displayed in the "difference in mean plot" available in SAS 14, but not included here.
The diffogram has two useful features. It allows one to identify the significant mean pairs and also gives estimates of the individual means. The diagonal line shown in the diffogram is used as a reference line. Each group (or factor level) is marked on the horizontal and vertical axes and has vertical and horizontal reference lines with their intersection point falling on the diagonal reference line. The \(x\) or the \(y\) coordinates of this intersection point which are equal is the sample mean of that group. For example, the sample mean for the Control group is about 21, which matches with the estimate provided in the "Least Squares Means" table displayed above. Furthermore, each slanted line represents a mean pair. Start with any group label from the horizontal axis and run your cursor up, along the associated vertical line until it meets a slanted line, and then go across the intersecting horizontal line to identify the other group (or factor level). For example, the lowermost solid line (colored blue) represents the Control and F2. As stated at the bottom of the chart, the solid (or blue) lines indicate significant pairs, and the broken (or red) lines correspond to the non-significant pairs. Furthermore, a line corresponding to a nonsignificant pair will cross the diagonal reference line.

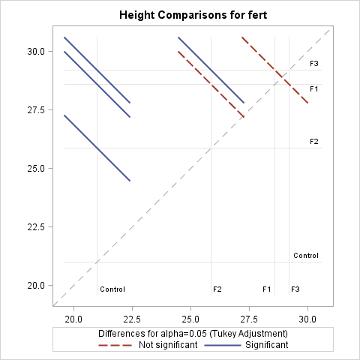
The non-overlapping confidence intervals in the mean plot above indicate that the average plant height due to control is significantly different from those of the other 3 fertilizer levels and that the F2 fertilizer type yields a statistically different average plant height from F3. The diffogram also delivers the same conclusions and so, in this example, conclusions are not contradictory. In general, the diffogram always provides the same conclusions as derived from the confidence intervals of difference of least-square means shown in the "Difference of Least Square Means" table, but the conclusions based on the mean plot may differ.
There are two contrasts of interest: contrast to compare the control and F3 with F1 (i.e. \(\mu_{control} - \mu_{F1} - \mu_{F2} + \mu_{F3}\)) and the contrast to compare control and F2 with F1 (i.e., \(\mu_{control} - 2 \mu_{F1} + \mu_{F2}\)). Since we are testing for two contrasts, we should adjust for multiple comparisons. We use Bonferroni adjustment. In SAS, we can use the estimate command under proc plm to make these computations.
In general, the estimate command estimates linear combinations of model parameters and performs t-tests on them. Contrasts are linear combinations that satisfy a special condition. We will discuss the model parameters in Chapter 4.
| Estimates Adjustment for Multiplicity: Bonferroni |
||||||
|---|---|---|---|---|---|---|
| Label | Estimate | Standard Error | DF | t Value | Pr > |t| | Adj P |
| Compare control + F3 with F1 and F2 | -4.2667 | 1.4263 | 20 | -2.99 | 0.0072 | 0.0144 |
| Compare control + F2 with F1 | -10.3333 | 1.7469 | 20 | -5.92 | <.0001 | <.0001 |
SAS returns both unadjusted and adjusted \(p\)-values. Suppose we wanted to make the comparisons at 1% level. If we ignored the multiple comparisons (i.e. using unadjusted \(p\)-values), the both comparisons are statistically significant. However, if we consider the adjusted \(p\)-values, we will fail to reject the hypothesis corresponding to the first contrast at the 1% level.