
6.1: Analysis of Correlation
- Page ID
- 3575

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)To start with relationships, one need first to find a correlation, e.g., to measure the extent and sign of relation, and to prove if this is statistically reliable.
Note that correlation does not reflect the nature of relationship (Figure \(\PageIndex{1}\)). If we find a significant correlation between variables, this could mean that A depends on B, B depends on A, A and B depend on each other, or A and B depend on a third variable C but have no relation to each other. A famous example is the correlation between ice cream sales and home fires. It would be strange to suggest that eating ice cream causes people to start fires, or that experiencing fires causes people to buy ice cream. In fact, both of these parameters depend on air temperature\(^{[1]}\).

Numbers alone could be misleading, so there is a simple rule: plot it first.
Plot it first
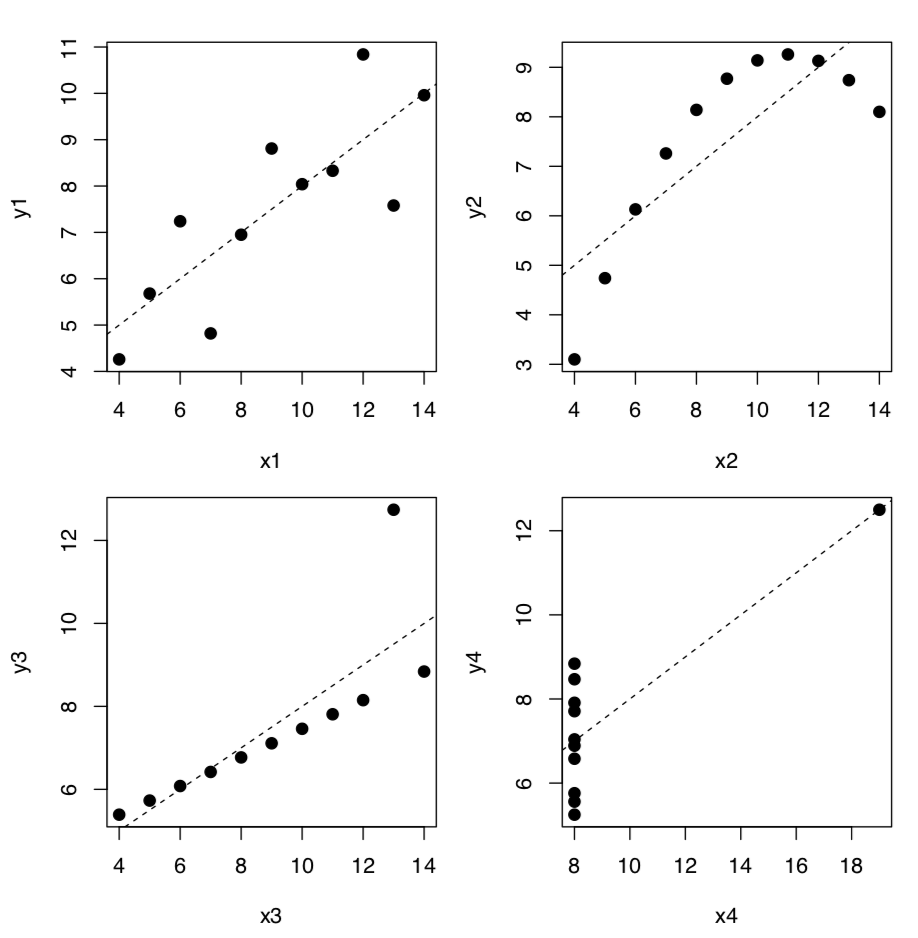
The most striking example of relationships where numbers alone do to provide a reliable answer, is the Anscombe’s quartet, four sets of two variables which have almost identical means and standard deviations:
Code \(\PageIndex{1}\) (R):
(Data anscombe is embedded into R. To compact input and output, several tricks were used. Please find them yourself.)
Linear model coefficients (see below) are also quite similar but if we plot these data, the picture (Figure \(\PageIndex{2}\)) is radically different from what is reflected in numbers:
Code \(\PageIndex{2}\) (R):
(For aesthetic purposes, we put all four plots on the same figure. Note the for operator which produces cycle repeating one sequence of commands four times. To know more, check ?"for".)
To the credit of nonparametric and/or robust numerical methods, they are not so easy to deceive:
Code \(\PageIndex{3}\) (R):
This is correct to guess that boxplots should also show the difference. Please try to plot them yourself.
Correlation
To measure the extent and sign of linear relationship, we need to calculate correlation coefficient. The absolute value of the correlation coefficient varies from 0 to 1. Zero means that the values of one variable are unconnected with the values of the other variable. A correlation coefficient of \(1\) or \(-1\) is an evidence of a linear relationship between two variables. A positive value of means the correlation is positive (the higher the value of one variable, the higher the value of the other), while negative values mean the correlation is negative (the higher the value of one, the lower of the other).
It is easy to calculate correlation coefficient in R:
Code \(\PageIndex{4}\) (R):
(By default, R calculates the parametric Pearson correlation coefficient \(r\).)
In the simplest case, it is given two arguments (vectors of equal length). It can also be called with one argument if using a matrix or data frame. In this case, the function cor() calculates a correlation matrix, composed of correlation coefficients between all pairs of data columns.
Code \(\PageIndex{5}\) (R):
As correlation is in fact the effect size of covariance, joint variation of two variables, to calculate it manually, one needs to know individual variances and variance of the difference between variables:
Code \(\PageIndex{6}\) (R):
Another way is to use cov() function which calculates covariance directly:
Code \(\PageIndex{7}\) (R):
To interpret correlation coefficient values, we can use either symnum() or Topm() functions (see below), or Mag() together with apply():
Code \(\PageIndex{8}\) (R):
If the numbers of observations in the columns are unequal (some columns have missing data), the parameter use becomes important. Default is everything which returns NA whenever there are any missing values in a dataset. If the parameter use is set to complete.obs, observations with missing data are automatically excluded. Sometimes, missing data values are so dispersed that complete.obs will not leave much of it. In that last case, use pairwise.complete.obs which removes missing values pair by pair.
Pearson’s parametric correlation coefficients characteristically fail with the Anscombe’s data:
Code \(\PageIndex{9}\) (R):
To overcome the problem, one can use Spearman’s \(\rho\) (“rho”, or rank correlation coefficient) which is most frequently used nonparametric correlation coefficient:
Code \(\PageIndex{10}\) (R):
(Spearman’s correlation is definitely more robust!)
The third kind of correlation coefficient in R is nonparametric Kendall’s \(\tau\) (“tau”):
Code \(\PageIndex{11}\) (R):
It is often used to measure association between two ranked or binary variables, i.e. as an alternative to effect sizes of the association in contingency tables.
How to check if correlation is statistically significant? As a null hypothesis, we could accept that correlation coefficient is equal to zero (no correlation). If the null is rejected, then correlation is significant:
Code \(\PageIndex{12}\) (R):
The logic of cor.test() is the same as in tests before (Table 5.1.1, Figure 5.1.1). In terms of p-value:
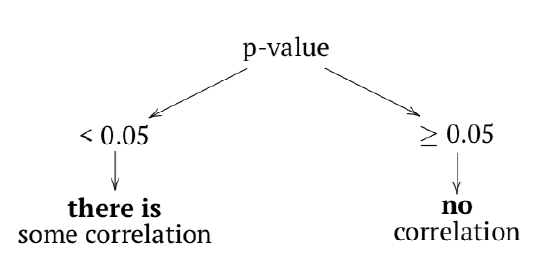
The probability of obtaining the test statistic (correlation coefficient), given the initial assumption of zero correlation between the data is very low—about 0.3%. We would reject H\(_0\) and therefore accept an alternative hypothesis that correlation between variables is present. Please note the confidence interval, it indicates here that the true value of the coefficient lies between 0.2 and 0.7. with 95% probability.
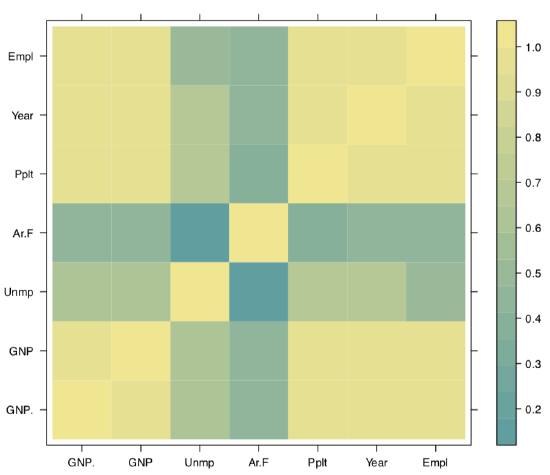
It is not always easy to read the big correlation table, like in the following example of longley macroeconomic data. Fortunately, there are several workarounds, for example, the symnum() function which replaces numbers with letters or symbols in accordance to their value:
Code \(\PageIndex{13}\) (R):
The second way is to represent the correlation matrix with a plot. For example, we may use the heatmap: split everything from \(-1\) to \(+1\) into equal intervals, assign the color for each interval and show these colors (Figure \(\PageIndex{3}\)):
Code \(\PageIndex{14}\) (R):
(We shortened here long names with the abbreviate() command.)
The other interesting way of representing correlations are correlation ellipses (from ellipse package). In that case, correlation coefficients are shown as variously compressed ellipses; when coefficient is close to \(-1\) or \(+1\), ellipse is more narrow (Figure \(\PageIndex{4}\)). The slope of ellipse represents the sign of correlation (negative or positive):
Code \(\PageIndex{15}\) (R):
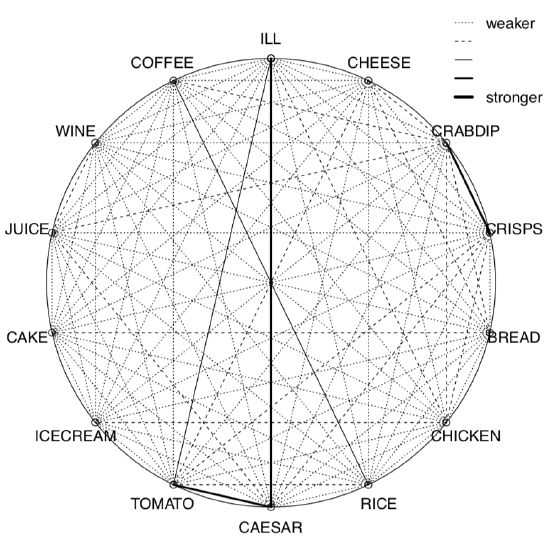
Several useful ways to visualize and analyze correlations present in the asmisc.r file supplied with this book:
Code \(\PageIndex{16}\) (R):
We calculated here Kendall’s correlation coefficient for the binary toxicity data to make the picture used on the title page. Pleiad() not only showed (Figure \(\PageIndex{5}\)) that illness is associated with tomato and Caesar salad, but also found two other correlation pleiads: coffee/rice and crab dip/crisps. (By the way, pleiads show one more application of R: analysis of networks.)
Function Cor() outputs correlation matrix together with asterisks for the significant correlation tests:
Code \(\PageIndex{17}\) (R):

Finally, function Topm() shows largest correlations by rows:
Code \(\PageIndex{18}\) (R):
Data file traits.txt contains results of the survey where most genetically apparent human phenotype characters were recorded from many individuals. Explanation of these characters are in trait_c.txt file. Please analyze this data with correlation methods.
References
1. There are, however, advanced techniques with the goal to understand the difference between causation and correlation: for example, those implemented in bnlearn package.