
12.2.6: Conclusion - Simple Linear Regression
- Page ID
- 34855

A lurking variable is a variable other than the independent or dependent variables that may influence the regression line. For instance, the highly correlated ice cream sales and home burglary rates probably have to do with the season. Hence, linear regression does not imply cause and effect.
Two variables are confounded when their effects on the dependent variable cannot be distinguished from each other. For instance, if we are looking at diet predicting weight, a confounding variable would be age. As a person gets older, they can gain more weight with fewer calories compared to when they were younger. Another example would be predicting someone’s midterm score from hours studied for the exam. Some confounding variables would be GPA, IQ score, and teacher’s difficultly level.
Assumptions for Linear Regression
There are assumptions that need to be met when running simple linear regression. If these assumptions are not met, then one should use more advanced regression techniques.
The assumptions for simple linear regression are:
- The data need to follow a linear pattern.
- The observations of the dependent variable y are independent of one another.
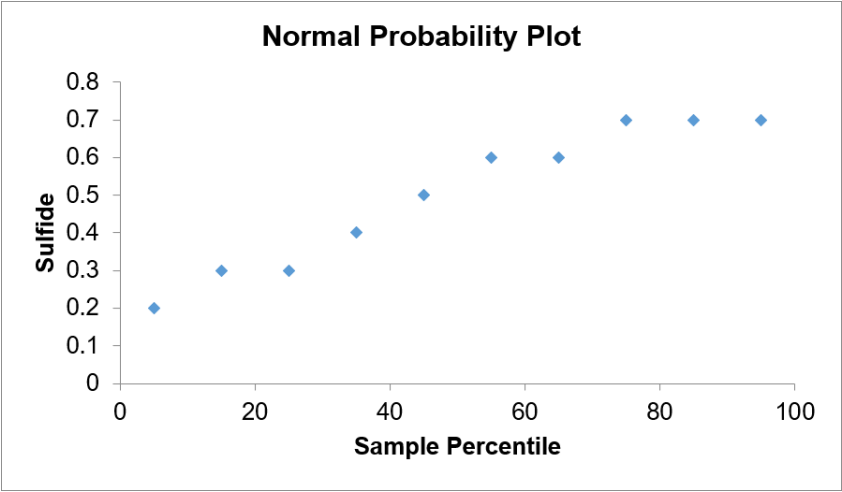
- Residuals are approximately normally distributed.
- The variance of the residuals is constant.
Most software packages will plot the residuals for each \(x\) on the \(y\)-axis against either the \(x\)-variable or \(\hat{y}\) along the \(x\)-axis. This plot is called a residual plot. Residual plots help determine some of these assumptions.
Use technology to compute the residuals and make a residual plot for the hours studied and exam grade data.
.jpg?revision=2)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
Putting It All Together
High levels of hydrogen sulfide \((\mathrm{H}_{2} \mathrm{S})\) in the ocean can be harmful to animal life. It is expensive to run tests to detect these levels. A scientist would like to see if there is a relationship between sulfate \((\mathrm{SO}_{4})\) and \(\mathrm{H}_{2} \mathrm{S}\) levels, since \(\mathrm{SO}_{4}\) is much easier and less expensive to test in ocean water. A sample of \(\mathrm{SO}_{4}\) and \(\mathrm{H}_{2} \mathrm{S}\) were recorded together at different depths in the ocean. The sample is reported below in millimolar (mM). If there were a significant relationship, the scientist would like to predict the \(\mathrm{H}_{2} \mathrm{S}\) level when the ocean has an \(\mathrm{SO}_{4}\) level of 25 mM. Run a complete regression analysis and check the assumptions. If the model is significant, then find the 95% prediction interval to predict the sulfide level in the ocean when the sulfate level is 25 mM.
.png?revision=1)
.png?revision=1)
.png?revision=2)
.png?revision=1&size=bestfit&width=267&height=416)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
.png?revision=1)
Summary
A simple linear regression should only be performed if you observe visually that there is a linear pattern in the scatterplot and that there is a statistically significant correlation between the independent and dependent variables. Use technology to find the numeric values for the \(y\)-intercept = \(a = b_{0}\) and slope = \(b = b_{1}\), then make sure to use the correct notation when substituting your numbers back in the regression equation \(\hat{y} = b_{0} + b_{1} x\). Another measure of how well the line fits the data is called the coefficient of determination \(R^{2}\). When \(R^{2}\) is close to 1 (or 100%), then the line fits the data very closely. The advantage over using \(R^{2}\) over \(r\) is that we can use \(R^{2}\) for nonlinear regression, whereas \(r\) is only for linear regression.
One should always check the assumptions for regression before using the regression equation for prediction. Make sure that the residual plots have a completely random horizontal band around zero. There should be no patterns in the residual plots such as a sideways V that may indicate a non-constant variance. A pattern like a slanted line, a U, or an upside-down U shape would suggest a non-linear model. Check that the residuals are normally distributed; this is not the same as the population being normally distributed. Check to make sure that there are no outliers. Be careful with lurking and confounding variables.