
15.2: Regression Line Equation
- Page ID
- 17419

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The goal of regression is the same as the goal of ANOVA: to take what we know about one variable (\(X\)) and use it to explain our observed differences in another variable (\(Y\)). In ANOVA, we talked about – and tested for – group mean differences, but in regression we do not have groups for our explanatory variable; we have a continuous variable, like in correlation. Because of this, our vocabulary will be a little bit different, but the process, logic, and end result are all the same.
Regression Equation
In regression, we most frequently talk about prediction, specifically predicting our outcome variable \(Y\) from our explanatory variable \(X\), and we use the line of best fit to make our predictions. Let’s take a look at the equation for the line, which is quite simple:
\[\widehat{\mathrm{Y}}=\mathrm{a}+\mathrm{bX} \nonumber \]
In which \(\mathrm{bX} \) mean beta times X.
The terms in the equation are defined as:
- \(\widehat{\mathrm{Y}}\): the predicted value of \(Y\) for an individual person
- \(a\): the intercept of the line
- \(b\): the slope of the line
- \(X\): the observed value of \(X\) for an individual person
What this shows us is that we will use our known value of \(X\) for each person to predict the value of \(Y\) for that person. The predicted value, \(\widehat{\mathrm{Y}}\), is called “\(y\)-hat” and is our best guess for what a person’s score on the outcome is. The equation has only two parameter estimates: an intercept (where the line crosses the Y-axis) and a slope (how steep – and the direction, positive or negative – the line is). I bet when you took geometry in high school, you never thought that you'd use that again! But here we are, talking about slopes. The intercept and slope are parameter estimates because, like everything else in statistics, we are interested in approximating the true value of the relation in the population but can only ever estimate it using sample data. We will soon see that one of these parameters, the slope, is the focus of our hypothesis tests (the intercept is only there to make the math work out properly and is rarely interpretable). The formulae for these parameter estimates use very familiar values.
First, we'll start with the intercept (a):
\[\mathrm{a}=\overline{X_y}- (\mathrm{b} \times \overline{X_x}) \nonumber \]
We have seen each of these before. \(\overline{X_y}\) and \(\overline{X_x}\) are the means of \(Y\) and \(X\), respectively.
Next, the slope:
\[ \dfrac{\sum(Diff_{x} \times Diff_{y})}{\sum({Diff_{X}}^2)} \nonumber \]
In which "Diff" means the difference of each score from the mean. Thus, just like with standard deviations, we must subtract the mean from each score. The numerator of this formula means that, for each person, we multiply their score on the first variable minus the means of that variable times their score on the second variable minus the mean of that variable. When we do that for each participant, then we sum all of those products (scores that were multiplied). The denominator is the squaring of each of those differences score (each person's score minus the mean) for the first variable, then summing all of those squared into one number,
It is very important to point out that the \(Y\) values in the equations for \(a\) and \(b\) are our observed \(Y\) values in the dataset, NOT the predicted \(Y\) values (\(\widehat{\mathrm{Y}}\)) from our equation for the line of best fit. You may be asking why we would try to predict \(Y\) if we have an observed value of \(Y\), and that is a very reasonable question. The answer is that we first need a group with all of the values (observed X and observed Y) to create the intercept and slope. Then, we can use that on samples in which we don't have values for the Y variable. In other words, we need to use known values of \(Y\) to calculate the parameter estimates in our equation, and we use the difference between our observed values and predicted values (\(Y – \widehat{\mathrm{Y}}\)) to see how accurate our equation is. Then, we can use regression to create a predictive model that we can then use to predict values of \(Y\) for other people for whom we only have information on \(X\).
Example
Let’s look at this from an applied example. Businesses often have more applicants for a job than they have openings available, so they want to know who among the applicants is most likely to be the best employee. There are many criteria that can be used, but one is a personality test for conscientiousness, with the belief being that more conscientious (more responsible) employees are better than less conscientious employees. A business might give their employees a personality inventory to assess conscientiousness and existing performance data to look for a relation. In this example, we have known values of the predictor (\(X\), conscientiousness) and outcome (\(Y\), job performance), so we can estimate an equation for a line of best fit and see how accurately conscientious predicts job performance, then use this equation to predict future job performance of applicants based only on their known values of conscientiousness from personality inventories given during the application process.
The key to assessing whether a linear regression works well is the difference between our observed and known \(Y\) values and our predicted \(\widehat{\mathrm{Y}}\) values. We use subtraction to find the difference between them (\(Y – \widehat{\mathrm{Y}}\)) in the same way we use subtraction for deviation scores and sums of squares. The value (\(Y – \widehat{\mathrm{Y}}\)) is our residual, which, as defined before, is how close our line of best fit is to our actual values. We can visualize residuals to get a better sense of what they are by creating a scatterplot and overlaying a line of best fit on it, as shown in Figure \(\PageIndex{1}\).
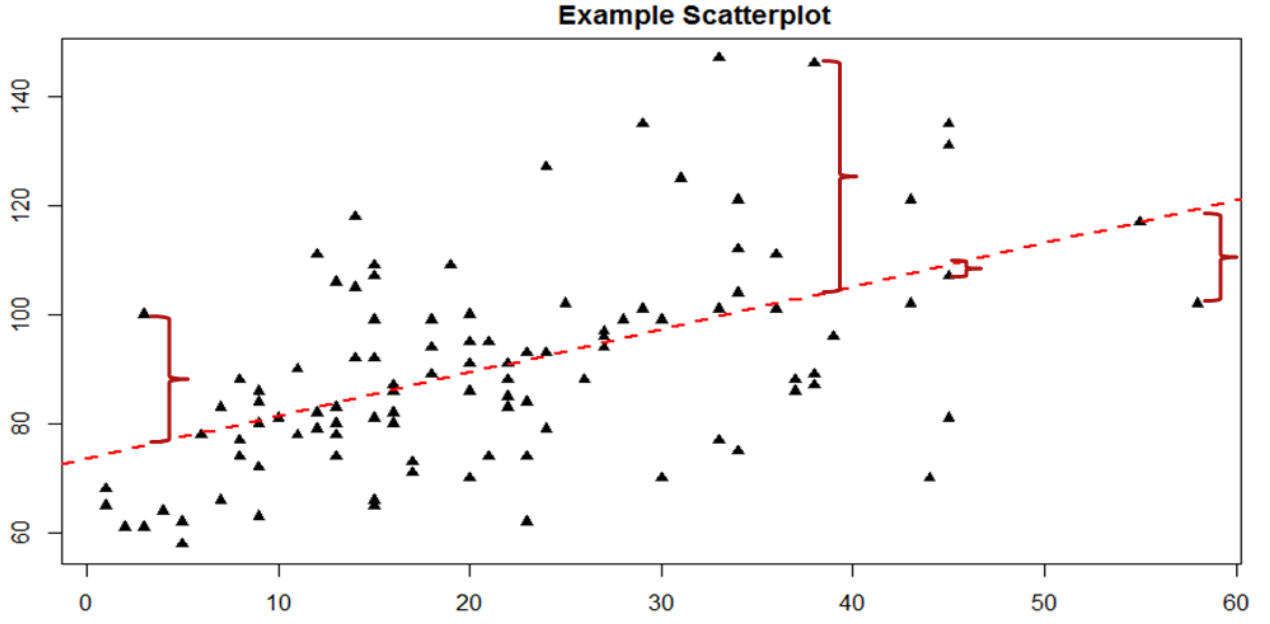
In Figure \(\PageIndex{1}\), the triangular dots represent observations from each person on both X (Conscientiousness scores) and Y (job performance ratings). The dashed red line is the line of best fit estimated by the equation \(\widehat{\mathrm{Y}}= a + (b * X)\). For every person in the dataset, the line represents their predicted score. The red bracket between a few of the triangular dots and the predicted scores on the line of best fit are our residuals (they are only drawn for four observations for ease of viewing, but in reality there is one for every observation); you can see that some residuals are positive and some are negative, and that some are very large and some are very small. This means that some predictions are very accurate and some are very inaccurate, and the some predictions overestimated values and some underestimated values. Across the entire dataset, the line of best fit is the one that minimizes the total (sum) value of all residuals. That is, although predictions at an individual level might be somewhat inaccurate, across our full sample and (theoretically) in future samples our total amount of error is as small as possible. We call this property of the line of best fit the Least Squares Error Solution. This term means that the solution – or equation – of the line is the one that provides the smallest possible value of the squared errors (squared so that they can be summed, just like in standard deviation) relative to any other straight line we could draw through the data.
Ack, that was a lot. It's okay if you don't totally understand what's going on here. This is the foundation of the equation and the interpretation, but, just like with null hypothesis significance testing, you can figure out how to interpret the results without completely understanding the conceptual underpinnings.
Predicting Scores and Explaining Variance
The purpose of regression is twofold: we want to predict scores based on our line and, as stated earlier, explain variance in our observed \(Y\) variable just like in ANOVA. These two purposes go hand in hand, and our ability to predict scores is literally our ability to explain variance. That is, if we cannot account for the variance in \(Y\) based on \(X\), then we have no reason to use \(X\) to predict future values of \(Y\).
We know that the overall variance in \(Y\) (job performance in this example) is a function of each score deviating from the mean of \(Y\) (as in our calculation of variance and standard deviation). So, just like the red brackets in Figure \(\PageIndex{1}\) representing residuals, given as (\(Y – \widehat{\mathrm{Y}}\)), we can visualize the overall variance as each score’s distance from the overall mean of \(Y\), given as (\(Y – \overline{X_y}\)). This is shown in Figure \(\PageIndex{2}\).
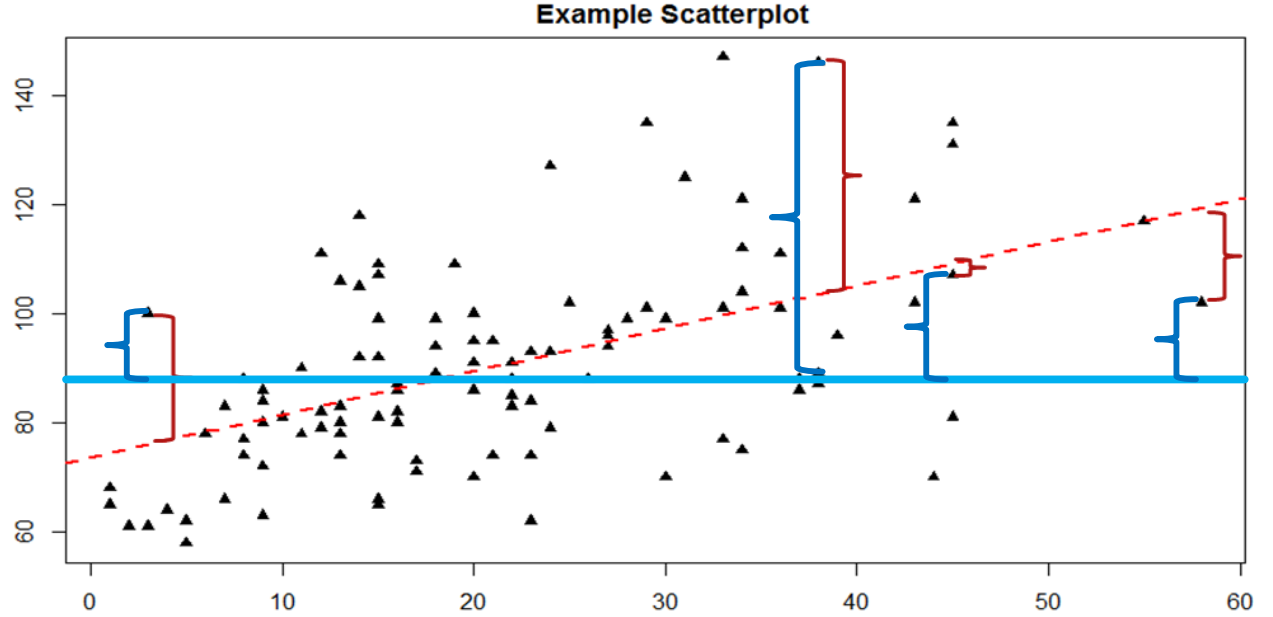
In Figure \(\PageIndex{2}\), the solid blue line is the mean of \(Y\) (job performanc), and the blue brackets are the deviation scores between our observed values of \(Y\) and the mean of \(Y\). This represents the overall variance that we are trying to explain. Thus, the residuals and the deviation scores are the same type of idea: the distance between an observed score and a given line, either the line of best fit that gives predictions or the line representing the mean that serves as a baseline. Here's why math is so cool: The difference between these two values, which is the distance between the lines themselves, is our model’s ability to predict scores above and beyond the baseline mean; that is, it is our model's ability to explain the variance we observe in \(Y\) (job performance) based on values of \(X\) (conscientiousness). If we have no ability to explain variance, then our line will be flat (the slope will be 0.00) and will be the same as the line representing the mean, and the distance between the lines will be 0.00 as well.
Summary
We now have three pieces of information: the distance from the observed score to the mean, the distance from the observed score to the prediction line, and the distance from the prediction line to the mean. These are our three pieces of information needed to test our hypotheses about regression. They are our three Sums of Squares, just like in ANOVA. Our distance from the observed score to the mean is the Sum of Squares Total, which we are trying to explain. Our distance from the observed score to the prediction line is our Sum of Squares Error, or residual, which we are trying to minimize. Our distance from the prediction line to the mean is our Sum of Squares Model, which is our observed effect and our ability to explain variance. Each of these will go into the ANOVA table to calculate our test statistic.
Contributors and Attributions
Foster et al. (University of Missouri-St. Louis, Rice University, & University of Houston, Downtown Campus)