
6.6: Additional Information and Full Hypothesis Test Examples
- Page ID
- 5954

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)- In a hypothesis test problem, you may see words such as "the level of significance is 1%." The "1%" is the preconceived or preset \(\alpha\).
- The statistician setting up the hypothesis test selects the value of α to use before collecting the sample data.
- If no level of significance is given, a common standard to use is \(\alpha = 0.05\).
- When you calculate the \(p\)-value and draw the picture, the \(p\)-value is the area in the left tail, the right tail, or split evenly between the two tails. For this reason, we call the hypothesis test left, right, or two tailed.
- The alternative hypothesis, \(H_{a}\), tells you if the test is left, right, or two-tailed. It is the key to conducting the appropriate test.
- \(H_{a}\) never has a symbol that contains an equal sign.
- Thinking about the meaning of the \(p\)-value: A data analyst (and anyone else) should have more confidence that he made the correct decision to reject the null hypothesis with a smaller \(p\)-value (for example, 0.001 as opposed to 0.04) even if using the 0.05 level for alpha. Similarly, for a large p-value such as 0.4, as opposed to a \(p\)-value of 0.056 (\(\alpha = 0.05\) is less than either number), a data analyst should have more confidence that she made the correct decision in not rejecting the null hypothesis. This makes the data analyst use judgment rather than mindlessly applying rules.
The following examples illustrate a left-, right-, and two-tailed test.
\(H_{0}: \mu = 5, H_{a}: \mu < 5\)
Test of a single population mean. \(H_{a}\) tells you the test is left-tailed. The picture of the \(p\)-value is as follows:

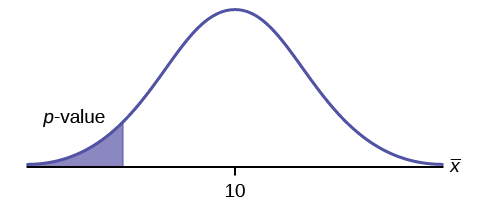
\(H_{0}: \mu = 10, H_{a}: \mu < 10\)
Assume the \(p\)-value is 0.0935. What type of test is this? Draw the picture of the \(p\)-value.
Answer
left-tailed test
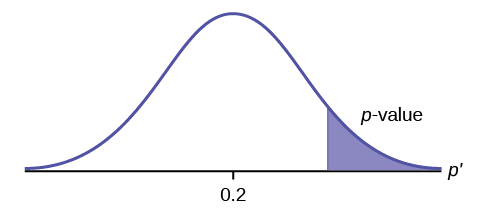
\(H_{0}: \mu \leq 0.2, H_{a}: \mu > 0.2\)
This is a test of a single population proportion. \(H_{a}\) tells you the test is right-tailed. The picture of the p-value is as follows:
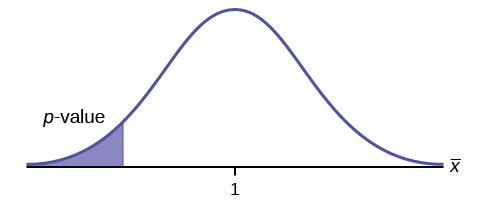
\(H_{0}: \mu \leq 1, H_{a}: \mu > 1\)
Assume the \(p\)-value is 0.1243. What type of test is this? Draw the picture of the \(p\)-value.
Answer
right-tailed test
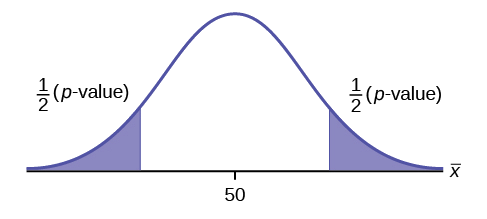
\(H_{0}: \mu = 50, H_{a}: \mu \neq 50\)
This is a test of a single population mean. \(H_{a}\) tells you the test is two-tailed. The picture of the \(p\)-value is as follows.
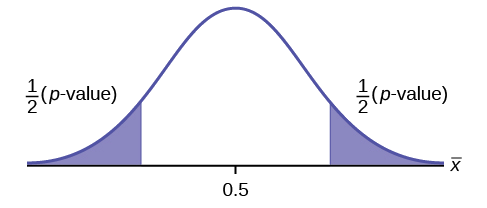
\(H_{0}: \mu = 0.5, H_{a}: \mu \neq 0.5\)
Assume the p-value is 0.2564. What type of test is this? Draw the picture of the \(p\)-value.
Answer
two-tailed test
Full Hypothesis Test Examples
Jeffrey, as an eight-year old, established a mean time of 16.43 seconds for swimming the 25-yard freestyle, with a standard deviation of 0.8 seconds. His dad, Frank, thought that Jeffrey could swim the 25-yard freestyle faster using goggles. Frank bought Jeffrey a new pair of expensive goggles and timed Jeffrey for 15 25-yard freestyle swims. For the 15 swims, Jeffrey's mean time was 16 seconds. Frank thought that the goggles helped Jeffrey to swim faster than the 16.43 seconds.Conduct a hypothesis test using a preset α = 0.05. Assume that the swim times for the 25-yard freestyle are normal.
Answer
Set up the Hypothesis Test:
Since the problem is about a mean, this is a test of a single population mean.
\(H_{0}: \mu = 16.43, H_{a}: \mu < 16.43\)
For Jeffrey to swim faster, his time will be less than 16.43 seconds. The "\(<\)" tells you this is left-tailed.
Determine the distribution needed:
Random variable: \(\bar{X} =\) the mean time to swim the 25-yard freestyle.
Distribution for the test: \(\bar{X}\) is normal (population standard deviation is known: \(\sigma = 0.8\))
\(\bar{X} - N \left(\mu, \frac{\sigma_{x}}{\sqrt{n}}\right)\) Therefore, \(\bar{X} - N\left(16.43, \frac{0.8}{\sqrt{15}}\right)\)
\(\mu = 16.43\) comes from \(H_{0}\) and not the data. \(\sigma = 0.8\), and \(n = 15\).
Calculate the \(p-\text{value}\) using the normal distribution for a mean:
\(p\text{-value} = P(\bar{x} < 16) = 0.0187\) where the sample mean in the problem is given as 16.
\(p\text{-value} = 0.0187\) (This is called the actual level of significance.) The \(p-\text{value}\) is the area to the left of the sample mean is given as 16.
Graph:
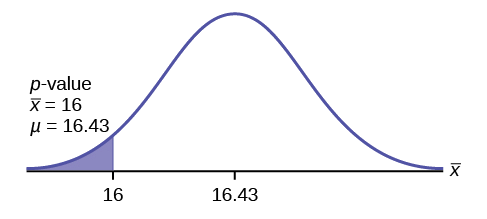
\(\mu = 16.43\) comes from \(H_{0}\). Our assumption is \(\mu = 16.43\).
Interpretation of the \(p-\text{value}\): If \(H_{0}\) is true, there is a 0.0187 probability (1.87%) that Jeffrey's mean time to swim the 25-yard freestyle is 16 seconds or less. Because a 1.87% chance is small, the mean time of 16 seconds or less is unlikely to have happened randomly. It is a rare event.
Compare \(\alpha\) and the \(p-\text{value}\):
\(\alpha = 0.05 p\text{-value} = 0.0187 \alpha > p\text{-value}\)
Make a decision: Since \(\alpha > p\text{-value}\), reject \(H_{0}\).
This means that you reject \(\mu = 16.43\). In other words, you do not think Jeffrey swims the 25-yard freestyle in 16.43 seconds but faster with the new goggles.
Conclusion: At the 5% significance level, we conclude that Jeffrey swims faster using the new goggles. The sample data show there is sufficient evidence that Jeffrey's mean time to swim the 25-yard freestyle is less than 16.43 seconds.
The p-value can easily be calculated.
Press STAT and arrow over to TESTS. Press 1:Z-Test. Arrow over to Statsand press ENTER. Arrow down and enter 16.43 for \(\mu_{0}\) (null hypothesis), .8 for σ, 16 for the sample mean, and 15 for n. Arrow down to \(\mu\) : (alternate hypothesis) and arrow over to \(< \mu_{0}\). Press ENTER. Arrow down to Calculateand press ENTER. The calculator not only calculates the p-value (\(p = 0.0187\)) but it also calculates the test statistic (z-score) for the sample mean. \(\mu < 16.43\) is the alternative hypothesis. Do this set of instructions again except arrow toDraw(instead of Calculate). Press ENTER. A shaded graph appears with \(z = -2.08\) (test statistic) and \(p = 0.0187\) (\(p-\text{value}\)). Make sure when you use Drawthat no other equations are highlighted in \(Y =\) and the plots are turned off.
When the calculator does a \(Z\)-Test, the Z-Test function finds the p-value by doing a normal probability calculation using the central limit theorem:
\(P(\bar{X} < 16)\) 2nd DISTR normcdf (\((−10^{99},16,16.43,\frac{0.8}{\sqrt{15}})\).
The Type I and Type II errors for this problem are as follows:
The Type I error is to conclude that Jeffrey swims the 25-yard freestyle, on average, in less than 16.43 seconds when, in fact, he actually swims the 25-yard freestyle, on average, in 16.43 seconds. (Reject the null hypothesis when the null hypothesis is true.)
The Type II error is that there is not evidence to conclude that Jeffrey swims the 25-yard free-style, on average, in less than 16.43 seconds when, in fact, he actually does swim the 25-yard free-style, on average, in less than 16.43 seconds. (Do not reject the null hypothesis when the null hypothesis is false.)
The mean throwing distance of a football for a Marco, a high school freshman quarterback, is 40 yards, with a standard deviation of two yards. The team coach tells Marco to adjust his grip to get more distance. The coach records the distances for 20 throws. For the 20 throws, Marco’s mean distance was 45 yards. The coach thought the different grip helped Marco throw farther than 40 yards. Conduct a hypothesis test using a preset \(\alpha = 0.05\). Assume the throw distances for footballs are normal.
First, determine what type of test this is, set up the hypothesis test, find the p-value, sketch the graph, and state your conclusion.
Press STAT and arrow over to TESTS. Press 1: \(Z\)-Test. Arrow over to Stats and press ENTER. Arrow down and enter 40 for \(\mu_{0}\) (null hypothesis), 2 for \(\sigma\), 45 for the sample mean, and 20 for \(n\). Arrow down to \(\mu\): (alternative hypothesis) and set it either as \(<\), \(\neq\), or \(>\). Press ENTER. Arrow down to Calculate and press ENTER. The calculator not only calculates the p-value but it also calculates the test statistic (z-score) for the sample mean. Select \(<\), \(\neq\), or \(>\) for the alternative hypothesis. Do this set of instructions again except arrow to Draw (instead of Calculate). Press ENTER. A shaded graph appears with test statistic and \(p\)-value. Make sure when you use Draw that no other equations are highlighted in \(Y =\) and the plots are turned off.
Answer
Since the problem is about a mean, this is a test of a single population mean.
- \(H_{0}: \mu = 40\)
- \(H_{a}: \mu > 40\)
- \(p = 0.0062\)
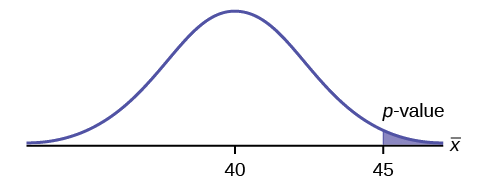
Because \(p < \alpha\), we reject the null hypothesis. There is sufficient evidence to suggest that the change in grip improved Marco’s throwing distance.
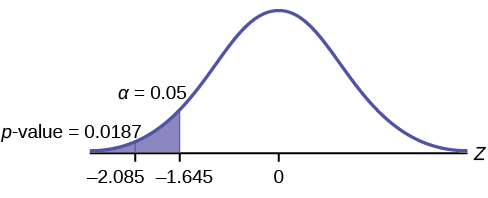
The traditional way to compare the two probabilities, \(\alpha\) and the \(p-\text{value}\), is to compare the critical value (\(z\)-score from \(\alpha\)) to the test statistic (\(z\)-score from data). The calculated test statistic for the \(p\)-value is –2.08. (From the Central Limit Theorem, the test statistic formula is \(z = \frac{\bar{x}-\mu_{x}}{\left(\frac{\sigma_{x}}{\sqrt{n}}\right)}\). For this problem, \(\bar{x} = 16\), \(\mu_{x} = 16.43\) from the null hypotheses is, \(\sigma_{x} = 0.8\), and \(n = 15\).) You can find the critical value for \(\alpha = 0.05\) in the normal table (see 15.Tables in the Table of Contents). The \(z\)-score for an area to the left equal to 0.05 is midway between –1.65 and –1.64 (0.05 is midway between 0.0505 and 0.0495). The \(z\)-score is –1.645. Since –1.645 > –2.08 (which demonstrates that \(\alpha > p-\text{value}\)), reject \(H_{0}\). Traditionally, the decision to reject or not reject was done in this way. Today, comparing the two probabilities \(\alpha\) and the \(p\)-value is very common. For this problem, the \(p-\text{value}\), 0.0187 is considerably smaller than \(\alpha = 0.05\). You can be confident about your decision to reject. The graph shows \(\alpha\), the \(p-\text{value}\), and the test statistics and the critical value.
A college football coach thought that his players could bench press a mean weight of 275 pounds. It is known that the standard deviation is 55 pounds. Three of his players thought that the mean weight was more than that amount. They asked 30 of their teammates for their estimated maximum lift on the bench press exercise. The data ranged from 205 pounds to 385 pounds. The actual different weights were (frequencies are in parentheses) 205(3); 215(3); 225(1); 241(2); 252(2); 265(2); 275(2); 313(2); 316(5); 338(2); 341(1); 345(2); 368(2); 385(1).
Conduct a hypothesis test using a 2.5% level of significance to determine if the bench press mean is more than 275 pounds.
Answer
Set up the Hypothesis Test:
Since the problem is about a mean weight, this is a test of a single population mean.
- \(H_{0}: \mu = 275\)
- \(H_{a}: \mu > 275\)
This is a right-tailed test.
Calculating the distribution needed:
Random variable: \(\bar{X} =\) the mean weight, in pounds, lifted by the football players.
Distribution for the test: It is normal because \(\sigma\) is known.
- \(\bar{X} - N\left(275, \frac{55}{\sqrt{30}}\right)\)
- \(\bar{x} = 286.2\) pounds (from the data).
- \(\sigma = 55\) pounds (Always use \(\sigma\) if you know it.) We assume \(\mu = 275\) pounds unless our data shows us otherwise.
Calculate the p-value using the normal distribution for a mean and using the sample mean as input (see [link] for using the data as input):
\[p\text{-value} = P(\bar{x} > 286.2) = 0.1323.\nonumber \]
Interpretation of the p-value: If \(H_{0}\) is true, then there is a 0.1331 probability (13.23%) that the football players can lift a mean weight of 286.2 pounds or more. Because a 13.23% chance is large enough, a mean weight lift of 286.2 pounds or more is not a rare event.
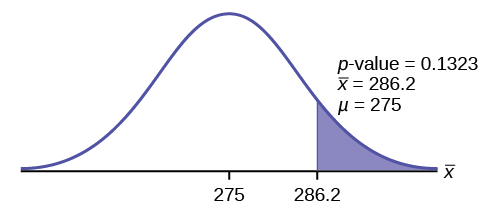
Compare \(\alpha\) and the \(p-\text{value}\):
\(\alpha = 0.025 p-value = 0.1323\)
Make a decision: Since \(\alpha < p\text{-value}\), do not reject \(H_{0}\).
Conclusion: At the 2.5% level of significance, from the sample data, there is not sufficient evidence to conclude that the true mean weight lifted is more than 275 pounds.
The \(p-\text{value}\) can easily be calculated.
Put the data and frequencies into lists. Press STAT and arrow over to TESTS. Press 1:Z-Test. Arrow over to Data and press ENTER. Arrow down and enter 275 for \(\mu_{0}\), 55 for \(\sigma\), the name of the list where you put the data, and the name of the list where you put the frequencies. Arrow down to \(\mu\): and arrow over to \(> \mu_{0}\). Press ENTER. Arrow down to Calculate and press ENTER. The calculator not only calculates the \(p-\text{value}\) (\(p = 0.1331\)), a little different from the previous calculation - in it we used the sample mean rounded to one decimal place instead of the data) but it also calculates the test statistic (z-score) for the sample mean, the sample mean, and the sample standard deviation. \(\mu > 275\) is the alternative hypothesis. Do this set of instructions again except arrow toDraw (instead of Calculate). Press ENTER. A shaded graph appears with \(z = 1.112\) (test statistic) and \(p = 0.1331\) (\(p-\text{value})\). Make sure when you use Drawthat no other equations are highlighted in \(Y =\) and the plots are turned off.
Statistics students believe that the mean score on the first statistics test is 65. A statistics instructor thinks the mean score is higher than 65. He samples ten statistics students and obtains the scores 65 65 70 67 66 63 63 68 72 71. He performs a hypothesis test using a 5% level of significance. The data are assumed to be from a normal distribution.
Answer
Set up the hypothesis test:
A 5% level of significance means that \(\alpha = 0.05\). This is a test of a single population mean.
\(H_{0}: \mu = 65 H_{a}: \mu > 65\)
Since the instructor thinks the average score is higher, use a "\(>\)". The "\(>\)" means the test is right-tailed.
Determine the distribution needed:
Random variable: \(\bar{X} =\) average score on the first statistics test.
Distribution for the test: If you read the problem carefully, you will notice that there is no population standard deviation given. You are only given \(n = 10\) sample data values. Notice also that the data come from a normal distribution. This means that the distribution for the test is a student's \(t\).
Use \(t_{df}\). Therefore, the distribution for the test is \(t_{9}\) where \(n = 10\) and \(df = 10 - 1 = 9\).
Calculate the \(p\)-value using the Student's \(t\)-distribution:
\(p\text{-value} = P(\bar{x} > 67) = 0.0396\) where the sample mean and sample standard deviation are calculated as 67 and 3.1972 from the data.
Interpretation of the p-value: If the null hypothesis is true, then there is a 0.0396 probability (3.96%) that the sample mean is 65 or more.
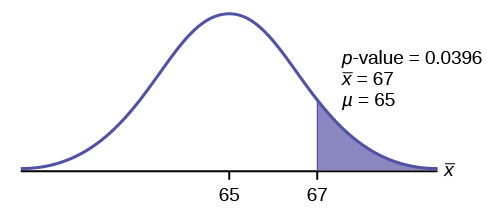
Compare \(\alpha\) and the \(p-\text{value}\):
Since \(α = 0.05\) and \(p\text{-value} = 0.0396\). \(\alpha > p\text{-value}\).
Make a decision: Since \(\alpha > p\text{-value}\), reject \(H_{0}\).
This means you reject \(\mu = 65\). In other words, you believe the average test score is more than 65.
Conclusion: At a 5% level of significance, the sample data show sufficient evidence that the mean (average) test score is more than 65, just as the math instructor thinks.
The \(p\text{-value}\) can easily be calculated.
Put the data into a list. Press STAT and arrow over to TESTS. Press 2:T-Test. Arrow over to Data and press ENTER. Arrow down and enter 65 for \(\mu_{0}\), the name of the list where you put the data, and 1 for Freq:. Arrow down to \(\mu\): and arrow over to \(> \mu_{0}\). Press ENTER. Arrow down to Calculate and pressENTER. The calculator not only calculates the \(p\text{-value}\) (p = 0.0396) but it also calculates the test statistic (t-score) for the sample mean, the sample mean, and the sample standard deviation. \(\mu > 65\) is the alternative hypothesis. Do this set of instructions again except arrow to Draw (instead of Calculate). Press ENTER. A shaded graph appears with \(t = 1.9781\) (test statistic) and \(p = 0.0396\) (\(p\text{-value}\)). Make sure when you use Draw that no other equations are highlighted in \(Y =\) and the plots are turned off.
It is believed that a stock price for a particular company will grow at a rate of $5 per week with a standard deviation of $1. An investor believes the stock won’t grow as quickly. The changes in stock price is recorded for ten weeks and are as follows: $4, $3, $2, $3, $1, $7, $2, $1, $1, $2. Perform a hypothesis test using a 5% level of significance. State the null and alternative hypotheses, find the p-value, state your conclusion, and identify the Type I and Type II errors.
Answer
- \(H_{0}: \mu = 5\)
- \(H_{a}: \mu < 5\)
- \(p = 0.0082\)
Because \(p < \alpha\), we reject the null hypothesis. There is sufficient evidence to suggest that the stock price of the company grows at a rate less than $5 a week.
- Type I Error: To conclude that the stock price is growing slower than $5 a week when, in fact, the stock price is growing at $5 a week (reject the null hypothesis when the null hypothesis is true).
- Type II Error: To conclude that the stock price is growing at a rate of $5 a week when, in fact, the stock price is growing slower than $5 a week (do not reject the null hypothesis when the null hypothesis is false).
Joon believes that 50% of first-time brides in the United States are younger than their grooms. She performs a hypothesis test to determine if the percentage is the same or different from 50%. Joon samples 100 first-time brides and 53 reply that they are younger than their grooms. For the hypothesis test, she uses a 1% level of significance.
Answer
Set up the hypothesis test:
The 1% level of significance means that α = 0.01. This is a test of a single population proportion.
\(H_{0}: p = 0.50\) \(H_{a}: p \neq 0.50\)
The words "is the same or different from" tell you this is a two-tailed test.
Calculate the distribution needed:
Random variable: \(P′ =\) the percent of of first-time brides who are younger than their grooms.
Distribution for the test: The problem contains no mention of a mean. The information is given in terms of percentages. Use the distribution for P′, the estimated proportion.
\[P' - N\left(p, \sqrt{\frac{p-q}{n}}\right)\nonumber \]
Therefore,
\[P' - N\left(0.5, \sqrt{\frac{0.5-0.5}{100}}\right)\nonumber \]
where \(p = 0.50, q = 1−p = 0.50\), and \(n = 100\)
Calculate the p-value using the normal distribution for proportions:
\[p\text{-value} = P(p′ < 0.47 \space or \space p′ > 0.53) = 0.5485\nonumber \]
where \[x = 53, p' = \frac{x}{n} = \frac{53}{100} = 0.53\nonumber \].
Interpretation of the p-value: If the null hypothesis is true, there is 0.5485 probability (54.85%) that the sample (estimated) proportion \(p'\) is 0.53 or more OR 0.47 or less (see the graph in Figure).
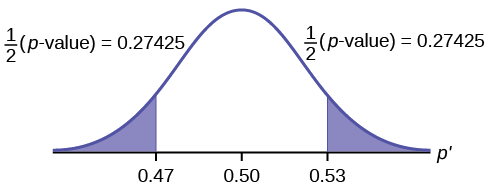
\(\mu = p = 0.50\) comes from \(H_{0}\), the null hypothesis.
\(p′ = 0.53\). Since the curve is symmetrical and the test is two-tailed, the \(p′\) for the left tail is equal to \(0.50 – 0.03 = 0.47\) where \(\mu = p = 0.50\). (0.03 is the difference between 0.53 and 0.50.)
Compare \(\alpha\) and the \(p\text{-value}\):
Since \(\alpha = 0.01\) and \(p\text{-value} = 0.5485\). \(\alpha < p\text{-value}\).
Make a decision: Since \(\alpha < p\text{-value}\), you cannot reject \(H_{0}\).
Conclusion: At the 1% level of significance, the sample data do not show sufficient evidence that the percentage of first-time brides who are younger than their grooms is different from 50%.
The \(p\text{-value}\) can easily be calculated.
Press STAT and arrow over to TESTS. Press 5:1-PropZTest. Enter .5 for \(p_{0}\), 53 for \(x\) and 100 for \(n\). Arrow down to Prop and arrow to not equals \(p_{0}\). Press ENTER. Arrow down to Calculate and press ENTER. The calculator calculates the \(p\text{-value}\) (\(p = 0.5485\)) and the test statistic (\(z\)-score). Prop not equals .5 is the alternate hypothesis. Do this set of instructions again except arrow to Draw (instead of Calculate). Press ENTER. A shaded graph appears with \(z = 0.6\) (test statistic) and \(p = 0.5485\) (\(p\text{-value}\)). Make sure when you useDraw that no other equations are highlighted in \(Y =\) and the plots are turned off.
The Type I and Type II errors are as follows:
The Type I error is to conclude that the proportion of first-time brides who are younger than their grooms is different from 50% when, in fact, the proportion is actually 50%. (Reject the null hypothesis when the null hypothesis is true).
The Type II error is there is not enough evidence to conclude that the proportion of first time brides who are younger than their grooms differs from 50% when, in fact, the proportion does differ from 50%. (Do not reject the null hypothesis when the null hypothesis is false.)
A teacher believes that 85% of students in the class will want to go on a field trip to the local zoo. She performs a hypothesis test to determine if the percentage is the same or different from 85%. The teacher samples 50 students and 39 reply that they would want to go to the zoo. For the hypothesis test, use a 1% level of significance.
First, determine what type of test this is, set up the hypothesis test, find the \(p\text{-value}\), sketch the graph, and state your conclusion.
Answer
Since the problem is about percentages, this is a test of single population proportions.
- \(H_{0} : p = 0.85\)
- \(H_{a}: p \neq 0.85\)
- \(p = 0.7554\)
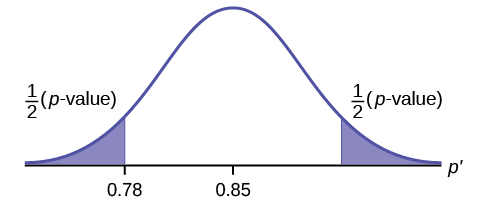
Because \(p > \alpha\), we fail to reject the null hypothesis. There is not sufficient evidence to suggest that the proportion of students that want to go to the zoo is not 85%.
Suppose a consumer group suspects that the proportion of households that have three cell phones is 30%. A cell phone company has reason to believe that the proportion is not 30%. Before they start a big advertising campaign, they conduct a hypothesis test. Their marketing people survey 150 households with the result that 43 of the households have three cell phones.
Answer
Set up the Hypothesis Test:
\(H_{0}: p = 0.30, H_{a}: p \neq 0.30\)
Determine the distribution needed:
The random variable is \(P′ =\) proportion of households that have three cell phones.
The distribution for the hypothesis test is \(P' - N\left(0.30, \sqrt{\frac{(0.30 \cdot 0.70)}{150}}\right)\)
a. The value that helps determine the \(p\text{-value}\) is \(p′\). Calculate \(p′\).
Answer
a. \(p' = \frac{x}{n}\) where \(x\) is the number of successes and \(n\) is the total number in the sample.
\(x = 43, n = 150\)
\(p′ = 43150\)
b. What is a success for this problem?
Answer
b. A success is having three cell phones in a household.
c. What is the level of significance?
Answer
c. The level of significance is the preset \(\alpha\). Since \(\alpha\) is not given, assume that \(\alpha = 0.05\).
d. Draw the graph for this problem. Draw the horizontal axis. Label and shade appropriately.
Calculate the \(p\text{-value}\).
Answer
d. \(p\text{-value} = 0.7216\)
e. Make a decision. _____________(Reject/Do not reject) \(H_{0}\) because____________.
Answer
e. Assuming that \(\alpha = 0.05, \alpha < p\text{-value}\). The decision is do not reject \(H_{0}\) because there is not sufficient evidence to conclude that the proportion of households that have three cell phones is not 30%.
Marketers believe that 92% of adults in the United States own a cell phone. A cell phone manufacturer believes that number is actually lower. 200 American adults are surveyed, of which, 174 report having cell phones. Use a 5% level of significance. State the null and alternative hypothesis, find the p-value, state your conclusion, and identify the Type I and Type II errors.
Answer
- \(H_{0}: p = 0.92\)
- \(H_{a}: p < 0.92\)
- \(p\text{-value} = 0.0046\)
Because \(p < 0.05\), we reject the null hypothesis. There is sufficient evidence to conclude that fewer than 92% of American adults own cell phones.
- Type I Error: To conclude that fewer than 92% of American adults own cell phones when, in fact, 92% of American adults do own cell phones (reject the null hypothesis when the null hypothesis is true).
- Type II Error: To conclude that 92% of American adults own cell phones when, in fact, fewer than 92% of American adults own cell phones (do not reject the null hypothesis when the null hypothesis is false).
The next example is a poem written by a statistics student named Nicole Hart. The solution to the problem follows the poem. Notice that the hypothesis test is for a single population proportion. This means that the null and alternate hypotheses use the parameter \(p\). The distribution for the test is normal. The estimated proportion \(p′\) is the proportion of fleas killed to the total fleas found on Fido. This is sample information. The problem gives a preconceived \(\alpha = 0.01\), for comparison, and a 95% confidence interval computation. The poem is clever and humorous, so please enjoy it!
My dog has so many fleas,
They do not come off with ease.
As for shampoo, I have tried many types
Even one called Bubble Hype,
Which only killed 25% of the fleas,
Unfortunately I was not pleased.
I've used all kinds of soap,
Until I had given up hope
Until one day I saw
An ad that put me in awe.
A shampoo used for dogs
Called GOOD ENOUGH to Clean a Hog
Guaranteed to kill more fleas.
I gave Fido a bath
And after doing the math
His number of fleas
Started dropping by 3's!
Before his shampoo
I counted 42.
At the end of his bath,
I redid the math
And the new shampoo had killed 17 fleas.
So now I was pleased.
Now it is time for you to have some fun
With the level of significance being .01,
You must help me figure out
Use the new shampoo or go without?
Answer
Set up the hypothesis test:
\(H_{0}: p \leq 0.25\) \(H_{a}: p > 0.25\)
Determine the distribution needed:
In words, CLEARLY state what your random variable \(\bar{X}\) or \(P′\) represents.
\(P′ =\) The proportion of fleas that are killed by the new shampoo
State the distribution to use for the test.
Normal:
\[N\left(0.25, \sqrt{\frac{(0.25){1-0.25}}{42}}\right)\nonumber \]
Test Statistic: \(z = 2.3163\)
Calculate the \(p\text{-value}\) using the normal distribution for proportions:
\[p\text{-value} = 0.0103\nonumber \]
In one to two complete sentences, explain what the p-value means for this problem.
If the null hypothesis is true (the proportion is 0.25), then there is a 0.0103 probability that the sample (estimated) proportion is 0.4048 \(\left(\frac{17}{42}\right)\) or more.
Use the previous information to sketch a picture of this situation. CLEARLY, label and scale the horizontal axis and shade the region(s) corresponding to the \(p\text{-value}\).
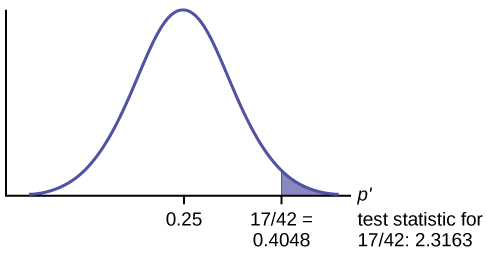
Compare \(\alpha\) and the \(p\text{-value}\):
Indicate the correct decision (“reject” or “do not reject” the null hypothesis), the reason for it, and write an appropriate conclusion, using complete sentences.
| alpha | decision | reason for decision |
|---|---|---|
| 0.01 | Do not reject \(H_{0}\) | \(\alpha < p\text{-value}\) |
Conclusion: At the 1% level of significance, the sample data do not show sufficient evidence that the percentage of fleas that are killed by the new shampoo is more than 25%.
Construct a 95% confidence interval for the true mean or proportion. Include a sketch of the graph of the situation. Label the point estimate and the lower and upper bounds of the confidence interval.
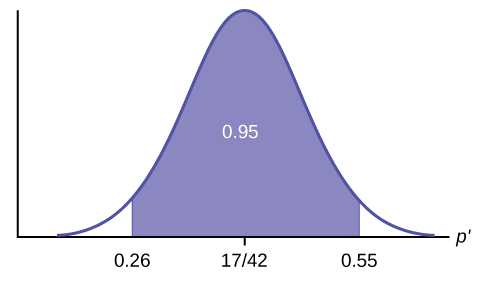
Confidence Interval: (0.26,0.55) We are 95% confident that the true population proportion p of fleas that are killed by the new shampoo is between 26% and 55%.
This test result is not very definitive since the \(p\text{-value}\) is very close to alpha. In reality, one would probably do more tests by giving the dog another bath after the fleas have had a chance to return.
The National Institute of Standards and Technology provides exact data on conductivity properties of materials. Following are conductivity measurements for 11 randomly selected pieces of a particular type of glass.
1.11; 1.07; 1.11; 1.07; 1.12; 1.08; .98; .98 1.02; .95; .95
Is there convincing evidence that the average conductivity of this type of glass is greater than one? Use a significance level of 0.05. Assume the population is normal.
Answer
Let’s follow a four-step process to answer this statistical question.
- State the Question: We need to determine if, at a 0.05 significance level, the average conductivity of the selected glass is greater than one. Our hypotheses will be
- \(H_{0}: \mu \leq 1\)
- \(H_{a}: \mu > 1\)
- Plan: We are testing a sample mean without a known population standard deviation. Therefore, we need to use a Student's-t distribution. Assume the underlying population is normal.
- Do the calculations: We will input the sample data into the TI-83 as follows.




4. State the Conclusions: Since the \(p\text{-value} (p = 0.036)\) is less than our alpha value, we will reject the null hypothesis. It is reasonable to state that the data supports the claim that the average conductivity level is greater than one.
In a study of 420,019 cell phone users, 172 of the subjects developed brain cancer. Test the claim that cell phone users developed brain cancer at a greater rate than that for non-cell phone users (the rate of brain cancer for non-cell phone users is 0.0340%). Since this is a critical issue, use a 0.005 significance level. Explain why the significance level should be so low in terms of a Type I error.
Answer
We will follow the four-step process.
- We need to conduct a hypothesis test on the claimed cancer rate. Our hypotheses will be
- \(H_{0}: p \leq 0.00034\)
- \(H_{a}: p > 0.00034\)
If we commit a Type I error, we are essentially accepting a false claim. Since the claim describes cancer-causing environments, we want to minimize the chances of incorrectly identifying causes of cancer.
- We will be testing a sample proportion with \(x = 172\) and \(n = 420,019\). The sample is sufficiently large because we have \(np = 420,019(0.00034) = 142.8\), \(nq = 420,019(0.99966) = 419,876.2\), two independent outcomes, and a fixed probability of success \(p = 0.00034\). Thus we will be able to generalize our results to the population.
- The associated TI results are

Figure \(\PageIndex{11}\).

Figure \(\PageIndex{12}\).
- Since the \(p\text{-value} = 0.0073\) is greater than our alpha value \(= 0.005\), we cannot reject the null. Therefore, we conclude that there is not enough evidence to support the claim of higher brain cancer rates for the cell phone users.
According to the US Census there are approximately 268,608,618 residents aged 12 and older. Statistics from the Rape, Abuse, and Incest National Network indicate that, on average, 207,754 rapes occur each year (male and female) for persons aged 12 and older. This translates into a percentage of sexual assaults of 0.078%. In Daviess County, KY, there were reported 11 rapes for a population of 37,937. Conduct an appropriate hypothesis test to determine if there is a statistically significant difference between the local sexual assault percentage and the national sexual assault percentage. Use a significance level of 0.01.
Answer
We will follow the four-step plan.
- We need to test whether the proportion of sexual assaults in Daviess County, KY is significantly different from the national average.
- Since we are presented with proportions, we will use a one-proportion z-test. The hypotheses for the test will be
- \(H_{0}: p = 0.00078\)
- \(H_{a}: p \neq 0.00078\)
- The following screen shots display the summary statistics from the hypothesis test.

Figure \(\PageIndex{13}\).

Figure \(\PageIndex{14}\).
- Since the \(p\text{-value}\), \(p = 0.00063\), is less than the alpha level of 0.01, the sample data indicates that we should reject the null hypothesis. In conclusion, the sample data support the claim that the proportion of sexual assaults in Daviess County, Kentucky is different from the national average proportion.
Review
The hypothesis test itself has an established process. This can be summarized as follows:
- Determine \(H_{0}\) and \(H_{a}\). Remember, they are contradictory.
- Determine the random variable.
- Determine the distribution for the test.
- Draw a graph, calculate the test statistic, and use the test statistic to calculate the \(p\text{-value}\). (A z-score and a t-score are examples of test statistics.)
- Compare the preconceived α with the p-value, make a decision (reject or do not reject H0), and write a clear conclusion using English sentences.
Notice that in performing the hypothesis test, you use \(\alpha\) and not \(\beta\). \(\beta\) is needed to help determine the sample size of the data that is used in calculating the \(p\text{-value}\). Remember that the quantity \(1 – \beta\) is called the Power of the Test. A high power is desirable. If the power is too low, statisticians typically increase the sample size while keeping α the same.If the power is low, the null hypothesis might not be rejected when it should be.
Assume \(H_{0}: \mu = 9\) and \(H_{a}: \mu < 9\). Is this a left-tailed, right-tailed, or two-tailed test?
Answer
This is a left-tailed test.
Assume \(H_{0}: \mu \leq 6\) and \(H_{a}: \mu > 6\). Is this a left-tailed, right-tailed, or two-tailed test?
Assume \(H_{0}: p = 0.25\) and \(H_{a}: p \neq 0.25\). Is this a left-tailed, right-tailed, or two-tailed test?
Answer
This is a two-tailed test.
Draw the general graph of a left-tailed test.
Draw the graph of a two-tailed test.
Answer
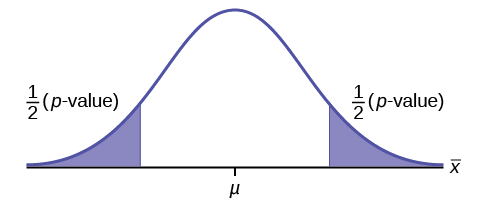
A bottle of water is labeled as containing 16 fluid ounces of water. You believe it is less than that. What type of test would you use?
Your friend claims that his mean golf score is 63. You want to show that it is higher than that. What type of test would you use?
Answer
a right-tailed test
A bathroom scale claims to be able to identify correctly any weight within a pound. You think that it cannot be that accurate. What type of test would you use?
You flip a coin and record whether it shows heads or tails. You know the probability of getting heads is 50%, but you think it is less for this particular coin. What type of test would you use?
Answer
a left-tailed test
If the alternative hypothesis has a not equals ( \(\neq\) ) symbol, you know to use which type of test?
Assume the null hypothesis states that the mean is at least 18. Is this a left-tailed, right-tailed, or two-tailed test?
Answer
This is a left-tailed test.
Assume the null hypothesis states that the mean is at most 12. Is this a left-tailed, right-tailed, or two-tailed test?
Assume the null hypothesis states that the mean is equal to 88. The alternative hypothesis states that the mean is not equal to 88. Is this a left-tailed, right-tailed, or two-tailed test?
Answer
This is a two-tailed test.
References
- Data from Amit Schitai. Director of Instructional Technology and Distance Learning. LBCC.
- Data from Bloomberg Businessweek. Available online at www.businessweek.com/news/2011- 09-15/nyc-smoking-rate-falls-to-record-low-of-14-bloomberg-says.html.
- Data from energy.gov. Available online at http://energy.gov (accessed June 27. 2013).
- Data from Gallup®. Available online at www.gallup.com (accessed June 27, 2013).
- Data from Growing by Degrees by Allen and Seaman.
- Data from La Leche League International. Available online at www.lalecheleague.org/Law/BAFeb01.html.
- Data from the American Automobile Association. Available online at www.aaa.com (accessed June 27, 2013).
- Data from the American Library Association. Available online at www.ala.org (accessed June 27, 2013).
- Data from the Bureau of Labor Statistics. Available online at http://www.bls.gov/oes/current/oes291111.htm.
- Data from the Centers for Disease Control and Prevention. Available online at www.cdc.gov (accessed June 27, 2013)
- Data from the U.S. Census Bureau, available online at quickfacts.census.gov/qfd/states/00000.html (accessed June 27, 2013).
- Data from the United States Census Bureau. Available online at www.census.gov/hhes/socdemo/language/.
- Data from Toastmasters International. Available online at http://toastmasters.org/artisan/deta...eID=429&Page=1.
- Data from Weather Underground. Available online at www.wunderground.com (accessed June 27, 2013).
- Federal Bureau of Investigations. “Uniform Crime Reports and Index of Crime in Daviess in the State of Kentucky enforced by Daviess County from 1985 to 2005.” Available online at http://www.disastercenter.com/kentucky/crime/3868.htm (accessed June 27, 2013).
- “Foothill-De Anza Community College District.” De Anza College, Winter 2006. Available online at research.fhda.edu/factbook/DA...t_da_2006w.pdf.
- Johansen, C., J. Boice, Jr., J. McLaughlin, J. Olsen. “Cellular Telephones and Cancer—a Nationwide Cohort Study in Denmark.” Institute of Cancer Epidemiology and the Danish Cancer Society, 93(3):203-7. Available online at http://www.ncbi.nlm.nih.gov/pubmed/11158188 (accessed June 27, 2013).
- Rape, Abuse & Incest National Network. “How often does sexual assault occur?” RAINN, 2009. Available online at www.rainn.org/get-information...sexual-assault (accessed June 27, 2013).
Glossary
- Central Limit Theorem
- Given a random variable (RV) with known mean \(\mu\) and known standard deviation \(\sigma\). We are sampling with size \(n\) and we are interested in two new RVs - the sample mean, \(\bar{X}\), and the sample sum, \(\sum X\). If the size \(n\) of the sample is sufficiently large, then \(\bar{X} - N\left(\mu, \frac{\sigma}{\sqrt{n}}\right)\) and \(\sum X - N \left(n\mu, \sqrt{n}\sigma\right)\). If the size n of the sample is sufficiently large, then the distribution of the sample means and the distribution of the sample sums will approximate a normal distribution regardless of the shape of the population. The mean of the sample means will equal the population mean and the mean of the sample sums will equal \(n\) times the population mean. The standard deviation of the distribution of the sample means, \(\frac{\sigma}{\sqrt{n}}\), is called the standard error of the mean.