
11.3: F-tests for Equality of Two Variances
- Page ID
- 515
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)- To understand what \(F\)-distributions are.
- To understand how to use an \(F\)-test to judge whether two population variances are equal.
\(F\)-Distributions
Another important and useful family of distributions in statistics is the family of \(F\)-distributions. Each member of the \(F\)-distribution family is specified by a pair of parameters called degrees of freedom and denoted \(df_1\) and \(df_2\). Figure \(\PageIndex{1}\) shows several \(F\)-distributions for different pairs of degrees of freedom. An \(F\) random variable is a random variable that assumes only positive values and follows an \(F\)-distribution.
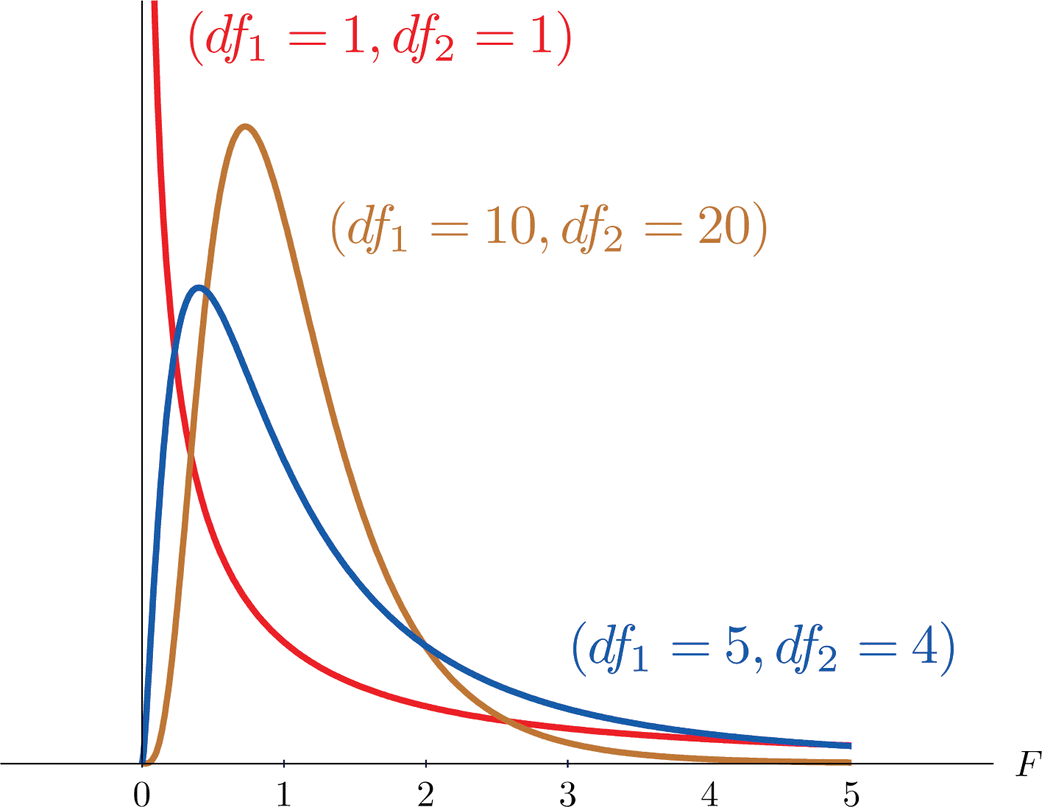
The parameter \(df_1\) is often referred to as the numerator degrees of freedom and the parameter \(df_2\) as the denominator degrees of freedom. It is important to keep in mind that they are not interchangeable. For example, the \(F\)-distribution with degrees of freedom \(df_1=3\) and \(df_2=8\) is a different distribution from the \(F\)-distribution with degrees of freedom \(df_1=8\) and \(df_2=3\).
The value of the \(F\) random variable \(F\) with degrees of freedom \(df_1\) and \(df_2\) that cuts off a right tail of area \(c\) is denoted \(F_c\) and is called a critical value (Figure \(\PageIndex{2}\)).
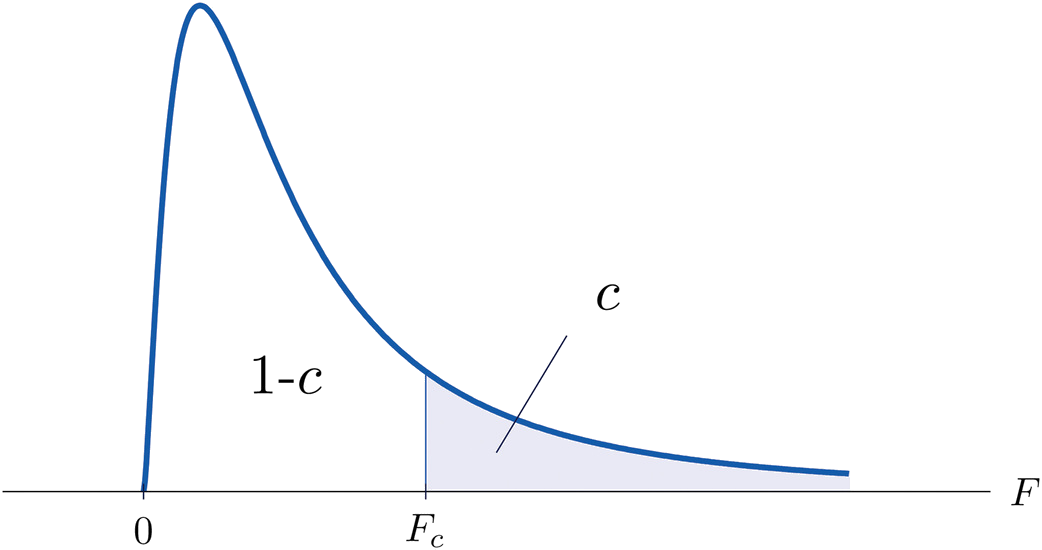
Tables containing the values of \(F_c\) are given in Chapter 11. Each of the tables is for a fixed collection of values of \(c\), either \(0.900,\; 0.950,\; 0.975,\; 0.990,\; \text{and}\; 0.995\) (yielding what are called “lower” critical values), or \(0.005,\; 0.010,\; 0.025,\; 0.050,\; \text{and}\; 0.100\) (yielding what are called “upper” critical values). In each table critical values are given for various pairs \((df_1,\: df_2)\). We illustrate the use of the tables with several examples.
Suppose \(F\) is an \(F\) random variable with degrees of freedom \(df_1=5\) and \(df_2=4\). Use the tables to find
- \(F_{0.10}\)
- \(F_{0.95}\)
Solution
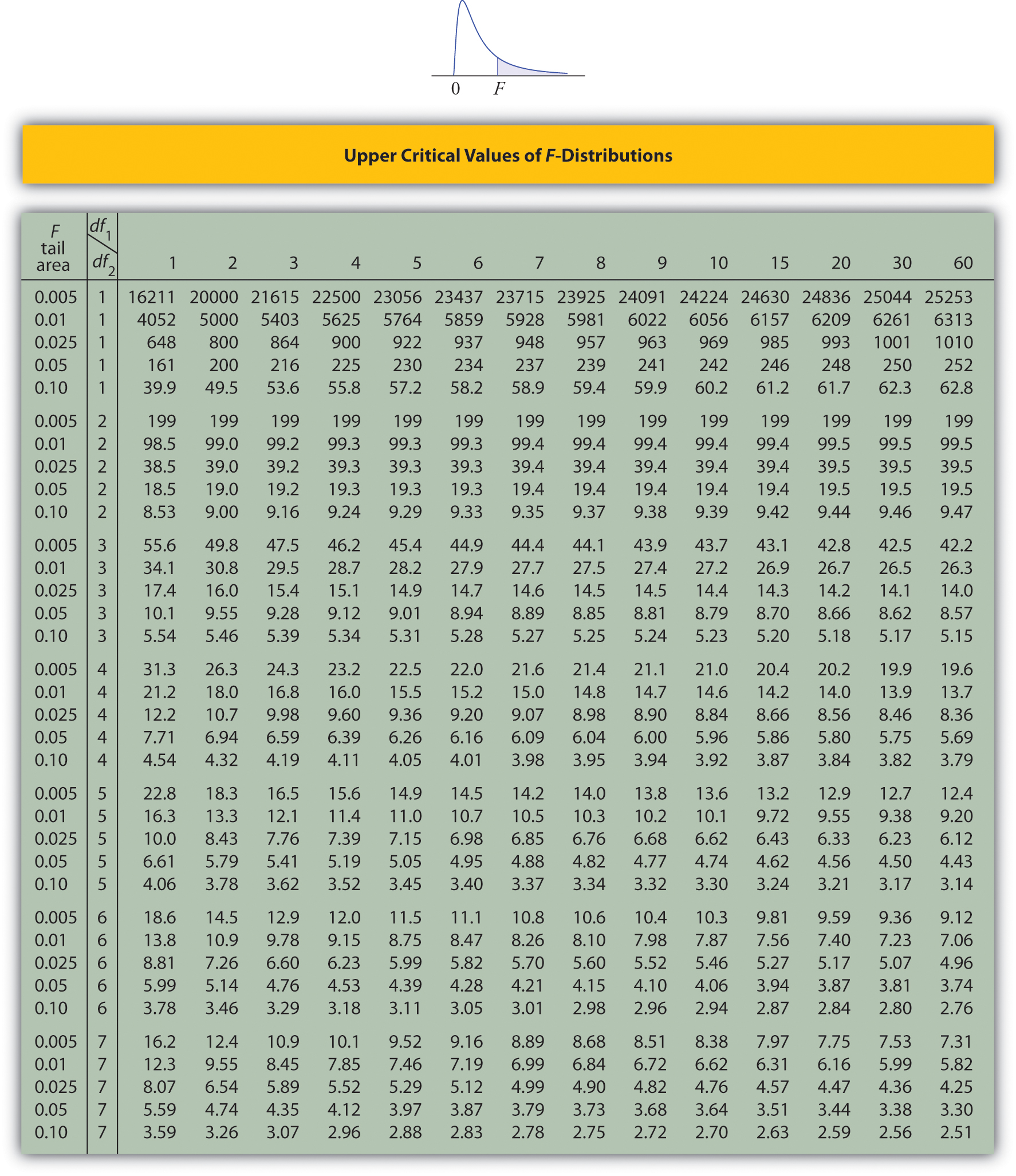
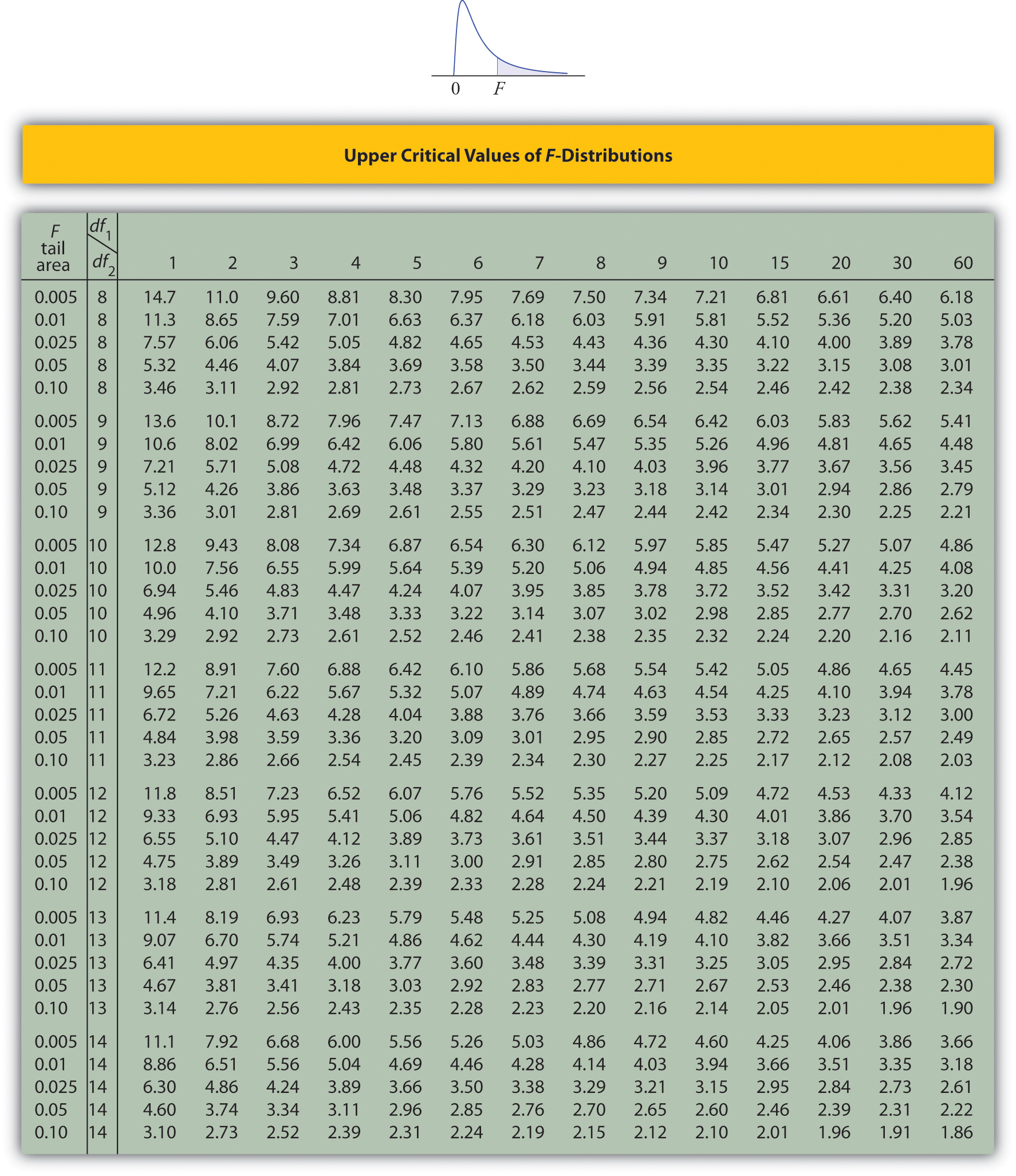
- The column headings of all the tables contain \(df_1=5\). Look for the table for which \(0.10\) is one of the entries on the extreme left (a table of upper critical values) and that has a row heading \(df_2=4\) in the left margin of the table. A portion of the relevant table is provided. The entry in the intersection of the column with heading \(df_1=5\) and the row with the headings \(0.10\) and \(df_2=4\), which is shaded in the table provided, is the answer, F0.10=4.05.
| \(F\) Tail Area | \(\frac{df_1}{df_2}\) | \(1\) | \(2\) | \(\cdots\) | \(5\) | \(\cdots\) |
|---|---|---|---|---|---|---|
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(0.005\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(22.5\) | \(\cdots\) |
| \(0.01\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(15.5\) | \(\cdots\) |
| \(0.025\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(9.36\) | \(\cdots\) |
| \(0.05\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(6.26\) | \(\cdots\) |
| \(0.10\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(4.05\) | \(\cdots\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
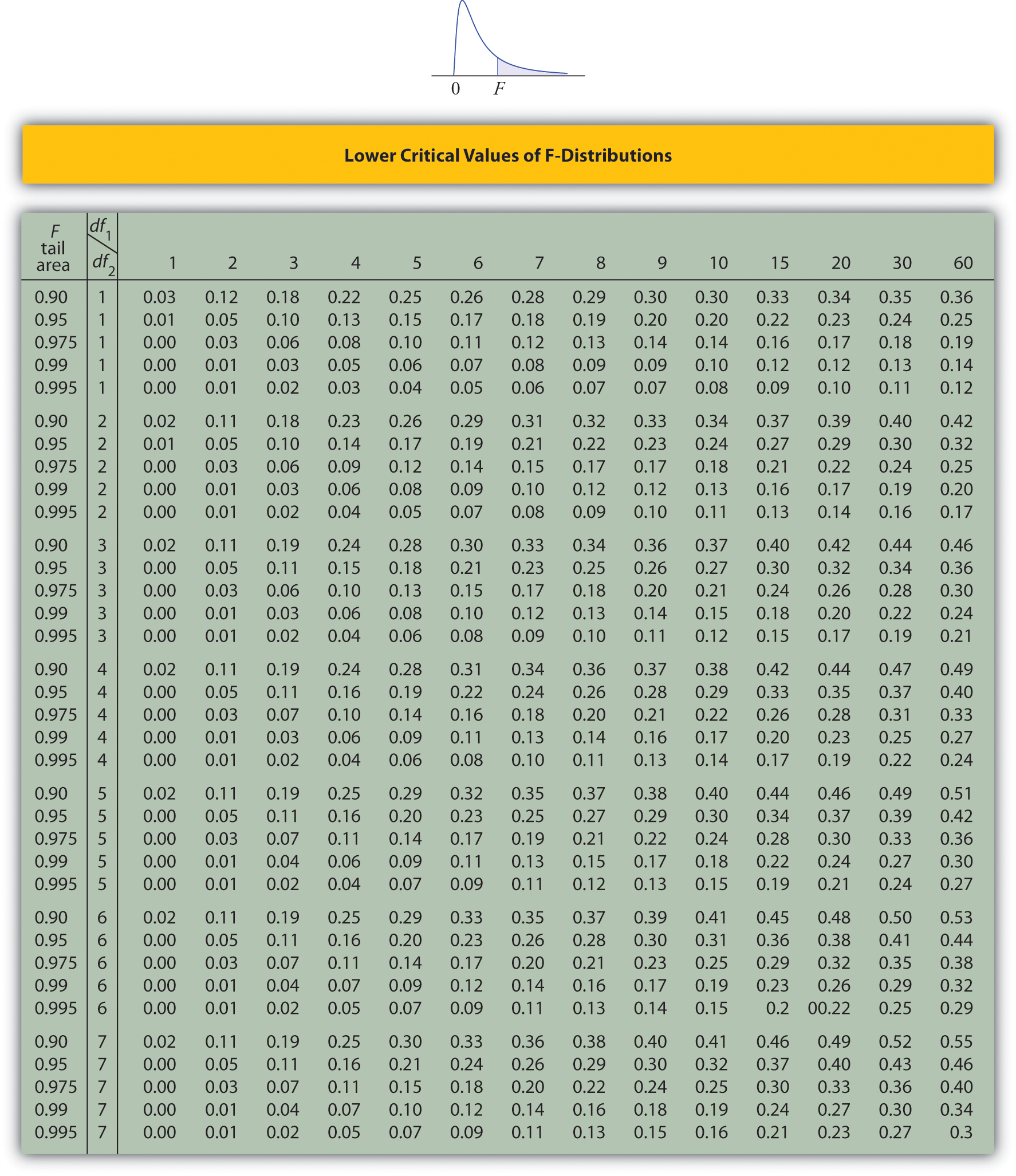
- Look for the table for which \(0.95\) is one of the entries on the extreme left (a table of lower critical values) and that has a row heading \(df_2=4\) in the left margin of the table. A portion of the relevant table is provided. The entry in the intersection of the column with heading \(df_1=5\) and the row with the headings \(0.95\) and \(df_2=4\), which is shaded in the table provided, is the answer, F0.95=0.19.
| \(F\) Tail Area | \(\frac{df_1}{df_2}\) | \(1\) | \(2\) | \(\cdots\) | \(5\) | \(\cdots\) |
|---|---|---|---|---|---|---|
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(0.90\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(0.28\) | \(\cdots\) |
| \(0.95\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(0.19\) | \(\cdots\) |
| \(0.975\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(0.14\) | \(\cdots\) |
| \(0.99\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(0.09\) | \(\cdots\) |
| \(0.995\) | \(4\) | \(\cdots\) | \(\cdots\) | \(\cdots\) | \(0.06\) | \(\cdots\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
Suppose \(F\) is an \(F\) random variable with degrees of freedom \(df_1=2\) and \(df_2=20\). Let \(α=0.05\). Use the tables to find
- \(F_{\alpha }\)
- \(F_{\alpha /2}\)
- \(F_{1-\alpha }\)
- \(F_{1-\alpha /2}\)
Solution
- The column headings of all the tables contain \(df_1=2\). Look for the table for which \(\alpha =0.05\) is one of the entries on the extreme left (a table of upper critical values) and that has a row heading \(df_2=20\) in the left margin of the table. A portion of the relevant table is provided. The shaded entry, in the intersection of the column with heading \(df_1=2\) and the row with the headings \(0.05\) and \(df_2=20\) is the answer, F0.05=3.49.
| \(F\) Tail Area | \(\frac{df_1}{df_2}\) | \(1\) | \(2\) | \(\cdots\) |
|---|---|---|---|---|
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(0.005\) | \(20\) | \(\cdots\) | \(6.99\) | \(\cdots\) |
| \(0.01\) | \(20\) | \(\cdots\) | \(5.85\) | \(\cdots\) |
| \(0.025\) | \(20\) | \(\cdots\) | \(4.46\) | \(\cdots\) |
| \(0.05\) | \(20\) | \(\cdots\) | \(3.49\) | \(\cdots\) |
| \(0.10\) | \(20\) | \(\cdots\) | \(2.59\) | \(\cdots\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
- Look for the table for which \(\alpha /2=0.025\) is one of the entries on the extreme left (a table of upper critical values) and that has a row heading \(df_2=20\) in the left margin of the table. A portion of the relevant table is provided. The shaded entry, in the intersection of the column with heading \(df_1=2\) and the row with the headings \(0.025\) and \(df_2=20\) is the answer, \(F_{0.025}=4.46\).
\(F\) Tail Area \(\frac{df_1}{df_2}\) \(1\) \(2\) \(\cdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(0.005\) \(20\) \(\cdots\) \(6.99\) \(\cdots\) \(0.01\) \(20\) \(\cdots\) \(5.85\) \(\cdots\) \(0.025\) \(20\) \(\cdots\) \(4.46\) \(\cdots\) \(0.05\) \(20\) \(\cdots\) \(3.49\) \(\cdots\) \(0.10\) \(20\) \(\cdots\) \(2.59\) \(\cdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\)
- Look for the table for which \(1-\alpha =0.95\) is one of the entries on the extreme left (a table of lower critical values) and that has a row heading \(df_2=20\) in the left margin of the table. A portion of the relevant table is provided. The shaded entry, in the intersection of the column with heading \(df_1=2\) and the row with the headings \(0.95\) and \(df_2=20\) is the answer, \(F_{0.95}=0.05\).
\(F\) Tail Area \(\frac{df_1}{df_2}\) \(1\) \(2\) \(\cdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(0.90\) \(20\) \(\cdots\) \(0.11\) \(\cdots\) \(0.95\) \(20\) \(\cdots\) \(0.05\) \(\cdots\) \(0.975\) \(20\) \(\cdots\) \(0.03\) \(\cdots\) \(0.99\) \(20\) \(\cdots\) \(0.01\) \(\cdots\) \(0.995\) \(20\) \(\cdots\) \(0.01\) \(\cdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\)
- Look for the table for which \(1-\alpha /2=0.975\) is one of the entries on the extreme left (a table of lower critical values) and that has a row heading \(df_2=20\) in the left margin of the table. A portion of the relevant table is provided. The shaded entry, in the intersection of the column with heading \(df_1=2\) and the row with the headings \(0.975\) and \(df_2=20\) is the answer, \(F_{0.975}=0.03\).
\(F\) Tail Area \(\frac{df_1}{df_2}\) \(1\) \(2\) \(\cdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(0.90\) \(20\) \(\cdots\) \(0.11\) \(\cdots\) \(0.95\) \(20\) \(\cdots\) \(0.05\) \(\cdots\) \(0.975\) \(20\) \(\cdots\) \(0.03\) \(\cdots\) \(0.99\) \(20\) \(\cdots\) \(0.01\) \(\cdots\) \(0.995\) \(20\) \(\cdots\) \(0.01\) \(\cdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\) \(\vdots\)
A fact that sometimes allows us to find a critical value from a table that we could not read otherwise is:
If \(F_u(r,s)\) denotes the value of the \(F\)-distribution with degrees of freedom \(df_1=r\) and \(df_2=s\) that cuts off a right tail of area \(u\), then
\[F_c(k,l)=\frac{1}{F_{1-c}(l,k)} \nonumber \]
Use the tables to find
- \(F_{0.01}\) for an \(F\) random variable with \(df_1=13\) and \(df_2=8\).
- \(F_{0.975}\) for an \(F\) random variable with \(df_1=40\) and \(df_2=10\).
Solution
- There is no table with \(df_1=13\), but there is one with \(df_1=8\). Thus we use the fact that \[F_{0.01}(13,8)=\frac{1}{F_{0.99}(8,13)} \nonumber \] Using the relevant table we find that \(F_{0.99}(8,13)=0.18\), hence \(F_{0.01}(13,8)=0.18^{-1}=5.556\).
- There is no table with \(df_1=40\), but there is one with \(df_1=10\). Thus we use the fact that \[F_{0.975}(40,10)=\frac{1}{F_{0.025}(10,40)} \nonumber \] Using the relevant table we find that \(F_{0.025}(10,40)=3.31\), hence \(F_{0.975}(40,10)=3.31^{-1}=0.302\).
\(F\)-Tests for Equality of Two Variances
In Chapter 9 we saw how to test hypotheses about the difference between two population means \(μ_1\) and \(μ_2\). In some practical situations the difference between the population standard deviations \(σ_1\) and \(σ_2\) is also of interest. Standard deviation measures the variability of a random variable. For example, if the random variable measures the size of a machined part in a manufacturing process, the size of standard deviation is one indicator of product quality. A smaller standard deviation among items produced in the manufacturing process is desirable since it indicates consistency in product quality.
For theoretical reasons it is easier to compare the squares of the population standard deviations, the population variances \(\sigma _{1}^{2}\) and \(\sigma _{2}^{2}\). This is not a problem, since \(σ_1=σ_2\) precisely when \(\sigma _{1}^{2}=\sigma _{2}^{2}\), \(σ_1<σ_2\) precisely when \(\sigma _{1}^{2}<\sigma _{2}^{2}\), and \(σ_1>σ_2\) precisely when \(\sigma _{1}^{2}>\sigma _{2}^{2}\).
The null hypothesis always has the form \(H_0: \sigma _{1}^{2}=\sigma _{2}^{2}\). The three forms of the alternative hypothesis, with the terminology for each case, are:
| Form of \(H_a\) | Terminology |
|---|---|
| \(H_a: \sigma _{1}^{2}>\sigma _{2}^{2}\) | Right-tailed |
| \(H_a: \sigma _{1}^{2}<\sigma _{2}^{2}\) | Left-tailed |
| \(H_a: \sigma _{1}^{2}\neq \sigma _{2}^{2}\) | Two-tailed |
Just as when we test hypotheses concerning two population means, we take a random sample from each population, of sizes \(n_1\) and \(n_2\), and compute the sample standard deviations \(s_1\) and \(s_2\). In this context the samples are always independent. The populations themselves must be normally distributed.
\[F=\frac{s_{1}^{2}}{s_{2}^{2}} \nonumber \]
If the two populations are normally distributed and if \(H_0: \sigma _{1}^{2}=\sigma _{2}^{2}\) is true then under independent sampling \(F\) approximately follows an \(F\)-distribution with degrees of freedom \(df_1=n_1-1\) and \(df_2=n_2-1\).
A test based on the test statistic \(F\) is called an \(F\)-test.
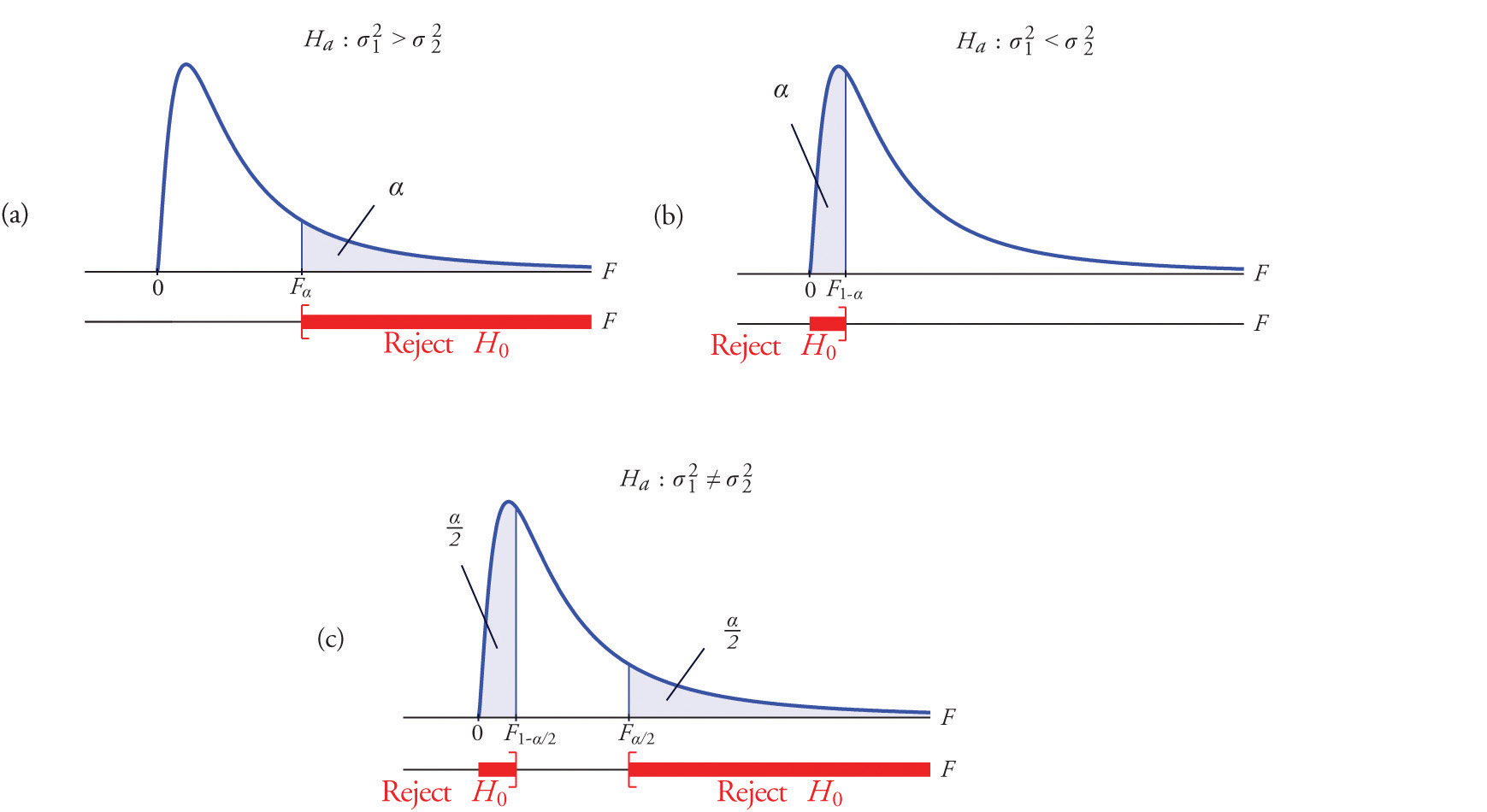
A most important point is that while the rejection region for a right-tailed test is exactly as in every other situation that we have encountered, because of the asymmetry in the \(F\)-distribution the critical value for a left-tailed test and the lower critical value for a two-tailed test have the special forms shown in the following table:
| Terminology | Alternative Hypothesis | Rejection Region |
|---|---|---|
| Right-tailed | \(H_a: \sigma _{1}^{2}>\sigma _{2}^{2}\) | \(F\geq F_\alpha\) |
| Left-tailed | \(H_a: \sigma _{1}^{2}<\sigma _{2}^{2}\) | \(F\leq F_{1-\alpha }\) |
| Two-tailed | \(H_a: \sigma _{1}^{2}\neq \sigma _{2}^{2}\) | \(F\leq F_{1-\alpha /2}\; \text{or}\; F\geq F_{\alpha /2}\) |
Figure \(\PageIndex{3}\) illustrates these rejection regions.
The test is performed using the usual five-step procedure described at the end of Section 8.1.
One of the quality measures of blood glucose meter strips is the consistency of the test results on the same sample of blood. The consistency is measured by the variance of the readings in repeated testing. Suppose two types of strips, \(A\) and \(B\), are compared for their respective consistencies. We arbitrarily label the population of Type \(A\) strips Population \(1\) and the population of Type \(B\) strips Population \(2\). Suppose \(15\) Type \(A\) strips were tested with blood drops from a well-shaken vial and \(20\) Type \(B\) strips were tested with the blood from the same vial. The results are summarized in Table \(\PageIndex{3}\). Assume the glucose readings using Type \(A\) strips follow a normal distribution with variance \(\sigma _{1}^{2}\)and those using Type \(B\) strips follow a normal distribution with variance with \(\sigma _{2}^{2}\). Test, at the \(10\%\) level of significance, whether the data provide sufficient evidence to conclude that the consistencies of the two types of strips are different.
| Strip Type | Sample Size | Sample Variance |
|---|---|---|
| \(A\) | \(n_1=16\) | \(s_{1}^{2}=2.09\) |
| \(B\) | \(n_2=21\) | \(s_{2}^{2}=1.10\) |
Solution
- Step 1. The test of hypotheses is \[H_0: \sigma _{1}^{2}=\sigma _{2}^{2}\\ vs.\\ H_a: \sigma _{1}^{2}\neq \sigma _{2}^{2}\; @\; \alpha =0.10 \nonumber \]
- Step 2. The distribution is the \(F\)-distribution with degrees of freedom \(df_1=16-1=15\) and \(df_2=21-1=20\).
- Step 3. The test is two-tailed. The left or lower critical value is \(F_{1-\alpha }=F_{0.95}=0.43\). The right or upper critical value is \(F_{\alpha /2}=F_{0.05}=2.20\). Thus the rejection region is \([0,-0.43]\cup [2.20,\infty )\), as illustrated in Figure \(\PageIndex{4}\).
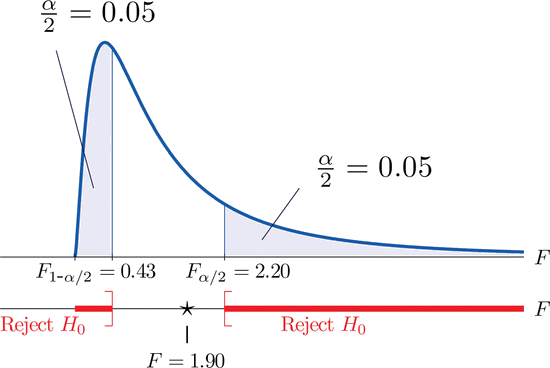
- Step 4. The value of the test statistic is \[F=\frac{s_{1}^{2}}{s_{2}^{2}}=\frac{2.09}{1.10}=1.90 \nonumber \]
- Step 5. As shown in Figure \(\PageIndex{4}\), the test statistic \(1.90\) does not lie in the rejection region, so the decision is not to reject \(H_0\). The data do not provide sufficient evidence, at the \(10\%\) level of significance, to conclude that there is a difference in the consistency, as measured by the variance, of the two types of test strips.
In the context of "Example \(\PageIndex{4}\)", suppose Type \(A\) test strips are the current market leader and Type \(B\) test strips are a newly improved version of Type \(A\). Test, at the \(10\%\) level of significance, whether the data given in Table \(\PageIndex{3}\) provide sufficient evidence to conclude that Type \(B\) test strips have better consistency (lower variance) than Type \(A\) test strips.
Solution
- Step 1. The test of hypotheses is now \[H_0: \sigma _{1}^{2}=\sigma _{2}^{2}\\ vs.\\ H_a: \sigma _{1}^{2}>\sigma _{2}^{2}\; @\; \alpha =0.10 \nonumber \]
- Step 2. The distribution is the \(F\)-distribution with degrees of freedom \(df_1=16-1=15\) and \(df_2=21-1=20\).
- Step 3. The value of the test statistic is \[F=\frac{s_{1}^{2}}{s_{2}^{2}}=\frac{2.09}{1.10}=1.90 \nonumber \]
- Step 4. The test is right-tailed. The single critical value is \(F_\alpha =F_{0.10}=1.84\). Thus the rejection region is \([1.84,\infty )\), as illustrated in Figure \(\PageIndex{5}\).
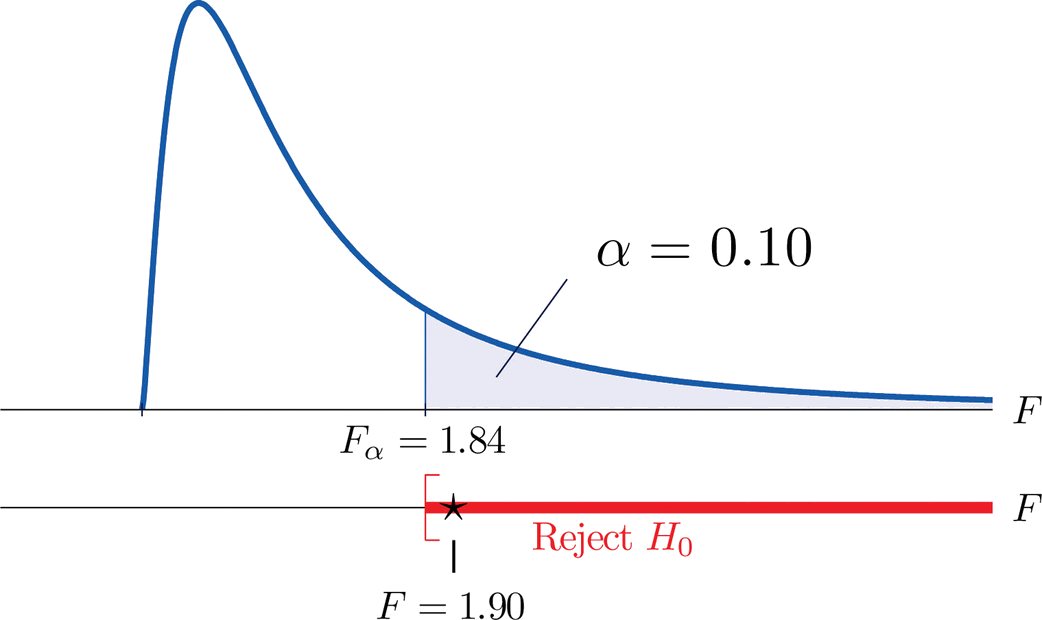
- Step 5. As shown in Figure \(\PageIndex{5}\), the test statistic \(1.90\) lies in the rejection region, so the decision is to reject \(H_0\) The data provide sufficient evidence, at the \(10\%\) level of significance, to conclude that Type \(B\) test strips have better consistency (lower variance) than Type \(A\) test strips do.
Upper Critical Values of \(F\)-Distributions

Lower Critical Values of \(F\)-Distributions
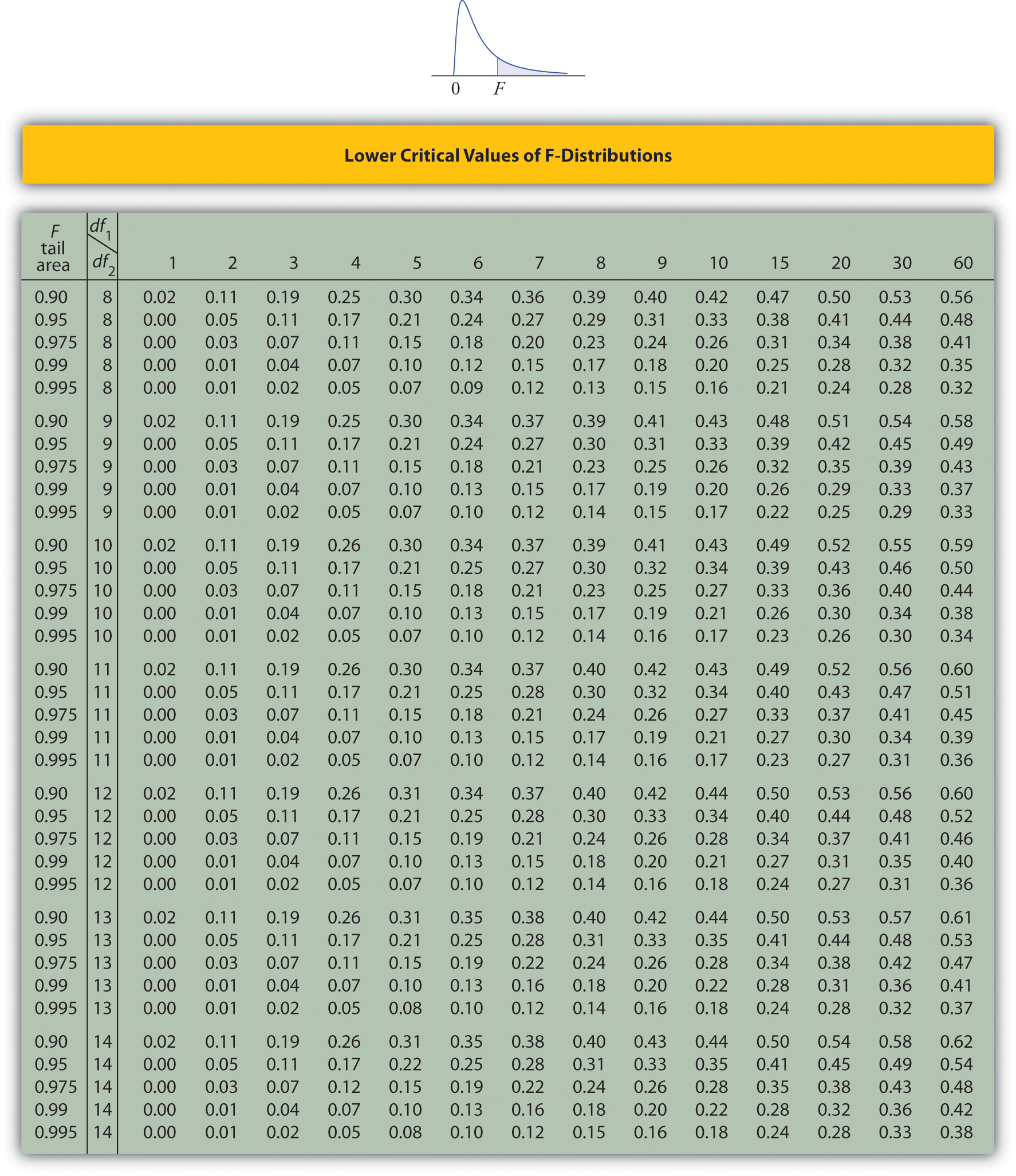
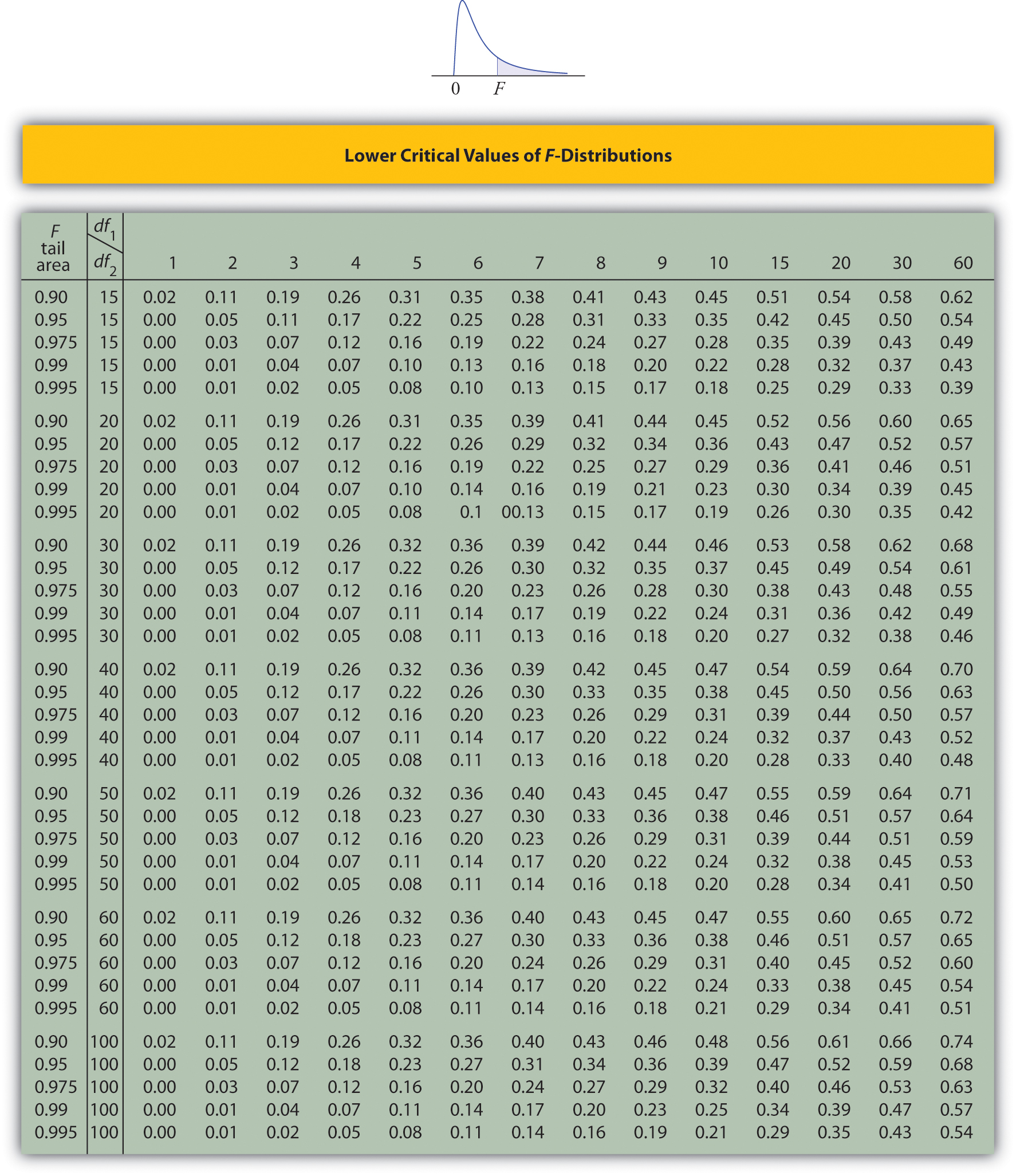
- Critical values of an \(F\)-distribution with degrees of freedom \(df_1\) and \(df_2\) are found in tables above.
- An \(F\)-test can be used to evaluate the hypothesis of two identical normal population variances.