
2.9: Answers to exercises
- Page ID
- 3901
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Answer to the question of how to find the R command if you know only what it should do (e.g., “anova”). In order to find this from within R, you may go in several ways. First is to use double question marks command ??:
Code \(\PageIndex{1}\) (R):
(Output might be long because it includes all installed packages. Pay attention to rows started with “base” and “stats”.)
Similar result might be achieved if you start the interactive (Web browser-based) help with help.start() and then enter “anova” into the search box.
Second, even simpler way, is to use apropos():
Code \(\PageIndex{2}\) (R):
Sometimes, nothing helps:
Code \(\PageIndex{3}\) (R):
Then start to search in the Internet. It might be done from within R:
Code \(\PageIndex{4}\) (R):
In the Web browser, you should see the new tab (or window) with the query results.
If nothing helps, as the R community. Command help.request() will guide you through posting sequence.
Answer to the plot question (Figure 2.8.4):
Code \(\PageIndex{5}\) (R):
(Here empty xlab and ylab were used to remove axes labels. Note that pch=0 is the rectangle.)
Instead of col="green", one can use col=3. See below palette() command to understand how it works. To know all color names, type colors(). Argument col could also have multiple values. Check what happen if you supply, saying, col=1:3 (pay attention to the very last dots).
To know available point types, run example(points) and skip several plots to see the table of points; or simply look on Figure A.1.1 in this book (and read comments how it was made).
Answer to the question about eggs. First, let us load the data file. To use read.table() command, we need to know file structure. To know the structure, (1) we need to look on this file from R with url.show() (or without R, in the Internet browser), and also (2) to look on the companion file, eggs_c.txt.
From (1) and (2), we conclude that file has three nameless columns from which we will need first and second (egg length and width in mm, respectively). Columns are separated with large space, most likely the Tab symbol. Now we can run read.table():
Code \(\PageIndex{6}\) (R):
Next step is always to check the structure of new object:
Code \(\PageIndex{7}\) (R):
It is also the good idea to look on first rows of data:
Code \(\PageIndex{8}\) (R):
Our first and second variables received names V1 (length) and V2 (width). Now we need to plot variables to see possible relation. The best plot in that case is a scatterplot, and to make scatterplot in R, we simply use plot() command:
Code \(\PageIndex{9}\) (R):
(Command plot(y ~ x) uses Rformula interface. It is almost the same as plot(x, y)\(^{[1]}\); but note the different order in arguments.)
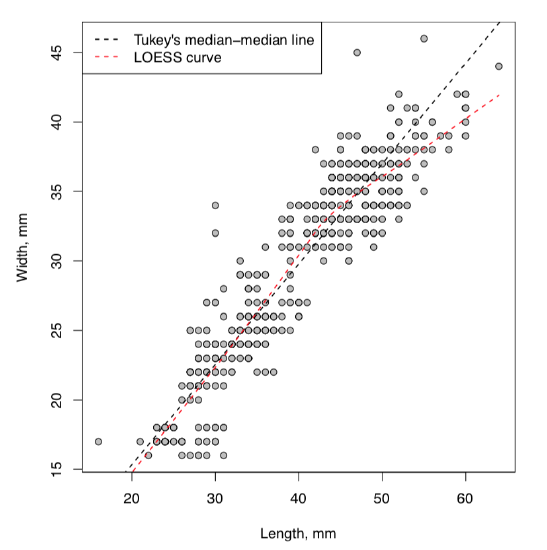
Resulted “cloud” is definitely elongated and slanted as it should be in case of dependence. What would make this more clear, is some kind of the “average” line showing the direction of the relation. As usual, there are several possibilities in R (Figure \(\PageIndex{1}\)):
Code \(\PageIndex{10}\) (R):
(Note use of line(), lines() and abline()—all three are really different commands. lines() and abline() are low-level graphic commands which add line(s) to the existing plot. First uses coordinates while the second uses coefficients. line() and loess.smooth() do not draw, they calculate numbers to use with drawing commands. To see this in more details, run help() for every command.)
First line() approach uses John Tukey’s algorithm based on medians (see below) whereas loess.smooth() uses more complicated non-linear LOESS (LOcally wEighted Scatterplot Smoothing) which estimates the overall shape of the curve\(^{[2]}\). Both are approximate but robust, exactly what we need to answer the question. Yes, there is a dependence between egg maximal width and egg maximal length.
There is one problem though. Look on the Figure \(\PageIndex{1}\): many “eggs” are overlaid with other points which have exact same location, and it is not easy to see how many data belong to one point. We will try to access this in next chapter.
Answer to the R script question. It is enough to create (with any text editor) the text file and name it, for example, my_script1.r. Inside, type the following:
pdf("my_plot1.pdf")
plot(1:20)
dev.off()
Create the subdirectory test and copy your script there. Then close R as usual, open it again, direct it (through the menu or with setwd() command) to make the test subdirectory the working directory, and run:
Code \(\PageIndex{11}\) (R):
If everything is correct, then the file my_plot1.pdf will appear in the test directory. Please do not forget to check it: open it with your PDF viewer. If anything went wrong, it is recommended to delete directory test along with all content, modify the master copy of script and repeat the cycle again, until results become satisfactory.
References
1. In the case of our eggs data frame, the command of second style would be plot(eggs[, 1:2]) or plot(eggs$V1, eggs$V2),seemoreexplanationsinthenextchapter.
2. Another variant is to use high-level scatter.smooth() function which replaces plot(). Third alternative is a cubic smoother smooth.spline() which calculates numbers to use with lines().