
6.2: Discrete Data Percentiles and Quartiles
- Page ID
- 31797
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
Before we get into how to calculate percentile in a data set, note that we can see percentiles directly on a cumulative frequency plot, see Figure 6.2.
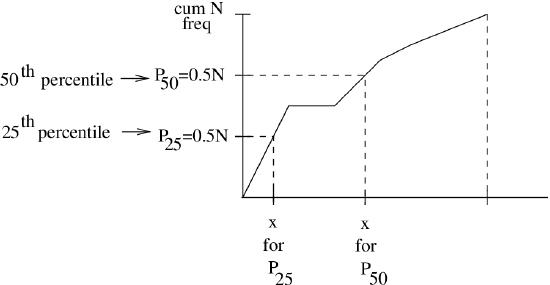
Computing percentile positions of discrete data. Let \(i\) be the ordered position of a data set of \(n\) data points, then we define the percentile position of \(x_{i}\) to be
\[\begin{equation*} P(x_{i}) = \frac{(i-1)}{(n-1)} \times 100. \end{equation*} \tag{6.1}\]
This formula has the property that \(P(x_{1}=L) = 0\) and \(P(x_{n} = H) = 100\). It is what we will use as a percentile formula but it is not the only one. Look at Figure 6.1. The way the histogram there is shaded the formula would be \(P(x_{i}) = \frac{i}{n} \times 100\) which would have the property that \(P(L) = \frac{100}{n}\) and \(P(H) = 100\). There are other, not necessarily wrong, ways to define the percentile position of discrete data but we will use Equation 6.1.
If you want to find the position, \(i\), of the data point corresponding to a given percentile \(P\) then compute
\[\begin{equation*} i = \left[ \frac{P \times (n-1)}{100} \right] + 1. \end{equation*} \tag{6.2}\]
Equation (6.2) is derived by solving Equation (6.1) for \(i\). Note that Equation (6.2) gives the position of the data point \(x_{i}\), not its value. To clarify that, let’s look at an example.
Example 6.1 : Consider the dataset given below. Data would originally be given as the numbers in the first line. So the first step in answering any question about percentiles is to order the data, the same as what you need to to to determine the median of a dataset. Once the data are ordered, then you may assign a position number to each data point as shown in the third line.
| original data | 18 | 15 | 12 | 6 | 8 | 2 | 3 | 5 | 20 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| ordered data | 2 | 3 | 5 | 6 | 8 | 10 | 12 | 15 | 18 | 20 |
| \(i\) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| \(n=10\) | ||||||||||
Q : What is the percentile rank of \(x_{i} = 12\)?
A : \(i=7\) so \(P(12) = P(x_{7}) = \frac{(7-1)}{10-1} \times 100 = \frac{6}{4} \times 100 = 67^{\rm th}\) percentile.
Q : What is the value corresponding to the \(25^{\rm th}\) percentile, \(P_{25}\)?
A : \(i = \left[ \frac{P \times (n-1)}{100} \right] +1 =\left[ \frac{(25) \times (10-1)}{100}\right] +1 = \left[ \frac{25 \times 9}{100}\right] + 1 = 2.25 + 1 = 3.25\)
The closest \(i\) is 3 and \(x_3 = 5\). We can write \(P_{25} = 5\).
▢
Decile :
\(D(x_i) \equiv\) The decile of data value \(x_{i}\) in the ordered position \(i\) is defined as
\[ D(x_i) = \frac{P(x_i)}{10} \hspace{1in} 0 \leq D(x_{i}) \leq 10 \]
We will not make much use of decile except to see that quartile is defined in the same way.
Quartile :
\(Q(x_i) \equiv\) The quartile of data value \(x_i\) in the ordered position 1.
\[\begin{equation*} Q(x_i) = \frac{P(x_{i})}{25} \hspace{1in} 0 \leq Q(x_{i}) \leq 4 \end{equation*} \tag{6.3}\]
Notation : (This notation also applies to \(P\) and \(D\).) We write :
\(Q_{0}\) &=& \(0^{\rm th}\) quartile
\(Q_1\) & = & \(1^{\rm st}\) quartile
\(Q_2\) & = & \(2^{\rm nd}\) quartile
\(Q_3\) & = & \(3^{\rm rd}\) quartile
\(Q_4\) & = & \(4^{\rm th}\) quartile
Quartiles are useful because we do not have to compute percentile first and then divide by 25 as given by Equation (6.3). Instead, we can use the following handy tricks after ordering our data:
\begin{eqnarray*} Q_{2} & = & \mbox{ MD (median)}\\ Q_{1}& = & \mbox{ MD of values less than $Q_{2}$}\\ Q_{3} & = & \mbox{ MD of values greater than $Q_{2}$}\\ Q_{0} &=& L \\ Q_{4} &=& H \end{eqnarray*}
Example 6.2 : Example with an even number of data points. With the data in order, first find the median, then the medians of the two halves of the dataset :
\[5 \hspace{.25in} 6 \hspace{.25in} 12 \hspace{.25in} 13 \hspace{.25in} 15 \hspace{.25in} 18 \hspace{.25in} 22 \hspace{.25in} 50\]
\(Q_1 = \frac{6 + 12}{2} = 9\)
\(MD = \frac{13 + 15}{2} = 14 = Q_2\)
\(Q_3 = \frac{18 + 22}{2} = 20\)
\(Q_{0} = L = 5\)
\(Q_{4} = H = 50\)
▢
Example 6.3 : Example with an even number of data points. With the data in order, first find the median, then the medians of the two halves of the dataset :
\[2 \hspace{.25in} 5 \hspace{.25in} 11 \hspace{.25in} 14 \hspace{.25in} 18 \hspace{.25in} 25 \hspace{.25in} 35\]
\(Q_{1} = 5\)
\(MD = 14 = Q_{2}\)
\(Q_{3} = 25\)
\(Q_{0} = L = 2\)
\(Q_{4} = H = 35\)
▢