
5.2: Partioning the Sums of Squares
- Page ID
- 32935

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Time to partition the sums of squares again. Remember the act of partitioning, or splitting up, the variance is the core idea of ANOVA. To continue using the house analogy, our total sums of squares (SS Total) is our big empty house. We want to split it up into little rooms. Before in the between-subjects ANOVA, we partitioned SS Total using this formula:
\[SS_\text{TOTAL} = SS_\text{Effect} + SS_\text{Error} \nonumber \]
The \(SS_\text{Effect}\) was the variance we could attribute to the means of the different groups, and \(SS_\text{Error}\) was the leftover variance that we couldn’t explain. \(SS_\text{Effect}\) and \(SS_\text{Error}\) are the partitions of \(SS_\text{TOTAL}\), they are the little rooms.
In the between-subjects ANOVA above, we got to split \(SS_\text{TOTAL}\) into two parts. What is most interesting about the repeated-measures design, is that we get to split \(SS_\text{TOTAL}\) into three parts, there’s one more partition. Can you guess what the new partition is? Hint: whenever we have a new way to calculate means in our design, we can always create a partition for those new means. What are the new means in the repeated measures design?
Here is the formula for partitioning \(SS_\text{TOTAL}\) in a repeated-measures ANOVA:
\[SS_\text{TOTAL} = SS_\text{Effect} + SS_\text{Subjects} +SS_\text{Error} \nonumber \]
We’ve added \(SS_\text{Subjects}\) as the new idea in the formula. What’s the idea here? Well, because each subject or participant was measured in each condition, we have a new set of means. These are the means for each subject or participant, collapsed across the conditions. For example, subject 1 has a mean (mean of their scores in conditions A, B, and C); subject 2 has a mean (mean of their scores in conditions A, B, and C); and subject 3 has a mean (mean of their scores in conditions A, B, and C). There are three subject means, one for each subject, collapsed across the conditions. And, we can now estimate the portion of the total variance that is explained by these subject means.
Before we go into the calculations, it's important to pause and compare the differences of how the sum of squares are partitioned in between-subjects ANOVA vs. within-subjects ANOVA.
Recall, in between-subjects ANOVA, we use different words to describe parts of the ANOVA (which can be really confusing). For example, we described the SS formula for a between-subjects ANOVA like this:
\[SS_\text{TOTAL} = SS_\text{Effect} + SS_\text{Error} \nonumber \]
The very same formula is often written differently, using the words between and within in place of effect and error, it looks like this:
\[SS_\text{TOTAL} = SS_\text{Between} + SS_\text{Within} \nonumber \]
Here, \(SS_\text{Between}\) (which we have been calling \(SS_\text{Effect}\)) refers to variation between the group means, that’s why it is called \(SS_\text{Between}\). Second, and most important, \(SS_\text{Within}\) (which we have been calling \(SS_\text{Error}\)), refers to the leftover variation within each group mean. Specifically, it is the variation between each group mean and each score within that group. Remember, for each group mean, every score is probably off a little bit from the mean. So, the scores within each group have some variation. This is the within group variation, and it is why the leftover error that we can’t explain is often called \(SS_\text{Within}\).
Perhaps a picture will help to clear things up.
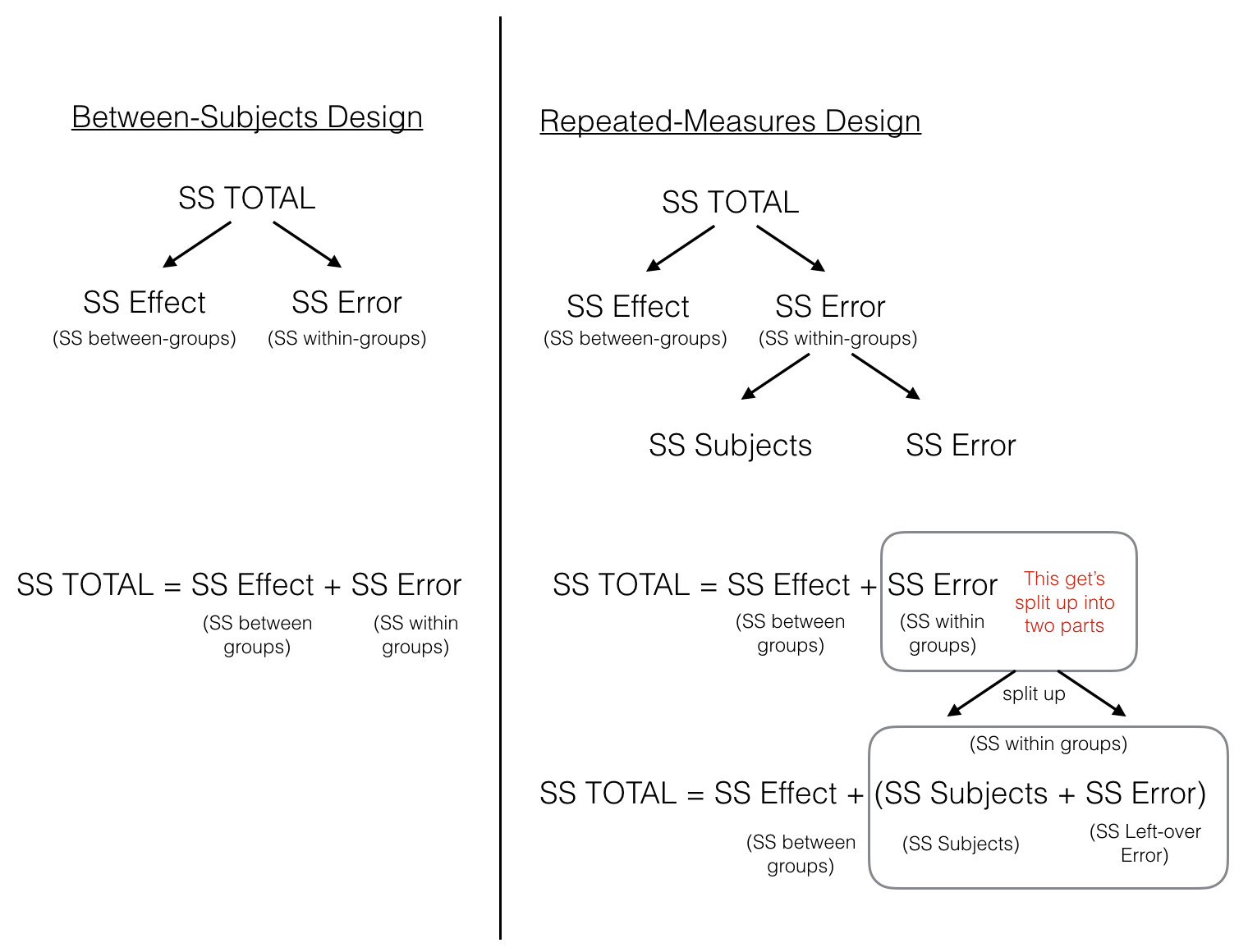
The figure lines up the partitioning of the Sums of Squares for both between-subjects and repeated-measures designs. In both designs, \(SS_\text{Total}\) is first split up into two pieces \(SS_\text{Effect (between-groups)}\) and \(SS_\text{Error (within-groups)}\). At this point, both ANOVAs are the same. In the repeated measures case we split the \(SS_\text{Error (within-groups)}\) into two more littler parts, which we call \(SS_\text{Subjects (error variation about the subject mean)}\) and \(SS_\text{Error (left-over variation we can't explain)}\).
The critical feature of the repeated-measures ANOVA, is that the \(SS_\text{Error}\) that we will later use to compute the MS (Mean Squared) in the denominator for the \(F\)-value, is smaller in a repeated-measures design, compared to a between subjects design. This is because the \(SS_\text{Error (within-groups)}\) is split into two parts, \(SS_\text{Subjects (error variation about the subject mean)}\) and \(SS_\text{Error (left-over variation we can't explain)}\).
To make this more clear, here is another figure:
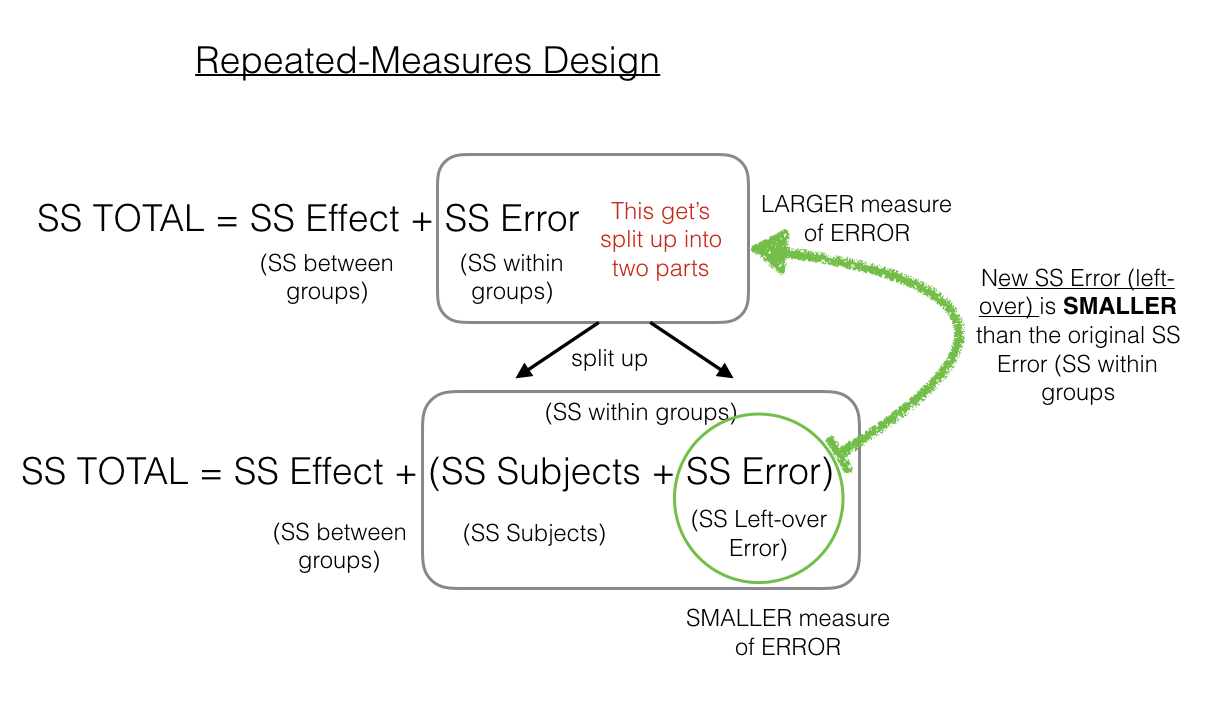
As we point out, the \(SS_\text{Error (left-over)}\) in the green circle will be a smaller number than the \(SS_\text{Error (within-group)}\). That’s because we are able to subtract out the \(SS_\text{Subjects}\) part of the \(SS_\text{Error (within-group)}\). This can have the effect of producing larger F-values when using a repeated-measures design compared to a between-subjects design, which is more likely to yield smaller P obtained values and allow us to reject the null hypothesis.