
3.3: Geometric Distribution (Special Topic)
- Page ID
- 275

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)How long should we expect to flip a coin until it turns up heads? Or how many times should we expect to roll a die until we get a 1? These questions can be answered using the geometric distribution. We first formalize each trial - such as a single coin flip or die toss - using the Bernoulli distribution, and then we combine these with our tools from probability (Chapter 2) to construct the geometric distribution.
Bernoulli Distribution
Stanley Milgram began a series of experiments in 1963 to estimate what proportion of people would willingly obey an authority and give severe shocks to a stranger. Milgram found that about 65% of people would obey the authority and give such shocks. Over the years, additional research suggested this number is approximately consistent across communities and time. (Find further information on Milgram's experiment at www.cnr.berkeley.edu/ucce50/ag-labor/7article/article35.htm.)
Each person in Milgram's experiment can be thought of as a trial. We label a person a success if she refuses to administer the worst shock. A person is labeled a failure if she administers the worst shock. Because only 35% of individuals refused to administer the most severe shock, we denote the probability of a success with p = 0:35. The probability of a failure is sometimes denoted with q = 1 - p.
Thus, success or failure is recorded for each person in the study. When an individual trial only has two possible outcomes, it is called a Bernoulli random variable.
Bernoulli random variable (descriptive)
A Bernoulli random variable has exactly two possible outcomes. We typically label one of these outcomes a "success" and the other outcome a "failure". We may also denote a success by 1 and a failure by 0.
TIP: "success" need not be something positive
We chose to label a person who refuses to administer the worst shock a "success" and all others as "failures". However, we could just as easily have reversed these labels. The mathematical framework we will build does not depend on which outcome is labeled a success and which a failure, as long as we are consistent.
Bernoulli random variables are often denoted as 1 for a success and 0 for a failure. In addition to being convenient in entering data, it is also mathematically handy. Suppose we observe ten trials:
\[0 1 1 1 1 0 1 1 0 0\]
Then the sample proportion, \( \hat {p}\), is the sample mean of these observations:
\[ \hat {p} = \dfrac {\text {# of successes}}{\text {# of trials}} = \dfrac {0 + 1 + 1 + 1 + 1 + 0 + 1 + 1 + 0 + 0}{10} = 0.6\]
This mathematical inquiry of Bernoulli random variables can be extended even further. Because 0 and 1 are numerical outcomes, we can define the mean and standard deviation of a Bernoulli random variable:
p is the true probability of a success, then the mean of a Bernoulli random variable X is given by
\[\mu = E[X] = P(X = 0) 0 + P(X = 1) 1\]
\[= (1 - p) X 0 + p X 1 = 0 + p = p\]
Similarly, the variance of \(X\) can be computed:
\[ \sigma^2 = P(X = 0)(0 - p)^2 + P(X = 1)(1 - p)^2\]
\[= (1 - p)p^2 + p(1- p)^2 = p(1- p)\]
The standard deviation is \(\sigma = \sqrt {p(1 - p)}\)
Bernoulli random variable (mathematical)
If X is a random variable that takes value 1 with probability of success p and 0 with probability 1 - p, then X is a Bernoulli random variable with mean and standard deviation
\[ \mu = p \sigma = \sqrt {p(1-p)}\]
In general, it is useful to think about a Bernoulli random variable as a random process with only two outcomes: a success or failure. Then we build our mathematical framework using the numerical labels 1 and 0 for successes and failures, respectively.
Geometric Distribution
Example \(\PageIndex{1}\) illustrates what is called the geometric distribution, which describes the waiting time until a success for independent and identically distributed (iid) Bernoulli random variables. In this case, the independence aspect just means the individuals in the example don't affect each other, and identical means they each have the same probability of success.
Example \(\PageIndex{1}\)
Dr. Smith wants to repeat Milgram's experiments, but she only wants to sample people until she finds someone who will not inflict the worst shock. (This is hypothetical since, in reality, this sort of study probably would not be permitted any longer under current ethical standards). If the probability a person will not give the most severe shock is still 0.35 and the subjects are independent, what are the chances that she will stop the study after the first person? The second person? The third? What about if it takes her n - 1 individuals who will administer the worst shock before finding her first success, i.e. the first success is on the nth person? (If the first success is the fifth person, then we say n = 5.)
Solution
The probability of stopping after the first person is just the chance the first person will not administer the worst shock: 1 - 0:65 = 0:35. The probability it will be the second person is
\[ P(\text{second person is the first to not administer the worst shock})\]
\[= P(\text{the first will, the second won't}) = (0:65)(0:35) = 0:228\]
Likewise, the probability it will be the third person is (0:65)(0:65)(0:35) = 0:148.
If the first success is on the nth person, then there are \(n - 1\) failures and finally 1 success, which corresponds to the probability \((0.65)^{n-1}(0:35)\). This is the same as \((1 - 0:35)^{n-1}(0:35)\).
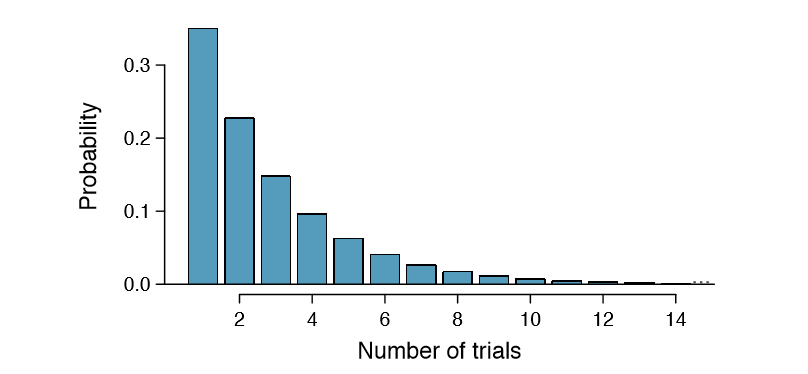
The geometric distribution from Example \(\PageIndex{1}\) is shown in Figure 3.16. In general, the probabilities for a geometric distribution decrease exponentially fast. While this text will not derive the formulas for the mean (expected) number of trials needed to find the first success or the standard deviation or variance of this distribution, we present general formulas for each.
Geometric Distribution
If the probability of a success in one trial is \(p\) and the probability of a failure is \(1 - p\), then the probability of finding the first success in the nth trial is given by
\[(1 - p)_{n-1}p \label{3.30}\]
The mean (i.e. expected value), variance, and standard deviation of this wait time are given by
\[ \mu = \dfrac {1}{7} {\sigma}^2 = \dfrac {1 - p}{p^2} \sigma = \sqrt {1 - p}{p^2} \label {3.31}\]
It is no accident that we use the symbol \(\mu\) for both the mean and expected value. The mean and the expected value are one and the same.
The left side of Equation \ref{3.31} says that, on average, it takes \(\dfrac {1}{p}\) trials to get a success. This mathematical result is consistent with what we would expect intuitively. If the probability of a success is high (e.g. 0.8), then we don't usually wait very long for a success: \(\dfrac {1}{0.8} = 1.25\) trials on average. If the probability of a success is low (e.g. 0.1), then we would expect to view many trials before we see a success: \( \dfrac {1}{0.1} = 10\) trials.
Exercise \(\PageIndex{1}\)
The probability that an individual would refuse to administer the worst shock is said to be about 0.35. If we were to examine individuals until we found one that did not administer the shock, how many people should we expect to check? The first expression in Equation \ref{3.31} may be useful.
- Answer
-
We would expect to see about 1=0:35 = 2:86 individuals to find the first success.
Example \(\PageIndex{2}\)
What is the chance that Dr. Smith will find the first success within the first 4 people?
This is the chance it is the first (n = 1), second (n = 2), third (n = 3), or fourth (n = 4) person as the first success, which are four disjoint outcomes. Because the individuals in the sample are randomly sampled from a large population, they are independent. We compute the probability of each case and add the separate results:
\[P(n = 1, 2, 3, or 4)\]
\[= P(n = 1) + P(n = 2) + P(n = 3) + P(n = 4)\]
\[= (0:65)^{1-1}(0:35) + (0:65)^{2-1}(0:35) + (0:65)^{3-1}(0:35) + (0:65)^{4-1}(0:35)\]
\[= 0:82\]
There is an 82% chance that she will end the study within 4 people.
Exercise \(\PageIndex{2}\)
Determine a more clever way to solve Example 3.33. Show that you get the same result.
- Answer
-
First find the probability of the complement: P(no success in first 4 trials) = \(0.65^4\) = 0.18. Next, compute one minus this probability: 1 - P(no success in 4 trials) = 1 - 0.18 = 0.82.
Example \(\PageIndex{3}\)
Suppose in one region it was found that the proportion of people who would administer the worst shock was "only" 55%. If people were randomly selected from this region, what is the expected number of people who must be checked before one was found that would be deemed a success? What is the standard deviation of this waiting time?
Solution
A success is when someone will not inflict the worst shock, which has probability p = 1 - 0.55 = 0.45 for this region. The expected number of people to be checked is \(\dfrac {1}{p} = \dfrac {1}{0.45} = 2.22\) and the standard deviation is \( \sqrt {\dfrac {(1 - p)}{p^2}} = 1.65\).
Exercise \(\PageIndex{3}\)
Using the results from Example 3.35, \( \mu \) = 2.22 and \( \mu \) = 1.65, would it be appropriate to use the normal model to find what proportion of experiments would end in 3 or fewer trials?
- Answer
-
No. The geometric distribution is always right skewed and can never be well-approximated by the normal model.
The independence assumption is crucial to the geometric distribution's accurate description of a scenario. Mathematically, we can see that to construct the probability of the success on the nth trial, we had to use the Multiplication Rule for Independent Processes. It is no simple task to generalize the geometric model for dependent trials.
Contributors and Attributions
David M Diez (Google/YouTube), Christopher D Barr (Harvard School of Public Health), Mine Çetinkaya-Rundel (Duke University)