
14.1: Introduction to Linear Regression
- Page ID
- 2166

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Learning Objectives
- Identify errors of prediction in a scatter plot with a regression line
In simple linear regression, we predict scores on one variable from the scores on a second variable. The variable we are predicting is called the criterion variable and is referred to as \(Y\). The variable we are basing our predictions on is called the predictor variable and is referred to as \(X\). When there is only one predictor variable, the prediction method is called simple regression. In simple linear regression, the topic of this section, the predictions of \(Y\) when plotted as a function of \(X\) form a straight line.
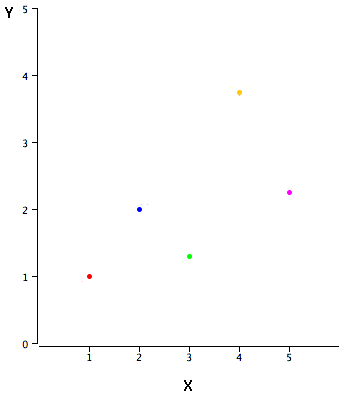
The example data in Table \(\PageIndex{1}\) are plotted in Figure \(\PageIndex{1}\). You can see that there is a positive relationship between \(X\) and \(Y\). If you were going to predict \(Y\) from \(X\), the higher the value of \(X\), the higher your prediction of \(Y\).
| X | Y |
|---|---|
| 1.00 | 1.00 |
| 2.00 | 2.00 |
| 3.00 | 1.30 |
| 4.00 | 3.75 |
| 5.00 | 2.25 |
Linear regression consists of finding the best-fitting straight line through the points. The best-fitting line is called a regression line. The black diagonal line in Figure \(\PageIndex{2}\) is the regression line and consists of the predicted score on \(Y\) for each possible value of \(X\). The vertical lines from the points to the regression line represent the errors of prediction. As you can see, the red point is very near the regression line; its error of prediction is small. By contrast, the yellow point is much higher than the regression line and therefore its error of prediction is large.
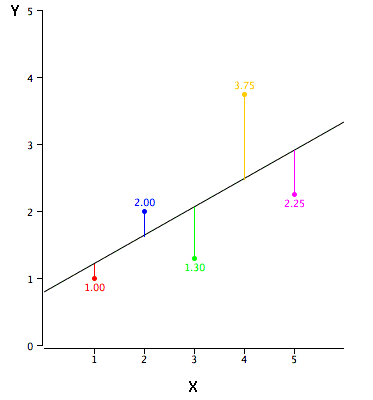
The error of prediction for a point is the value of the point minus the predicted value (the value on the line). Table \(\PageIndex{2}\) shows the predicted values (\(Y'\)) and the errors of prediction (\(Y-Y'\)). For example, the first point has a \(Y\) of \(1.00\) and a predicted \(Y\) (called \(Y'\)) of \(1.21\). Therefore, its error of prediction is \(-0.21\).
| X | Y | Y' | Y-Y' | (Y-Y')2 |
|---|---|---|---|---|
| 1.00 | 1.00 | 1.210 | -0.210 | 0.044 |
| 2.00 | 2.00 | 1.635 | 0.365 | 0.133 |
| 3.00 | 1.30 | 2.060 | -0.760 | 0.578 |
| 4.00 | 3.75 | 2.485 | 1.265 | 1.600 |
| 5.00 | 2.25 | 2.910 | -0.660 | 0.436 |
You may have noticed that we did not specify what is meant by "best-fitting line." By far, the most commonly-used criterion for the best-fitting line is the line that minimizes the sum of the squared errors of prediction. That is the criterion that was used to find the line in Figure \(\PageIndex{2}\). The last column in Table \(\PageIndex{2}\) shows the squared errors of prediction. The sum of the squared errors of prediction shown in Table \(\PageIndex{2}\) is lower than it would be for any other regression line.
The formula for a regression line is
\[Y' = bX + A\]
where \(Y'\) is the predicted score, \(b\) is the slope of the line, and \(A\) is the \(Y\) intercept. The equation for the line in Figure \(\PageIndex{2}\) is
\[Y' = 0.425X + 0.785\]
For \(X = 1\),
\[Y' = (0.425)(1) + 0.785 = 1.21\]
For \(X = 2\),
\[Y' = (0.425)(2) + 0.785 = 1.64\]
Computing the Regression Line
In the age of computers, the regression line is typically computed with statistical software. However, the calculations are relatively easy, and are given here for anyone who is interested. The calculations are based on the statistics shown in Table \(\PageIndex{3}\). \(M_X\) is the mean of \(X\), \(M_Y\) is the mean of \(Y\), \(s_X\) is the standard deviation of \(X\), \(s_Y\) is the standard deviation of \(Y\), and \(r\) is the correlation between \(X\) and \(Y\).
Formula for standard deviation
Formula for correlation
| MX | MY | sX | sY | r |
|---|---|---|---|---|
| 3 | 2.06 | 1.581 | 1.072 | 0.627 |
The slope (\(b\)) can be calculated as follows:
\[b = r \frac{s_Y}{s_X}\]
and the intercept (\(A\)) can be calculated as
\[A = M_Y - bM_X\]
For these data,
\[b = \frac{(0.627)(1.072)}{1.581} = 0.425\]
\[A = 2.06 - (0.425)(3) = 0.785\]
Note that the calculations have all been shown in terms of sample statistics rather than population parameters. The formulas are the same; simply use the parameter values for means, standard deviations, and the correlation.
Standardized Variables
The regression equation is simpler if variables are standardized so that their means are equal to \(0\) and standard deviations are equal to \(1\), for then \(b = r\) and \(A = 0\). This makes the regression line:
\[Z_{Y'} = (r)(Z_X)\]
where \(Z_{Y'}\) is the predicted standard score for \(Y\), \(r\) is the correlation, and \(Z_X\) is the standardized score for \(X\). Note that the slope of the regression equation for standardized variables is \(r\).
A Real Example
The case study "SAT and College GPA" contains high school and university grades for \(105\) computer science majors at a local state school. We now consider how we could predict a student's university GPA if we knew his or her high school GPA.
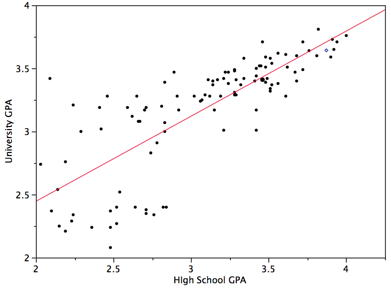
Figure \(\PageIndex{3}\) shows a scatter plot of University GPA as a function of High School GPA. You can see from the figure that there is a strong positive relationship. The correlation is \(0.78\). The regression equation is:
\[\text{University GPA'} = (0.675)(\text{High School GPA}) + 1.097\]
Therefore, a student with a high school GPA of \(3\) would be predicted to have a university GPA of
\[\text{University GPA'} = (0.675)(3) + 1.097 = 3.12\]
Assumptions
It may surprise you, but the calculations shown in this section are assumption-free. Of course, if the relationship between \(X\) and \(Y\) were not linear, a different shaped function could fit the data better. Inferential statistics in regression are based on several assumptions, and these assumptions are presented in a later section of this chapter.