
3.5: Tree and Venn Diagrams
- Page ID
- 16246
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Sometimes, when the probability problems are complex, it can be helpful to graph the situation. Tree diagrams and Venn diagrams are two tools that can be used to visualize and solve conditional probabilities.
Tree Diagrams
A tree diagram is a special type of graph used to determine the outcomes of an experiment. It consists of “branches” that are labeled with either frequencies or probabilities. Tree diagrams can make some probability problems easier to visualize and solve. The following example illustrates how to use a tree diagram.
Example 1
In an urn, there are 11 balls. Three balls are red (R) and eight balls are blue (B). Draw two balls, one at a time, with replacement. “With replacement” means that you put the first ball back in the urn before you select the second ball.
a. Use tree diagram to show all possible outcomes.
[reveal-answer q=”441314″]Show Answer[/reveal-answer]
[hidden-answer a=”441314″]
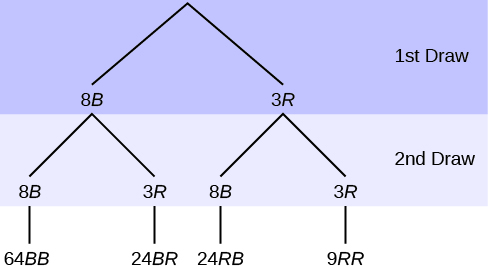
The first set of branches represents the first draw. The second set of branches represents the second draw. Each of the outcomes is distinct.
In fact, we can list each red ball as R1, R2, and R3 and each blue ball as B1, B2, B3, B4, B5, B6, B7, and B8.
Then the nine RR outcomes can be written as:
R1R1 R1R2 R1R3 R2R1 R2R2 R2R3 R3R1 R3R2 R3R3
The other outcomes are similar.
There are a total of 11 balls in the urn.
Draw two balls, one at a time, with replacement.
There are 11(11) = 121 outcomes, the size of the sample space.[/hidden-answer]
b. List the 24 BR outcomes.
[reveal-answer q=”959880″]Show Answer[/reveal-answer]
[hidden-answer a=”959880″]
B1R1, B1R2, B1R3, B2R1, B2R2, B2R3, B3R1, B3R2, B3R3, B4R1, B4R2, B4R3,
B5R1, B5R2, B5R3, B6R1, B6R2, B6R3, B7R1, B7R2, B7R3, B8R1, B8R2, B8R3[/hidden-answer]
c. Using the tree diagram, calculate P(RR).
[reveal-answer q=”660919″]Show Answer[/reveal-answer]
[hidden-answer a=”660919″]P(RR) = =
[/hidden-answer]
d. Using the tree diagram, calculate P(RB OR BR).
[reveal-answer q=”284621″]Show Answer[/reveal-answer]
[hidden-answer a=”284621″]P(RB OR BR) = ()(
) + (
)(
) =
[/hidden-answer]
e. Using the tree diagram, calculate P(R on 1st draw AND B on 2nd draw).
[reveal-answer q=”329409″]Show Answer[/reveal-answer]
[hidden-answer a=”329409″]P(R on 1st draw AND B on 2nd draw) =()(
) =
[/hidden-answer]
f. Using the tree diagram, calculate P(R on 2nd draw GIVEN B on 1st draw).
[reveal-answer q=”787274″]Show Answer[/reveal-answer]
[hidden-answer a=”787274″]P(R on 2nd B on 1st) =
=
[/hidden-answer]
g. Using the tree diagram, calculate P(BB).
[reveal-answer q=”929765″]Show Answer[/reveal-answer]
[hidden-answer a=”929765″]P(BB) = [/hidden-answer]
h. Using the tree diagram, calculate P(B on the 2nd draw given R on the first draw).
[reveal-answer q=”532098″]Show Answer[/reveal-answer]
[hidden-answer a=”532098″]]P(B on 2nd R on 1st) =
There are 9 + 24 outcomes that have R on the first draw (9 RR and 24 RB).
The sample space is then 9 + 24 = 33. 24 of the 33 outcomes have B on the second draw.
Therefore, P(B on the 2nd draw given R on the first draw) = =
[/hidden-answer]
Try It
In a standard deck, there are 52 cards. 12 cards are face cards (event F) and 40 cards are not face cards (event N). Draw two cards, one at a time, with replacement. All possible outcomes are shown in the tree diagram as frequencies. Using the tree diagram, calculate P(FF).
[reveal-answer q=”135690″]Show Answer[/reveal-answer]
[hidden-answer a=”135690″]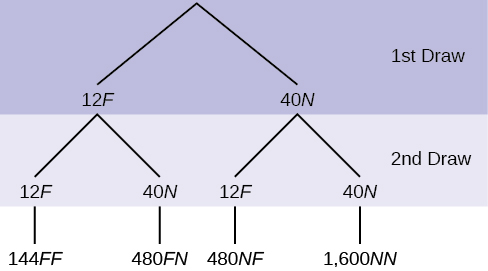 Total number of outcomes is 144 + 480 + 480 + 1600 = 2,704.
Total number of outcomes is 144 + 480 + 480 + 1600 = 2,704.
P(FF) = [/hidden-answer]
“Without replacement” means that you do not put the first ball back before you select the second marble. Following is a tree diagram for this situation. The branches are labeled with probabilities instead of frequencies. The numbers at the ends of the branches are calculated by multiplying the numbers on the two corresponding branches.
Example 2
An urn has three red marbles and eight blue marbles in it. Draw two marbles, one at a time, this time without replacement, from the urn.
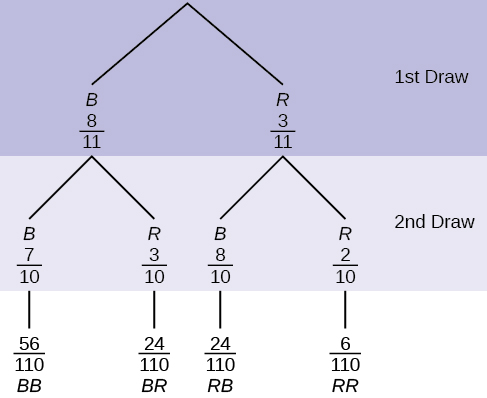
| Note:If you draw a red on the first draw from the three red possibilities, there are two red marbles left to draw on the second draw. You do not put back or replace the first marble after you have drawn it. You draw without replacement, so that on the second draw there are ten marbles left in the urn. |
a. P(RR) = ________
[reveal-answer q=”328182″]Show Answer[/reveal-answer]
[hidden-answer a=”328182″]P(RR) = [/hidden-answer]
P(RB or BR) = ____________
[reveal-answer q=”735841″]Show Answer[/reveal-answer]
[hidden-answer a=”735841″]P(RB or BR) =
[/hidden-answer]
[reveal-answer q=”414168″]Show Answer[/reveal-answer]
[hidden-answer a=”414168″]P(R on 2nd|B on 1st) =
P(R on 1st AND B on 2nd) = P(RB) = (___)(___) =
[reveal-answer q=”406859″]Show Answer[/reveal-answer]
[hidden-answer a=”406859″]P(R on 1st AND B on 2nd) = P(RB) = ()(
) =
[/hidden-answer]
e. Find P(BB).
[reveal-answer q=”191313″]Show Answer[/reveal-answer]
[hidden-answer a=”191313″]P(BB) = ()(
) =
[/hidden-answer]
f. Find P(B on 2nd|R on 1st).
[reveal-answer q=”971321″]Show Answer[/reveal-answer]
[hidden-answer a=”971321″]P(B on 2nd|R on 1st) = [/hidden-answer]
If we are using probabilities, we can label the tree in the following general way.
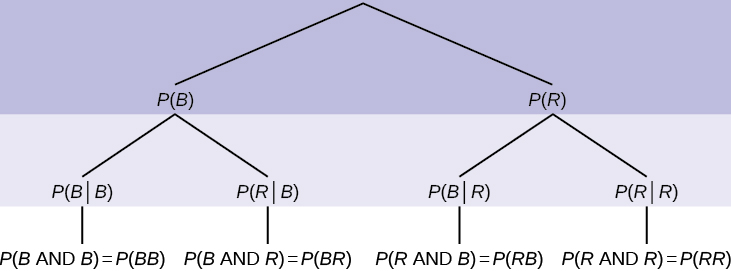
- P(R|R) here means P(R on 2nd|R on 1st)
- P(B|R) here means P(B on 2nd|R on 1st)
- P(R|B) here means P(R on 2nd|B on 1st)
- P(B|B) here means P(B on 2nd|B on 1st)

A YouTube element has been excluded from this version of the text. You can view it online here: http://pb.libretexts.org/esm/?p=70
Try It
A litter of kittens available for adoption at the Humane Society has four tabby kittens and five black kittens. A family comes in and randomly selects two kittens (without replacement) for adoption.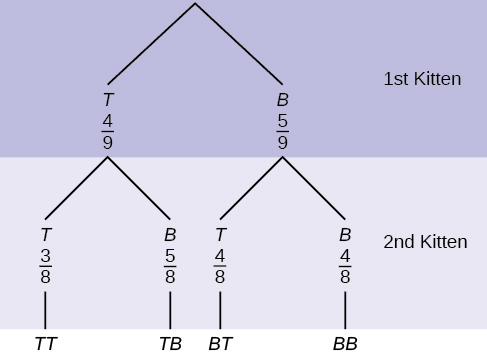
- What is the probability that both kittens are tabby?
[reveal-answer q=”790664″]Show Answer[/reveal-answer]
[hidden-answer a=”790664″]P(both kittens are tabby) =[/hidden-answer]
- What is the probability that one kitten of each coloring is selected?
[reveal-answer q=”751934″]Show Answer[/reveal-answer]
[hidden-answer a=”751934″]P(one kitten of each coloring is selected) = P(TB) + P(BT) =[/hidden-answer]
- What is the probability that a tabby is chosen as the second kitten when a black kitten was chosen as the first?
[reveal-answer q=”127054″]Show Answer[/reveal-answer]
[hidden-answer a=”127054″]P(a tabby is chosen as the second kitten when a black kitten was chosen as the first) =[/hidden-answer]
- What is the probability of choosing two kittens of the same color?
[reveal-answer q=”406130″]Show Answer[/reveal-answer]
[hidden-answer a=”406130″]P(choosing two kittens of the same color) = P(TT) + P(BB) =[/hidden-answer]
Example 3
[reveal-answer q=”603920″]Show Answer[/reveal-answer]
[hidden-answer a=”603920″]P(one of each coloring is selected) = P(RY) + P(YR) =
Venn Diagram
A Venn diagram is a picture that represents the outcomes of an experiment. It generally consists of a box that represents the sample space S together with circles or ovals. The circles or ovals represent events.
Example 4
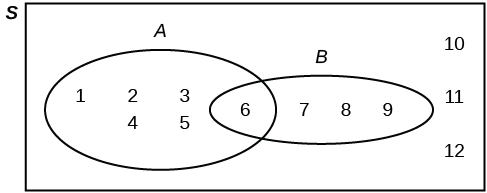
Suppose an experiment has the outcomes 1, 2, 3, … , 12 where each outcome has an equal chance of occurring.
Let event A = {1, 2, 3, 4, 5, 6} and event B = {6, 7, 8, 9}. Then A AND B = {6} and A OR B = {1, 2, 3, 4, 5, 6, 7, 8, 9}.
The Venn diagram is as follows:
Try It
Suppose an experiment has outcomes black, white, red, orange, yellow, green, blue, and purple, where each outcome has an equal chance of occurring. Let event C = {green, blue, purple} and event P = {red, yellow, blue}. Then C AND P = {blue} and C OR P = {green, blue, purple, red, yellow}. Draw a Venn diagram representing this situation.
[reveal-answer q=”239698″]Show Answer[/reveal-answer]
[hidden-answer a=”239698″]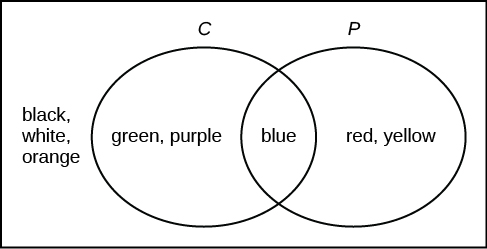 [/hidden-answer]
[/hidden-answer]
Example 5
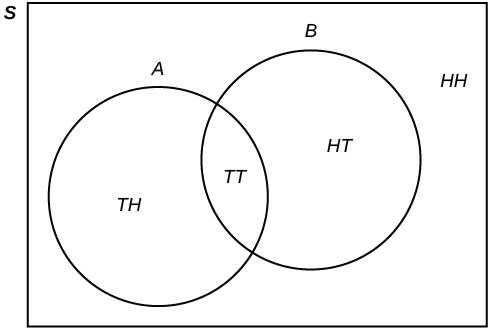
Flip two fair coins. Let A = tails on the first coin. Let B = tails on the second coin. Then A = {TT, TH} and B = {TT, HT}. Therefore,A AND B = {TT}. A OR B = {TH, TT, HT}.
The sample space when you flip two fair coins is X = {HH, HT, TH, TT}. The outcome HH is in NEITHER A NOR B. The Venn diagram is as follows:
Try It
Roll a fair, six-sided die. Let A = a prime number of dots is rolled. Let B = an odd number of dots is rolled. Then A = {2, 3, 5} and B = {1, 3, 5}. Therefore, A AND B = {3, 5}. A OR B = {1, 2, 3, 5}. The sample space for rolling a fair die is S = {1, 2, 3, 4, 5, 6}. Draw a Venn diagram representing this situation.
[reveal-answer q=”337431″]Show Answer[/reveal-answer]
[hidden-answer a=”337431″]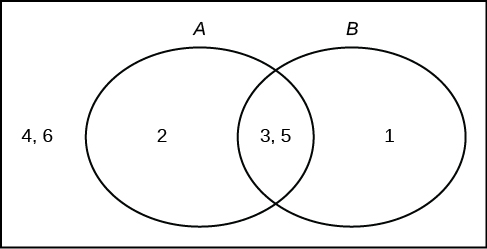 [/hidden-answer]
[/hidden-answer]
Example 6
40% of the students at a local college belong to a club and 50% work part time. 5% of the students work part time and belong to a club.
a. Draw a Venn diagram showing the relationships.
[reveal-answer q=”450398″]Show Answer[/reveal-answer]
[hidden-answer a=”450398″]Let C = student belongs to a club and PT = student works part time.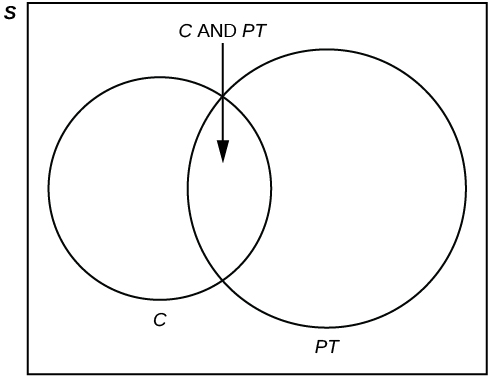 [/hidden-answer]
[/hidden-answer]
b. If a student is selected at random, find the probability that the student belongs to a club.
[reveal-answer q=”212436″]Show Answer[/reveal-answer]
[hidden-answer a=”212436″]P(the student belongs to a club) = 0.40[/hidden-answer]
c. If a student is selected at random, find the probability that the student works part time.
[reveal-answer q=”384777″]Show Answer[/reveal-answer]
[hidden-answer a=”384777″]P(the student works part time) = 0.50[/hidden-answer]
d. If a student is selected at random, find the probability that the student belongs to a club AND works part time.
[reveal-answer q=”537973″]Show Answer[/reveal-answer]
[hidden-answer a=”537973″]P(the student belongs to a club AND works part time) = 0.05[/hidden-answer]
e. If a student is selected at random, find the probability that the student belongs to a club given that the student works part time.
[reveal-answer q=”682608″]Show Answer[/reveal-answer]
[hidden-answer a=”682608″]P(the student belongs to a club given that the student works part time) = [/hidden-answer]
f. If a student is selected at random, find the probability that the student belongs to a club OR works part time.
[reveal-answer q=”313282″]Show Answer[/reveal-answer]
[hidden-answer a=”313282″]P(the student belongs to a club OR works part time) = P(the student belongs to a club) + P(the student works part time) – P(the student belongs to a club AND works part time) = 0.40 + 0.50 – 0.05 = 0.85[/hidden-answer]
Try It
Fifty percent of the workers at a factory work a second job, 25% have a spouse who also works, 5% work a second job and have a spouse who also works. Draw a Venn diagram showing the relationships. Let W = works a second job and S = spouse also works.
[reveal-answer q=”692119″]Show Answer[/reveal-answer]
[hidden-answer a=”692119″]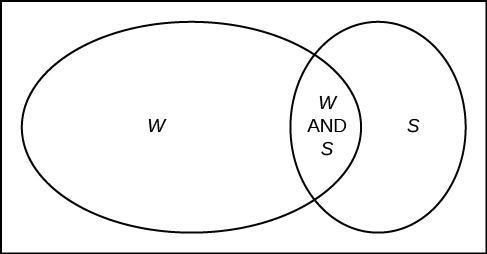 [/hidden-answer]
[/hidden-answer]
Example 7
In a bookstore, the probability that the customer buys a novel is 0.6, and the probability that the customer buys a non-fiction book is 0.4. Suppose that the probability that the customer buys both is 0.2.
- Draw a Venn diagram representing the situation.
[reveal-answer q=”316678″]Show Answer[/reveal-answer]
[hidden-answer a=”316678″]In the following Venn diagram below, the blue oval represent customers buying a novel, the red oval represents customer buying non-fiction.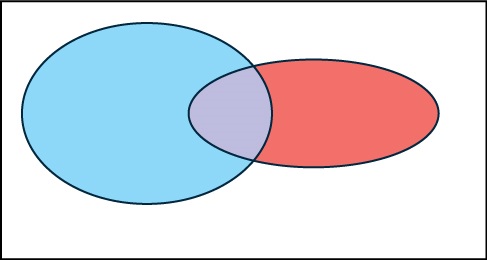
[/hidden-answer] - Find the probability that the customer buys either a novel or anon-fiction book.
[reveal-answer q=”252714″]Show Answer[/reveal-answer]
[hidden-answer a=”252714″]P(novel or non-fiction) = P(Blue OR Red) = P(Blue) + P(Red) – P(Blue AND Red) = 0.6 + 0.4 – 0.2 = 0.8.[/hidden-answer] - In the Venn diagram, describe the overlapping area using a complete sentence.
[reveal-answer q=”458336″]Show Answer[/reveal-answer]
[hidden-answer a=”458336″]The overlapping area of the blue oval and red oval represents the customers buying both a novel and a nonfiction book.[/hidden-answer] - Suppose that some customers buy only compact disks. Draw an oval in your Venn diagram representing this event.
[reveal-answer q=”929217″]Show Answer[/reveal-answer]
[hidden-answer a=”929217″]In the following Venn diagram below, the blue oval represent customers buying a novel, the red oval represents customer buying non-fiction, and the yellow oval customer who buy compact disks.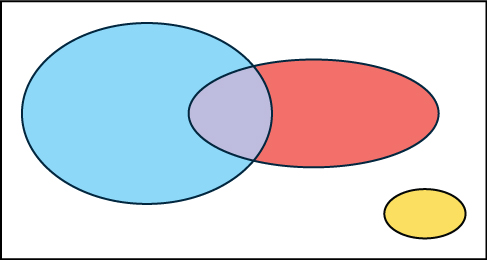 [/hidden-answer]
[/hidden-answer]
Glossary
- Tree Diagram
- the useful visual representation of a sample space and events in the form of a “tree” with branches marked by possible outcomes together with associated probabilities (frequencies, relative frequencies)
- Venn Diagram
- the visual representation of a sample space and events in the form of circles or ovals showing their intersections
e. P(R on 2nd draw GIVEN B on 1st draw) = P(R on 2nd|B on 1st) = 2488 = 311
This problem is a conditional one. The sample space has been reduced to those outcomes that already have a blue on the first draw. There are 24 + 64 = 88 possible outcomes (24 BR and 64 BB). Twenty-four of the 88 possible outcomes are BR. 2488 = 311.
f. P(BB) = 64121
g. P(B on 2nd draw|R on 1st draw) = 811
There are 9 + 24 outcomes that have R on the first draw (9 RR and 24 RB). The sample space is then 9 + 24 = 33. 24 of the 33 outcomes have B on the second draw. The probability is then 2433.
Solutions to Try These 2:
- Tree and Venn Diagrams. Provided by: OpenStax. Located at: http://cnx.org/contents/30189442-6998-4686-ac05-ed152b91b9de@18.54. License: Public Domain: No Known Copyright
- Introductory Statistics . Authored by: Barbara Illowski, Susan Dean. Provided by: Open Stax. Located at: http://cnx.org/contents/30189442-6998-4686-ac05-ed152b91b9de@18.54. License: CC BY: Attribution. License Terms: Download for free at http://cnx.org/contents/30189442-699...2b91b9de@18.54.
- Count outcomes using tree diagram. Provided by: Khan Acadamy. Located at: https://www.khanacademy.org/math/cc-seventh-grade-math/cc-7th-probability-statistics/cc-7th-compound-events/v/tree-diagram-to-count-outcomes. License: CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- Solving Problems with Venn Diagrams. Authored by: Mathispower4u. Located at: https://youtu.be/MassxXy8iko. License: All Rights Reserved. License Terms: Standard YouTube License