
11.1: Introduction to Bernoulli Trials
- Page ID
- 10233

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Basic Theory
Definition
The Bernoulli trials process, named after Jacob Bernoulli, is one of the simplest yet most important random processes in probability. Essentially, the process is the mathematical abstraction of coin tossing, but because of its wide applicability, it is usually stated in terms of a sequence of generic trials
.
A sequence of Bernoulli trials satisfies the following assumptions:
- Each trial has two possible outcomes, in the language of reliability called success and failure.
- The trials are independent. Intuitively, the outcome of one trial has no influence over the outcome of another trial.
- On each trial, the probability of success is \(p\) and the probability of failure is \(1 - p\) where \(p \in [0, 1]\) is the success parameter of the process.
Random Variables
Mathematically, we can describe the Bernoulli trials process with a sequence of indicator random variables:
\[ \bs{X} = (X_1, X_2, \ldots) \]
An indicator variable is a random variable that takes only the values 1 and 0, which in this setting denote success and failure, respectively. Indicator variable \(X_i\) simply records the outcome of trial \(i\). Thus, the indicator variables are independent and have the same probability density function: \[ \P(X_i = 1) = p, \quad \P(X_i = 0) = 1 - p \] The distribution defined by this probability density function is known as the Bernoulli distribution. In statistical terms, the Bernoulli trials process corresponds to sampling from the Bernoulli distribution. In particular, the first \(n\) trials \((X_1, X_2, \ldots, X_n)\) form a random sample of size \(n\) from the Bernoulli distribution. Note again that the Bernoulli trials process is characterized by a single parameter \(p\).
The joint probability density function of \((X_1, X_2, \ldots, X_n)\) trials is given by \[ f_n(x_1, x_2, \ldots, x_n) = p^{x_1 + x_2 + \cdots + x_n} (1 - p)^{n- (x_1 + x_2 + \cdots + x_n)}, \quad (x_1, x_2, \ldots, x_n) \in \{0, 1\}^n \]
Proof
This follows from the basic assumptions of independence and the constant probabilities of 1 and 0.
Note that the exponent of \(p\) in the probability density function is the number of successes in the \(n\) trials, while the exponent of \(1 - p\) is the number of failures.
If \(\bs{X} = (X_1, X_2, \ldots,)\) is a Bernoulli trials process with parameter \(p\) then \(\bs{1} - \bs{X} = (1 - X_1, 1 - X_2, \ldots)\) is a Bernoulli trials sequence with parameter \(1 - p\).
Suppose that \(\bs{U} = (U_1, U_2, \ldots)\) is a sequence of independent random variables, each with the uniform distribution on the interval \([0, 1]\). For \(p \in [0, 1]\) and \(i \in \N_+\), let \(X_i(p) = \bs{1}(U_i \le p)\). Then \(\bs{X}(p) = \left( X_1(p), X_2(p), \ldots \right)\) is a Bernoulli trials process with probability \(p\).
Note that in the previous result, the Bernoulli trials processes for all possible values of the parameter \(p\) are defined on a common probability space. This type of construction is sometimes referred to as coupling. This result also shows how to simulate a Bernoulli trials process with random numbers. All of the other random process studied in this chapter are functions of the Bernoulli trials sequence, and hence can be simulated as well.
Moments
Let \(X\) be an indciator variable with \(\P(X = 1) = p\), where \(p \in [0, 1]\). Thus, \(X\) is the result of a generic Bernoulli trial and has the Bernoulli distribution with parameter \(p\). The following results give the mean, variance and some of the higher moments. A helpful fact is that if we take a positive power of an indicator variable, nothing happens; that is, \(X^n = X\) for \(n \gt 0\)
The mean and variance of \( X \) are
- \(\E(X) = p\)
- \( \var(X) = p (1 - p) \)
Proof
- \( \E(X) = 1 \cdot p ( 0 \cdot (1 - p) = p \)
- \( \var(X) = \E\left(X^2\right) - \left[\E(X)\right]^2 = \E(X) - \left[\E(X)\right]^2 = p - p^2 \)
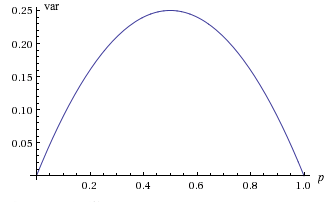
Note that the graph of \( \var(X) \), as a function of \( p \in [0, 1] \) is a parabola opening downward. In particular the largest value is \(\frac{1}{4}\) when \(p = \frac{1}{2}\), and the smallest value is 0 when \(p = 0\) or \(p = 1\). Of course, in the last two cases, \( X \) is deterministic, taking the single value 0 when \( p = 0 \) and the single value 1 when \( p = 1 \)
Suppose that \( p \in (0, 1) \). The skewness and kurtosis of \(X\) are
- \(\skw(X) = \frac{1 - 2 p}{\sqrt{p (1 - p)}}\)
- \(\kur(X) = -3 + \frac{1}{p (1 - p)}\)
The probability generating function of \(X\) is \( P(t) = \E\left(t^X\right) = (1 - p) + p t \) for \( t \in \R \).
Examples and Applications
Coins
As we noted earlier, the most obvious example of Bernoulli trials is coin tossing, where success means heads and failure means tails. The parameter \(p\) is the probability of heads (so in general, the coin is biased).
In the basic coin experiment, set \(n = 100\) and For each \(p \in \{0.1, 0.3, 0.5, 0.7, 0.9\}\) run the experiment and observe the outcomes.
Generic Examples
In a sense, the most general example of Bernoulli trials occurs when an experiment is replicated. Specifically, suppose that we have a basic random experiment and an event of interest \(A\). Suppose now that we create a compound experiment that consists of independent replications of the basic experiment. Define success on trial \(i\) to mean that event \(A\) occurred on the \(i\)th run, and define failure on trial \(i\) to mean that event \(A\) did not occur on the \(i\)th run. This clearly defines a Bernoulli trials process with parameter \(p = \P(A)\).
Bernoulli trials are also formed when we sample from a dichotomous population. Specifically, suppose that we have a population of two types of objects, which we will refer to as type 0 and type 1. For example, the objects could be persons, classified as male or female, or the objects could be components, classified as good or defective. We select \( n \) objects at random from the population; by definition, this means that each object in the population at the time of the draw is equally likely to be chosen. If the sampling is with replacement, then each object drawn is replaced before the next draw. In this case, successive draws are independent, so the types of the objects in the sample form a sequence of Bernoulli trials, in which the parameter \(p\) is the proportion of type 1 objects in the population. If the sampling is without replacement, then the successive draws are dependent, so the types of the objects in the sample do not form a sequence of Bernoulli trials. However, if the population size is large compared to the sample size, the dependence caused by not replacing the objects may be negligible, so that for all practical purposes, the types of the objects in the sample can be treated as a sequence of Bernoulli trials. Additional discussion of sampling from a dichotomous population is in the in the chapter Finite Sampling Models.
Suppose that a student takes a multiple choice test. The test has 10 questions, each of which has 4 possible answers (only one correct). If the student blindly guesses the answer to each question, do the questions form a sequence of Bernoulli trials? If so, identify the trial outcomes and the parameter \(p\).
Answer
Yes, probably so. The outcomes are correct and incorrect and \(p = \frac{1}{4}\).
Candidate \(A\) is running for office in a certain district. Twenty persons are selected at random from the population of registered voters and asked if they prefer candidate \(A\). Do the responses form a sequence of Bernoulli trials? If so identify the trial outcomes and the meaning of the parameter \(p\).
Answer
Yes, approximately, assuming that the number of registered voters is large, compared to the sample size of 20. The outcomes are prefer \(A\) and do not prefer \(A\); \(p\) is the proportion of voters in the entire district who prefer \(A\).
An American roulette wheel has 38 slots; 18 are red, 18 are black, and 2 are green. A gambler plays roulette 15 times, betting on red each time. Do the outcomes form a sequence of Bernoulli trials? If so, identify the trial outcomes and the parameter \(p\).
Answer
Yes, the outcomes are red and black, and \(p = \frac{18}{38}\).
Roulette is discussed in more detail in the chapter on Games of Chance.
Two tennis players play a set of 6 games. Do the games form a sequence of Bernoulli trials? If so, identify the trial outcomes and the meaning of the parameter \(p\).
Answer
No, probably not. The games are almost certainly dependent, and the win probably depends on who is serving and thus is not constant from game to game.
Reliability
Recall that in the standard model of structural reliability, a system is composed of \(n\) components that operate independently of each other. Let \(X_i\) denote the state of component \(i\), where 1 means working and 0 means failure. If the components are all of the same type, then our basic assumption is that the state vector \[ \bs{X} = (X_1, X_2, \ldots, X_n) \] is a sequence of Bernoulli trials. The state of the system, (again where 1 means working and 0 means failed) depends only on the states of the components, and thus is a random variable \[ Y = s(X_1, X_, \ldots, X_n) \] where \(s: \{0, 1\}^n \to \{0, 1\}\) is the structure function. Generally, the probability that a device is working is the reliability of the device, so the parameter \(p\) of the Bernoulli trials sequence is the common reliability of the components. By independence, the system reliability \(r\) is a function of the component reliability: \[ r(p) = \P_p(Y = 1), \quad p \in [0, 1] \] where we are emphasizing the dependence of the probability measure \(\P\) on the parameter \(p\). Appropriately enough, this function is known as the reliability function. Our challenge is usually to find the reliability function, given the structure function.
A series system is working if and only if each component is working.
- The state of the system is \(Y = X_1 X_2 \cdots X_n = \min\{X_1, X_2, \ldots, X_n\}\).
- The reliability function is \(r(p) = p^n\) for \(p \in [0, 1]\).
A parallel system is working if and only if at least one component is working.
- The state of the system is \(Y = 1 - (1 - X_1)(1 - X_2) \cdots (1 - X_n) = \max\{X_1, X_2, \ldots, X_n\}\).
- The reliability function is \(r(p) - 1 - (1 - p)^n\) for \(p \in [0, 1]\).
Recall that in some cases, the system can be represented as a graph or network. The edges represent the components and the vertices the connections between the components. The system functions if and only if there is a working path between two designated vertices, which we will denote by \(a\) and \(b\).
Find the reliability of the Wheatstone bridge network shown below (named for Charles Wheatstone).
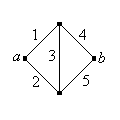
Answer
\(r(p) = p \, (2 \, p - p^2)^2 + (1 - p)(2 \, p^2 - p^4)\)
The Pooled Blood Test
Suppose that each person in a population, independently of all others, has a certain disease with probability \(p \in (0, 1)\). Thus, with respect to the disease, the persons in the population form a sequence of Bernoulli trials. The disease can be identified by a blood test, but of course the test has a cost.
For a group of \(k\) persons, we will compare two strategies. The first is to test the \(k\) persons individually, so that of course, \(k\) tests are required. The second strategy is to pool the blood samples of the \(k\) persons and test the pooled sample first. We assume that the test is negative if and only if all \(k\) persons are free of the disease; in this case just one test is required. On the other hand, the test is positive if and only if at least one person has the disease, in which case we then have to test the persons individually; in this case \(k + 1\) tests are required. Thus, let \(Y\) denote the number of tests required for the pooled strategy.
The number of tests \(Y\) has the following properties:
- \(\P(Y = 1) = (1 - p)^k, \quad \P(Y = k + 1) = 1 - (1 - p)^k\)
- \(\E(Y) = 1 + k \left[1 - (1 - p)^k\right]\)
- \(\var(Y) = k^2 (1 - p)^k \left[1 - (1 - p)^k\right]\)
In terms of expected value, the pooled strategy is better than the basic strategy if and only if \[ p \lt 1 - \left( \frac{1}{k} \right)^{1/k} \]
The graph of the critical value \(p_k = 1 - (1 / k)^{1/k}\) as a function of \(k \in [2, 20]\) is shown in the graph below:
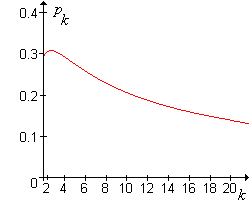
The critical value \(p_k\) satisfies the following properties:
- The maximum value of \(p_k\) occurs at \(k = 3\) and \(p_3 \approx 0.307\).
- \(p_k \to 0\) as \(k \to \infty\).
It follows that if \(p \ge 0.307\), pooling never makes sense, regardless of the size of the group \(k\). At the other extreme, if \(p\) is very small, so that the disease is quite rare, pooling is better unless the group size \(k\) is very large.
Now suppose that we have \(n\) persons. If \(k \mid n\) then we can partition the population into \(n / k\) groups of \(k\) each, and apply the pooled strategy to each group. Note that \(k = 1\) corresponds to individual testing, and \(k = n\) corresponds to the pooled strategy on the entire population. Let \(Y_i\) denote the number of tests required for group \(i\).
The random variables \((Y_1, Y_2, \ldots, Y_{n/k})\) are independent and each has the distribution given above.
The total number of tests required for this partitioning scheme is \(Z_{n,k} = Y_1 + Y_2 + \cdots + Y_{n/k}\).
The expected total number of tests is \[ \E(Z_{n,k}) = \begin{cases} n, & k = 1 \\ n \left[ \left(1 + \frac{1}{k} \right) - (1 - p)^k \right], & k \gt 1 \end{cases} \]
The variance of the total number of tests is \[ \var(Z_{n,}) = \begin{cases} 0, & k = 1 \\ n \, k \, (1 - p)^k \left[ 1 - (1 - p)^k \right], & k \gt 1 \end{cases} \]
Thus, in terms of expected value, the optimal strategy is to group the population into \(n / k\) groups of size \(k\), where \(k\) minimizes the expected value function above. It is difficult to get a closed-form expression for the optimal value of \(k\), but this value can be determined numerically for specific \(n\) and \(p\).
For the following values of \(n\) and \(p\), find the optimal pooling size \(k\) and the expected number of tests. (Restrict your attention to values of \(k\) that divide \(n\).)
- \(n = 100\), \(p = 0.01\)
- \(n = 1000\), \(p = 0.05\)
- \(n = 1000\), \(p = 0.001\)
Answer
- \(k = 10\), \(\E(Y_k) = 19.56\)
- \(k = 5\), \(\E(Y_k) = 426.22\)
- \(k = 40\), \(\E(Y_k) = 64.23\)
If \(k\) does not divide \(n\), then we could divide the population of \(n\) persons into \(\lfloor n / k \rfloor\) groups of \(k\) each and one remainder
group with \(n \mod k\) members. This clearly complicates the analysis, but does not introduce any new ideas, so we will leave this extension to the interested reader.