
4.5: Examining the Central Limit Theorem
- Page ID
- 281

The normal model for the sample mean tends to be very good when the sample consists of at least 30 independent observations and the population data are not strongly skewed. The Central Limit Theorem provides the theory that allows us to make this assumption.
Central Limit Theorem - informal definition
The distribution of \(\bar {x}\) is approximately normal. The approximation can be poor if the sample size is small, but it improves with larger sample sizes.
The Central Limit Theorem states that when the sample size is small, the normal approximation may not be very good. However, as the sample size becomes large, the normal approximation improves. We will investigate three cases to see roughly when the approximation is reasonable.
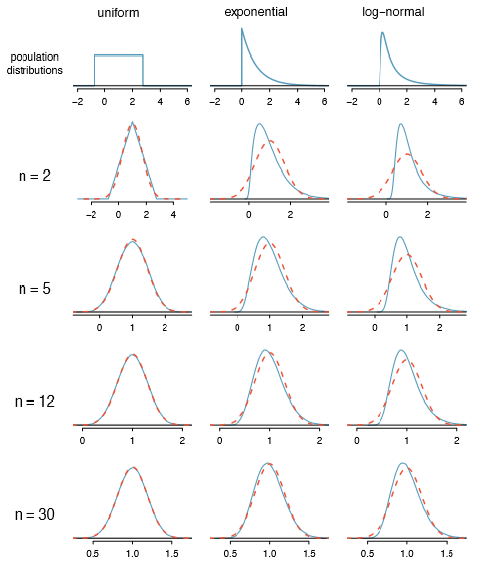
We consider three data sets: one from a uniform distribution, one from an exponential distribution, and the other from a log-normal distribution. These distributions are shown in the top panels of Figure 4.20. The uniform distribution is symmetric, the exponential distribution may be considered as having moderate skew since its right tail is relatively short (few outliers), and the log-normal distribution is strongly skewed and will tend to produce more apparent outliers.
The left panel in the n = 2 row represents the sampling distribution of \(\bar {x}\) if it is the sample mean of two observations from the uniform distribution shown. The dashed line represents the closest approximation of the normal distribution. Similarly, the center and right panels of the n = 2 row represent the respective distributions of \(\bar {x}\) for data from exponential and log-normal distributions.
31Here the null hypothesis is that the part is not broken, and the alternative is that it is broken. If we don't have sufficient evidence to reject H0, we would not replace the part. It sounds like failing to x the part if it is broken (H0 false, HA true) is not very problematic, and replacing the part is expensive. Thus, we should require very strong evidence against H0 before we replace the part. Choose a small significance level, such as \(\alpha = 0.01\).
32The normal approximation becomes better as larger samples are used.
Exercise
Exercise 4.41 Examine the distributions in each row of Figure 4.20. What do you notice about the normal approximation for each sampling distribution as the sample size becomes larger?33
Exercise
Example 4.42 Would the normal approximation be good in all applications where the sample size is at least 30?
Not necessarily. For example, the normal approximation for the log-normal example is questionable for a sample size of 30. Generally, the more skewed a population distribution or the more common the frequency of outliers, the larger the sample required to guarantee the distribution of the sample mean is nearly normal.
TIP: With larger n, the sampling distribution of \(\bar {x}\) becomes more normal
As the sample size increases, the normal model for \(\bar {x}\) becomes more reasonable. We can also relax our condition on skew when the sample size is very large.
We discussed in Section 4.1.3 that the sample standard deviation, s, could be used as a substitute of the population standard deviation, \(\sigma\), when computing the standard error. This estimate tends to be reasonable when \(n \le 30\). We will encounter alternative distributions for smaller sample sizes in Chapters 5 and 6.
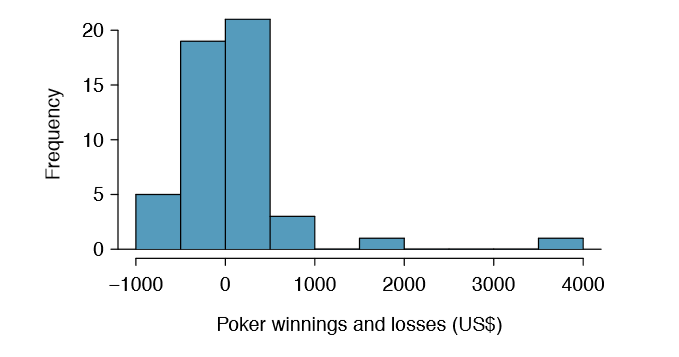
Example 4.43 Figure 4.21 shows a histogram of 50 observations. These represent winnings and losses from 50 consecutive days of a professional poker player. Can the normal approximation be applied to the sample mean, 90.69?
We should consider each of the required conditions.
- These are referred to as time series data, because the data arrived in a particular sequence. If the player wins on one day, it may inuence how she plays the next. To make the assumption of independence we should perform careful checks on such data. While the supporting analysis is not shown, no evidence was found to indicate the observations are not independent.
- The sample size is 50, satisfying the sample size condition.
- There are two outliers, one very extreme, which suggests the data are very strongly skewed or very distant outliers may be common for this type of data. Outliers can play an important role and affect the distribution of the sample mean and the estimate of the standard error.
Since we should be skeptical of the independence of observations and the very extreme upper outlier poses a challenge, we should not use the normal model for the sample mean of these 50 observations. If we can obtain a much larger sample, perhaps several hundred observations, then the concerns about skew and outliers would no longer apply.
Caution: Examine data structure when considering independence
Some data sets are collected in such a way that they have a natural underlying structure between observations, e.g. when observations occur consecutively. Be especially cautious about independence assumptions regarding such data sets.
Caution: Watch out for strong skew and outliers
Strong skew is often identi ed by the presence of clear outliers. If a data set has prominent outliers, or such observations are somewhat common for the type of data under study, then it is useful to collect a sample with many more than 30 observations if the normal model will be used for \(\bar {x}\). There are no simple guidelines for what sample size is big enough for all situations, so proceed with caution when working in the presence of strong skew or more extreme outliers.
You won’t be a pro at assessing skew by the end of this book, so just use your best judgement and continue learning. As you develop your statistics skills and encounter tough situations, also consider learning about better ways to analyze skewed data, such as the studentized bootstrap (bootstrap-t), or consult a more experienced statistician.