
4.3: Variance
- Page ID
- 10158

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Recall the expected value of a real-valued random variable is the mean of the variable, and is a measure of the center of the distribution. Recall also that by taking the expected value of various transformations of the variable, we can measure other interesting characteristics of the distribution. In this section, we will study expected values that measure the spread of the distribution about the mean.
Basic Theory
Definitions and Interpretations
As usual, we start with a random experiment modeled by a probability space \((\Omega, \mathscr F, \P)\). So to review, \(\Omega\) is the set of outcomes, \(\mathscr F\) the collection of events, and \(\P\) the probability measure on the sample space \((\Omega, \mathscr F)\). Suppose that \(X\) is a random variable for the experiment, taking values in \(S \subseteq \R\). Recall that \( \E(X) \), the expected value (or mean) of \(X\) gives the center of the distribution of \(X\).
The variance and standard deviation of \( X \) are defined by
- \( \var(X) = \E\left(\left[X - \E(X)\right]^2\right) \)
- \( \sd(X) = \sqrt{\var(X)} \)
Implicit in the definition is the assumption that the mean \( \E(X) \) exists, as a real number. If this is not the case, then \( \var(X) \) (and hence also \( \sd(X) \)) are undefined. Even if \( \E(X) \) does exist as a real number, it's possible that \( \var(X) = \infty \). For the remainder of our discussion of the basic theory, we will assume that expected values that are mentioned exist as real numbers.
The variance and standard deviation of \(X\) are both measures of the spread of the distribution about the mean. Variance (as we will see) has nicer mathematical properties, but its physical unit is the square of that of \( X \). Standard deviation, on the other hand, is not as nice mathematically, but has the advantage that its physical unit is the same as that of \( X \). When the random variable \(X\) is understood, the standard deviation is often denoted by \(\sigma\), so that the variance is \(\sigma^2\).
Recall that the second moment of \(X\) about \(a \in \R\) is \(\E\left[(X - a)^2\right]\). Thus, the variance is the second moment of \(X\) about the mean \(\mu = \E(X)\), or equivalently, the second central moment of \(X\). In general, the second moment of \( X \) about \( a \in \R\) can also be thought of as the mean square error if the constant \( a \) is used as an estimate of \( X \). In addition, second moments have a nice interpretation in physics. If we think of the distribution of \(X\) as a mass distribution in \(\R\), then the second moment of \(X\) about \(a \in \R\) is the moment of inertia of the mass distribution about \(a\). This is a measure of the resistance of the mass distribution to any change in its rotational motion about \(a\). In particular, the variance of \(X\) is the moment of inertia of the mass distribution about the center of mass \(\mu\).

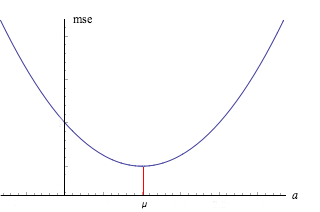
The mean square error (or equivalently the moment of inertia) about \( a \) is minimized when \( a = \mu \):
Let \( \mse(a) = \E\left[(X - a)^2\right] \) for \( a \in \R \). Then \( \mse \) is minimized when \( a = \mu \), and the minimum value is \( \sigma^2 \).
Proof
The relationship between measures of center and measures of spread is studied in more detail in the advanced section on vector spaces of random variables.
Properties
The following exercises give some basic properties of variance, which in turn rely on basic properties of expected value. As usual, be sure to try the proofs yourself before reading the ones in the text. Our first results are computational formulas based on the change of variables formula for expected value
Let \( \mu = \E(X) \).
- If \(X\) has a discrete distribution with probability density function \(f\), then \( \var(X) = \sum_{x \in S} (x - \mu)^2 f(x) \).
- If \(X\) has a continuous distribution with probability density function \(f\), then \( \var(X) = \int_S (x - \mu)^2 f(x) dx \)
Proof
- This follows from the discrete version of the change of variables formula.
- Similarly, this follows from the continuous version of the change of variables formula.
Our next result is a variance formula that is usually better than the definition for computational purposes.
\(\var(X) = \E(X^2) - [\E(X)]^2\).
Proof
Let \( \mu = \E(X) \). Using the linearity of expected value we have \[ \var(X) = \E[(X - \mu)^2] = \E(X^2 - 2 \mu X + \mu^2) = \E(X^2) - 2 \mu \E(X) + \mu^2 = \E(X^2) - 2 \mu^2 + \mu^2 = \E(X^2) - \mu^2 \]
Of course, by the change of variables formula, \( \E\left(X^2\right) = \sum_{x \in S} x^2 f(x) \) if \( X \) has a discrete distribution, and \( \E\left(X^2\right) = \int_S x^2 f(x) \, dx \) if \( X \) has a continuous distribution. In both cases, \( f \) is the probability density function of \( X \).
Variance is always nonnegative, since it's the expected value of a nonnegative random variable. Moreover, any random variable that really is random (not a constant) will have strictly positive variance.
The nonnegative property.
- \(\var(X) \ge 0\)
- \(\var(X) = 0\) if and only if \(\P(X = c) = 1\) for some constant \(c\) (and then of course, \(\E(X) = c\)).
Proof
These results follow from the basic positive property of expected value. Let \( \mu = \E(X) \). First \( (X - \mu)^2 \ge 0 \) with probability 1 so \( \E\left[(X - \mu)^2\right] \ge 0 \). In addition, \( \E\left[(X - \mu)^2\right] = 0 \) if and only if \( \P(X = \mu) = 1 \).
Our next result shows how the variance and standard deviation are changed by a linear transformation of the random variable. In particular, note that variance, unlike general expected value, is not a linear operation. This is not really surprising since the variance is the expected value of a nonlinear function of the variable: \( x \mapsto (x - \mu)^2 \).
If \(a, \, b \in \R\) then
- \(\var(a + b X) = b^2 \var(X)\)
- \(\sd(a + b X) = \left|b\right| \sd(X)\)
Proof
- Let \( \mu = \E(X) \). By linearity, \( \E(a + b X) = a + b \mu \). Hence \( \var(a + b X) = \E\left([(a + b X) - (a + b \mu)]^2\right) = \E\left[b^2 (X - \mu)^2\right] = b^2 \var(X) \).
- This result follows from (a) by taking square roots.
Recall that when \( b \gt 0 \), the linear transformation \( x \mapsto a + b x \) is called a location-scale transformation and often corresponds to a change of location and change of scale in the physical units. For example, the change from inches to centimeters in a measurement of length is a scale transformation, and the change from Fahrenheit to Celsius in a measurement of temperature is both a location and scale transformation. The previous result shows that when a location-scale transformation is applied to a random variable, the standard deviation does not depend on the location parameter, but is multiplied by the scale factor. There is a particularly important location-scale transformation.
Suppose that \( X \) is a random variable with mean \( \mu \) and variance \( \sigma^2 \). The random variable \( Z\) defined as follows is the standard score of \( X \). \[ Z = \frac{X - \mu}{\sigma} \]
- \( \E(Z) = 0 \)
- \( \var(Z) = 1 \)
Proof
- From the linearity of expected value, \( \E(Z) = \frac{1}{\sigma} [\E(X) - \mu] = 0 \)
- From the scaling property, \( \var(Z) = \frac{1}{\sigma^2} \var(X) = 1 \).
Since \(X\) and its mean and standard deviation all have the same physical units, the standard score \(Z\) is dimensionless. It measures the directed distance from \(\E(X)\) to \(X\) in terms of standard deviations.
Let \( Z \) denote the standard score of \( X \), and suppose that \( Y = a + b X \) where \( a, \, b \in \R \) and \( b \ne 0 \).
- If \( b \gt 0 \), the standard score of \( Y \) is \( Z \).
- If \( b \lt 0 \), the standard score of \( Y \) is \( -Z \).
Proof
\( E(Y) = a + b \E(X) \) and \( \sd(Y) = \left|b\right| \, \sd(X) \). Hence \[ \frac{Y - \E(Y)}{\sd(Y)} = \frac{b}{\left|b\right|} \frac{X - \E(X)}{\sd(X)} \]
As just noted, when \( b \gt 0 \), the variable \(Y = a + b X \) is a location-scale transformation and often corresponds to a change of physical units. Since the standard score is dimensionless, it's reasonable that the standard scores of \( X \) and \( Y \) are the same. Here is another standardized measure of dispersion:
Suppose that \(X\) is a random variable with \(\E(X) \ne 0\). The coefficient of variation is the ratio of the standard deviation to the mean: \[ \text{cv}(X) = \frac{\sd(X)}{\E(X)} \]
The coefficient of variation is also dimensionless, and is sometimes used to compare variability for random variables with different means. We will learn how to compute the variance of the sum of two random variables in the section on covariance.
Chebyshev's Inequality
Chebyshev's inequality (named after Pafnuty Chebyshev) gives an upper bound on the probability that a random variable will be more than a specified distance from its mean. This is often useful in applied problems where the distribution is unknown, but the mean and variance are known (at least approximately). In the following two results, suppose that \(X\) is a real-valued random variable with mean \(\mu = \E(X) \in \R\) and standard deviation \(\sigma = \sd(X) \in (0, \infty)\).
Chebyshev's inequality 1. \[ \P\left(\left|X - \mu\right| \ge t\right) \le \frac{\sigma^2}{t^2}, \quad t \gt 0 \]
Proof
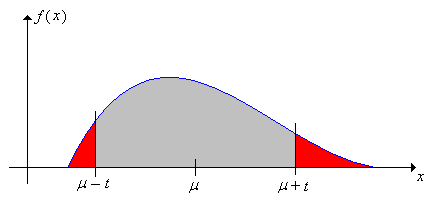
Here's an alternate version, with the distance in terms of standard deviation.
Chebyshev's inequality 2. \[\P\left(\left|X - \mu\right| \ge k \sigma\right) \le \frac{1}{k^2}, \quad k \gt 0 \]
Proof
Let \( t = k \sigma \) in the first version of Chebyshev's inequality.
The usefulness of the Chebyshev inequality comes from the fact that it holds for any distribution (assuming only that the mean and variance exist). The tradeoff is that for many specific distributions, the Chebyshev bound is rather crude. Note in particular that the first inequality is useless when \(t \le \sigma\), and the second inequality is useless when \( k \le 1 \), since 1 is an upper bound for the probability of any event. On the other hand, it's easy to construct a distribution for which Chebyshev's inequality is sharp for a specified value of \( t \in (0, \infty) \). Such a distribution is given in an exercise below.
Examples and Applications
As always, be sure to try the problems yourself before looking at the solutions and answers.
Indicator Variables
Suppose that \(X\) is an indicator variable with \(p = \P(X = 1)\), where \(p \in [0, 1]\). Then
- \(\E(X) = p\)
- \(\var(X) = p (1 - p)\)
Proof
- We proved this in the section on basic properties, although the result is so simple that we can do it again: \( \E(X) = 1 \cdot p + 0 \cdot (1 - p) = p \).
- Note that \( X^2 = X \) since \( X \) only takes values 0 and 1. Hence \( \E\left(X^2\right) = p \) and therefore \( \var(X) = p - p^2 = p (1 - p) \).
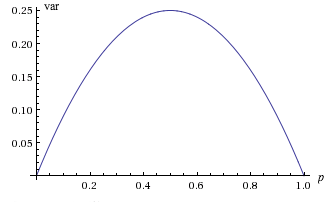
The graph of \(\var(X)\) as a function of \(p\) is a parabola, opening downward, with roots at 0 and 1. Thus the minimum value of \(\var(X)\) is 0, and occurs when \(p = 0\) and \(p = 1\) (when \( X \) is deterministic, of course). The maximum value is \(\frac{1}{4}\) and occurs when \(p = \frac{1}{2}\).
Uniform Distributions
Discrete uniform distributions are widely used in combinatorial probability, and model a point chosen at random from a finite set. The mean and variance have simple forms for the discrete uniform distribution on a set of evenly spaced points (sometimes referred to as a discrete interval):
Suppose that \(X\) has the discrete uniform distribution on \(\{a, a + h, \ldots, a + (n - 1) h\}\) where \( a \in \R \), \( h \in (0, \infty) \), and \( n \in \N_+ \). Let \( b = a + (n - 1) h \), the right endpoint. Then
- \(\E(X) = \frac{1}{2}(a + b)\).
- \(\var(X) = \frac{1}{12}(b - a)(b - a + 2 h)\).
Proof
- We proved this in the section on basic properties. Here it is again, using the formula for the sum of the first \( n - 1 \) positive integers: \[ \E(X) = \frac{1}{n} \sum_{i=0}^{n-1} (a + i h) = \frac{1}{n}\left(n a + h \frac{(n - 1) n}{2}\right) = a + \frac{(n - 1) h}{2} = \frac{a + b}{2} \]
- Note that \[ \E\left(X^2\right) = \frac{1}{n} \sum_{i=0}^{n-1} (a + i h)^2 = \frac{1}{n - 1} \sum_{i=0}^{n-1} \left(a^2 + 2 a h i + h^2 i^2\right)\] Using the formulas for the sum of the frist \( n - 1 \) positive integers, and the sum of the squares of the first \( n - 1 \) positive integers, we have \[ \E\left(X^2\right) = \frac{1}{n}\left[ n a^2 + 2 a h \frac{(n-1) n}{2} + h^2 \frac{(n - 1) n (2 n -1)}{6}\right] \] Using computational formula and simplifying gives the result.
Note that mean is simply the average of the endpoints, while the variance depends only on difference between the endpoints and the step size.
Open the special distribution simulator, and select the discrete uniform distribution. Vary the parameters and note the location and size of the mean \(\pm\) standard deviation bar in relation to the probability density function. For selected values of the parameters, run the simulation 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
Next, recall that the continuous uniform distribution on a bounded interval corresponds to selecting a point at random from the interval. Continuous uniform distributions arise in geometric probability and a variety of other applied problems.
Suppose that \(X\) has the continuous uniform distribution on the interval \([a, b]\) where \( a, \, b \in \R \) with \( a \lt b \). Then
- \( \E(X) = \frac{1}{2}(a + b) \)
- \( \var(X) = \frac{1}{12}(b - a)^2 \)
Proof
- \( \E(X) = \int_a^b x \frac{1}{b - a} \, dx = \frac{b^2 - a^2}{2 (b - a)} = \frac{a + b}{2} \)
- \( \E(X^2) = \int_a^b x^2 \frac{1}{b - a} = \frac{b^3 - a^3}{3 (b - a)} \). The variance result then follows from (a), the computational formula and simple algebra.
Note that the mean is the midpoint of the interval and the variance depends only on the length of the interval. Compare this with the results in the discrete case.
Open the special distribution simulator, and select the continuous uniform distribution. This is the uniform distribution the interval \( [a, a + w] \). Vary the parameters and note the location and size of the mean \(\pm\) standard deviation bar in relation to the probability density function. For selected values of the parameters, run the simulation 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
Dice
Recall that a fair die is one in which the faces are equally likely. In addition to fair dice, there are various types of crooked dice. Here are three:
- An ace-six flat die is a six-sided die in which faces 1 and 6 have probability \(\frac{1}{4}\) each while faces 2, 3, 4, and 5 have probability \(\frac{1}{8}\) each.
- A two-five flat die is a six-sided die in which faces 2 and 5 have probability \(\frac{1}{4}\) each while faces 1, 3, 4, and 6 have probability \(\frac{1}{8}\) each.
- A three-four flat die is a six-sided die in which faces 3 and 4 have probability \(\frac{1}{4}\) each while faces 1, 2, 5, and 6 have probability \(\frac{1}{8}\) each.
A flat die, as the name suggests, is a die that is not a cube, but rather is shorter in one of the three directions. The particular probabilities that we use (\( \frac{1}{4} \) and \( \frac{1}{8} \)) are fictitious, but the essential property of a flat die is that the opposite faces on the shorter axis have slightly larger probabilities that the other four faces. Flat dice are sometimes used by gamblers to cheat. In the following problems, you will compute the mean and variance for each of the various types of dice. Be sure to compare the results.
A standard, fair die is thrown and the score \(X\) is recorded. Sketch the graph of the probability density function and compute each of the following:
- \(\E(X)\)
- \(\var(X)\)
Answer
- \(\frac{7}{2}\)
- \(\frac{35}{12}\)
An ace-six flat die is thrown and the score \(X\) is recorded. Sketch the graph of the probability density function and compute each of the following:
- \(\E(X)\)
- \(\var(X)\)
Answer
- \(\frac{7}{2}\)
- \(\frac{15}{4}\)
A two-five flat die is thrown and the score \(X\) is recorded. Sketch the graph of the probability density function and compute each of the following:
- \(\E(X)\)
- \(\var(X)\)
Answer
- \(\frac{7}{2}\)
- \(\frac{11}{4}\)
A three-four flat die is thrown and the score \(X\) is recorded. Sketch the graph of the probability density function and compute each of the following:
- \(\E(X)\)
- \(\var(X)\)
Answer
- \(\frac{7}{2}\)
- \(\frac{9}{4}\)
In the dice experiment, select one die. For each of the following cases, note the location and size of the mean \(\pm\) standard deviation bar in relation to the probability density function. Run the experiment 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
- Fair die
- Ace-six flat die
- Two-five flat die
- Three-four flat die
The Poisson Distribution
Recall that the Poisson distribution is a discrete distribution on \( \N \) with probability density function \( f \) given by \[ f(n) = e^{-a} \, \frac{a^n}{n!}, \quad n \in \N\] where \(a \in (0, \infty)\) is a parameter. The Poisson distribution is named after Simeon Poisson and is widely used to model the number of random points
in a region of time or space; the parameter \(a\) is proportional to the size of the region. The Poisson distribution is studied in detail in the chapter on the Poisson Process.
Suppose that \(N\) has the Poisson distribution with parameter \(a\). Then
- \(\E(N) = a\)
- \(\var(N) = a\)
Proof
- We did this computation in the previous section. Here it is again: \[ \E(N) = \sum_{n=0}^\infty n e^{-a} \frac{a^n}{n!} = e^{-a} \sum_{n=1}^\infty \frac{a^n}{(n - 1)!} = e^{-a} a \sum_{n=1}^\infty \frac{a^{n-1}}{(n-1)!} = e^{-a} a e^a = a.\]
- First we compute the second factorial moment: \[ \E[N (N - 1)] = \sum_{n=1}^\infty n (n - 1) e^{-a} \frac{a^n}{n!} = \sum_{n=2}^\infty e^{-a} \frac{a^n}{(n - 2)!} = e^{-a} a^2 \sum_{n=2}^\infty \frac{a^{n-2}}{(n - 2)!} = a^2 e^{-a} e^a = a^2\] Hence, \( E\left(N^2\right) = \E[N(N - 1)] + \E(N) = a^2 + a \) and so \( \var(N) = (a^2 + a) - a^2 = a \).
Thus, the parameter of the Poisson distribution is both the mean and the variance of the distribution.
In the Poisson experiment, the parameter is \(a = r t\). Vary the parameter and note the size and location of the mean \(\pm\) standard deviation bar in relation to the probability density function. For selected values of the parameter, run the experiment 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
The Geometric Distribution
Recall that Bernoulli trials are independent trials each with two outcomes, which in the language of reliability, are called success and failure. The probability of success on each trial is \( p \in [0, 1] \). A separate chapter on Bernoulli Trials explores this random process in more detail. It is named for Jacob Bernoulli. If \( p \in (0, 1] \), the trial number \( N \) of the first success has the geometric distribution on \(\N_+\) with success parameter \(p\). The probability density function \( f \) of \( N \) is given by \[ f(n) = p (1 - p)^{n - 1}, \quad n \in \N_+ \]
Suppose that \(N\) has the geometric distribution on \(\N_+\) with success parameter \(p \in (0, 1]\). Then
- \(\E(N) = \frac{1}{p}\)
- \(\var(N) = \frac{1 - p}{p^2}\)
Proof
- We proved this in the section on basic properties. Here it is again: \[ \E(N) = \sum_{n=1}^\infty n p (1 - p)^{n-1} = -p \frac{d}{dp} \sum_{n=0}^\infty (1 - p)^n = -p \frac{d}{dp} \frac{1}{p} = p \frac{1}{p^2} = \frac{1}{p}\]
- First we compute the second factorial moment: \[ \E[N(N - 1)] = \sum_{n = 2}^\infty n (n - 1) (1 - p)^{n-1} p = p(1 - p) \frac{d^2}{dp^2} \sum_{n=0}^\infty (1 - p)^n = p (1 - p) \frac{d^2}{dp^2} \frac{1}{p} = p (1 - p) \frac{2}{p^3} = \frac{2 (1 - p)}{p^2}\] Hence \( \E(N^2) = \E[N(N - 1)] + \E(N) = 2 / p^2 - 1 / p \) and hence \( \var(X) = 2 / p^2 - 1 / p - 1 / p^2 = 1 / p^2 - 1 / p \).
Note that the variance is 0 when \(p = 1\), not surprising since \( X \) is deterministic in this case.
In the negative binomial experiment, set \(k = 1\) to get the geometric distribution . Vary \(p\) with the scroll bar and note the size and location of the mean \(\pm\) standard deviation bar in relation to the probability density function. For selected values of \(p\), run the experiment 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
Suppose that \(N\) has the geometric distribution with parameter \(p = \frac{3}{4}\). Compute the true value and the Chebyshev bound for the probability that \(N\) is at least 2 standard deviations away from the mean.
Answer
- \(\frac{1}{16}\)
- \(\frac{1}{4}\)
The Exponential Distribution
Recall that the exponential distribution is a continuous distribution on \( [0, \infty) \) with probability density function \( f \) given by \[ f(t) = r e^{-r t}, \quad t \in [0, \infty) \] where \(r \in (0, \infty)\) is the with rate parameter. This distribution is widely used to model failure times and other arrival times
. The exponential distribution is studied in detail in the chapter on the Poisson Process.
Suppose that \(T\) has the exponential distribution with rate parameter \(r\). Then
- \(\E(T) = \frac{1}{r}\).
- \(\var(T) = \frac{1}{r^2}\).
Proof
- We proved this in the section on basic properties. Here it is again, using integration by parts: \[ \E(T) = \int_0^\infty t r e^{-r t} \, dt = -t e^{-r t} \bigg|_0^\infty + \int_0^\infty e^{-r t} \, dt = 0 - \frac{1}{r} e^{-rt} \bigg|_0^\infty = \frac{1}{r} \]
- Integrating by parts again and using (a), we have \[ \E\left(T^2\right) = \int_0^\infty t^2 r e^{-r t} \, dt = -t^2 e^{-r t} \bigg|_0^\infty + \int_0^\infty 2 t e^{-r t} \, dt = 0 + \frac{2}{r^2} \] Hence \( \var(T) = \frac{2}{r^2} - \frac{1}{r^2} = \frac{1}{r^2} \)
Thus, for the exponential distribution, the mean and standard deviation are the same.
In the gamma experiment, set \(k = 1\) to get the exponential distribution. Vary \(r\) with the scroll bar and note the size and location of the mean \(\pm\) standard deviation bar in relation to the probability density function. For selected values of \(r\), run the experiment 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
Suppose that \(X\) has the exponential distribution with rate parameter \(r \gt 0\). Compute the true value and the Chebyshev bound for the probability that \(X\) is at least \(k\) standard deviations away from the mean.
Answer
- \(e^{-(k+1)}\)
- \(\frac{1}{k^2}\)
The Pareto Distribution
Recall that the Pareto distribution is a continuous distribution on \( [1, \infty) \) with probability density function \( f \) given by \[ f(x) = \frac{a}{x^{a + 1}}, \quad x \in [1, \infty) \] where \(a \in (0, \infty)\) is a parameter. The Pareto distribution is named for Vilfredo Pareto. It is a heavy-tailed distribution that is widely used to model financial variables such as income. The Pareto distribution is studied in detail in the chapter on Special Distributions.
Suppose that \(X\) has the Pareto distribution with shape parameter \(a\). Then
- \(\E(X) = \infty\) if \(0 \lt a \le 1\) and \(\E(X) = \frac{a}{a - 1}\) if \(1\lt a \lt \infty\)
- \(\var(X)\) is undefined if \(0 \lt a \le 1\), \(\var(X) = \infty\) if \(1 \lt a \le 2\), and \(\var(X) = \frac{a}{(a - 1)^2 (a - 2)}\) if \(2 \lt a \lt \infty\)
Proof
- We proved this in the section on basic properties. Here it is again: \[ \E(X) = \int_1^\infty x \frac{a}{x^{a+1}} \, dx = \int_1^\infty \frac{a}{x^a} \, dx = \frac{a}{-a + 1} x^{-a + 1} \bigg|_1^\infty = \begin{cases} \infty, & 0 \lt a \lt 1 \\ \frac{a}{a - 1}, & a \gt 1 \end{cases} \] When \( a = 1 \), \( \E(X) = \int_1^\infty \frac{1}{x} = \ln x \bigg|_1^\infty = \infty \)
- If \( 0 \lt a \le 1 \) then \( \E(X) = \infty \) and so \( \var(X) \) is undefined. On the other hand, \[ \E\left(X^2\right) = \int_1^\infty x^2 \frac{a}{x^{a+1}} \, dx = \int_1^\infty \frac{a}{x^{a-1}} \, dx = a x^{-a + 2} \bigg|_1^\infty = \begin{cases} \infty, & 0 \lt a \lt 2 \\ \frac{a}{a - 2}, & a \gt 2 \end{cases} \] When \( a = 2 \), \( \E\left(X^2\right) = \int_1^\infty \frac{2}{x} \, dx = \infty \). Hence \( \var(X) = \infty \) if \( 1 \lt a \le 2 \) and \( \var(X) = \frac{a}{a - 2} - \left(\frac{a}{a - 1}\right)^2 \) if \( a \gt 2 \).
In the special distribution simuator, select the Pareto distribution. Vary \(a\) with the scroll bar and note the size and location of the mean \(\pm\) standard deviation bar. For each of the following values of \(a\), run the experiment 1000 times and note the behavior of the empirical mean and standard deviation.
- \(a = 1\)
- \(a = 2\)
- \(a = 3\)
The Normal Distribution
Recall that the standard normal distribution is a continuous distribution on \( \R \) with probability density function \( \phi \) given by
\[ \phi(z) = \frac{1}{\sqrt{2 \pi}} e^{-\frac{1}{2} z^2}, \quad z \in \R \]
Normal distributions are widely used to model physical measurements subject to small, random errors and are studied in detail in the chapter on Special Distributions.
Suppose that \(Z\) has the standard normal distribution. Then
- \(\E(Z) = 0\)
- \(\var(Z) = 1\)
Proof
- We proved this in the section on basic properties. Here it is again: \[ \E(Z) = \int_{-\infty}^\infty z \frac{1}{\sqrt{2 \pi}} e^{-\frac{1}{2} z^2} \, dz = - \frac{1}{\sqrt{2 \pi}} e^{-\frac{1}{2} z^2} \bigg|_{-\infty}^\infty = 0 - 0 \]
- From (a), \( \var(Z) = \E(Z^2) = \int_{-\infty}^\infty z^2 \phi(z) \, dz \). Integrate by parts with \( u = z \) and \( dv = z \phi(z) \, dz \). Thus, \( du = dz \) and \( v = -\phi(z) \). Hence \[ \var(Z) = -z \phi(z) \bigg|_{-\infty}^\infty + \int_{-\infty}^\infty \phi(z) \, dz = 0 + 1 \]
More generally, for \(\mu \in \R\) and \(\sigma \in (0, \infty)\), recall that the normal distribution with location parameter \(\mu\) and scale parameter \(\sigma\) is a continuous distribution on \( \R \) with probability density function \( f \) given by \[ f(x) = \frac{1}{\sqrt{2 \pi} \sigma} \exp\left[-\frac{1}{2}\left(\frac{x - \mu}{\sigma}\right)^2\right], \quad x \in \R \] Moreover, if \( Z \) has the standard normal distribution, then \( X = \mu + \sigma Z \) has the normal distribution with location parameter \( \mu \) and scale parameter \( \sigma \). As the notation suggests, the location parameter is the mean of the distribution and the scale parameter is the standard deviation.
Suppose that \( X \) has the normal distribution with location parameter \(\mu\) and scale parameter \(\sigma\). Then
- \(\E(X) = \mu\)
- \(\var(X) = \sigma^2\)
Proof
We could use the probability density function, of course, but it's much better to use the representation of \( X \) in terms of the standard normal variable \( Z \), and use properties of expected value and variance.
- \( \E(X) = \mu + \sigma \E(Z) = \mu + 0 = \mu \)
- \( \var(X) = \sigma^2 \var(Z) = \sigma^2 \cdot 1 = \sigma^2 \).
So to summarize, if \( X \) has a normal distribution, then its standard score \( Z \) has the standard normal distribution.
In the special distribution simulator, select the normal distribution. Vary the parameters and note the shape and location of the mean \(\pm\) standard deviation bar in relation to the probability density function. For selected parameter values, run the experiment 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
Beta Distributions
The distributions in this subsection belong to the family of beta distributions, which are widely used to model random proportions and probabilities. The beta distribution is studied in detail in the chapter on Special Distributions.
Suppose that \(X\) has a beta distribution with probability density function \(f\). In each case below, graph \(f\) below and compute the mean and variance.
- \(f(x) = 6 x (1 - x)\) for \(x \in [0, 1]\)
- \(f(x) = 12 x^2 (1 - x)\) for \(x \in [0, 1]\)
- \(f(x) = 12 x (1 - x)^2\) for \(x \in [0, 1]\)
Answer
- \(\E(X) = \frac{1}{2}\), \(\var(X) = \frac{1}{20}\)
- \(\E(X) = \frac{3}{5}\), \(\var(X) = \frac{1}{25}\)
- \(\E(X) = \frac{2}{6}\), \(\var(X) = \frac{1}{25}\)
In the special distribution simulator, select the beta distribution. The parameter values below give the distributions in the previous exercise. In each case, note the location and size of the mean \(\pm\) standard deviation bar. Run the experiment 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
- \( a = 2 \), \( b = 2 \)
- \( a = 3 \), \( b = 2 \)
- \( a = 2 \), \( b = 3 \)
Suppose that a sphere has a random radius \(R\) with probability density function \(f\) given by \(f(r) = 12 r ^2 (1 - r)\) for \(r \in [0, 1]\). Find the mean and standard deviation of each of the following:
- The circumference \(C = 2 \pi R\)
- The surface area \(A = 4 \pi R^2\)
- The volume \(V = \frac{4}{3} \pi R^3\)
Answer
- \(\frac{6}{5} \pi\), \( \frac{2}{5} \pi \)
- \(\frac{8}{5} \pi\), \(\frac{2}{5} \sqrt{\frac{38}{7}} \pi\)
- \(\frac{8}{21} \pi\), \( \frac{8}{3} \sqrt{\frac{19}{1470}} \pi \)
Suppose that \(X\) has probability density function \(f\) given by \(f(x) = \frac{1}{\pi \sqrt{x (1 - x)}}\) for \(x \in (0, 1)\). Find
- \( \E(X) \)
- \( \var(X) \)
Answer
- \(\frac{1}{2}\)
- \(\frac{1}{8}\)
The particular beta distribution in the last exercise is also known as the (standard) arcsine distribution. It governs the last time that the Brownian motion process hits 0 during the time interval \( [0, 1] \). The arcsine distribution is studied in more generality in the chapter on Special Distributions.
Open the Brownian motion experiment and select the last zero. Note the location and size of the mean \( \pm \) standard deviation bar in relation to the probability density function. Run the simulation 1000 times and compare the empirical mean and standard deviation to the distribution mean and standard deviation.
Suppose that the grades on a test are described by the random variable \( Y = 100 X \) where \( X \) has the beta distribution with probability density function \( f \) given by \( f(x) = 12 x (1 - x)^2 \) for \( x \in [0, 1] \). The grades are generally low, so the teacher decides to curve
the grades using the transformation \( Z = 10 \sqrt{Y} = 100 \sqrt{X}\). Find the mean and standard deviation of each of the following variables:
- \( X \)
- \( Y \)
- \( Z \)
Answer
- \( \E(X) = \frac{2}{5} \), \( \sd(X) = \frac{1}{5} \)
- \( \E(Y) = 40 \), \( \sd(Y) = 20 \)
- \( \E(Z) = 60.95 \), \( \sd(Z) = 16.88 \)
Exercises on Basic Properties
Suppose that \(X\) is a real-valued random variable with \(\E(X) = 5\) and \(\var(X) = 4\). Find each of the following:
- \(\var(3 X - 2)\)
- \(\E(X^2)\)
Answer
- \(36\)
- \(29\)
Suppose that \(X\) is a real-valued random variable with \(\E(X) = 2\) and \(\E\left[X(X - 1)\right] = 8\). Find each of the following:
- \(\E(X^2)\)
- \(\var(X)\)
Answer
- \(10\)
- \(6\)
The expected value \(\E\left[X(X - 1)\right]\) is an example of a factorial moment.
Suppose that \(X_1\) and \(X_2\) are independent, real-valued random variables with \(\E(X_i) = \mu_i\) and \(\var(X_i) = \sigma_i^2\) for \(i \in \{1, 2\}\). Then
- \( \E\left(X_1 X_2\right) = \mu_1 \mu_2 \)
- \( \var\left(X_1 X_2\right) = \sigma_1^2 \sigma_2^2 + \sigma_1^2 \mu_2^2 + \sigma_2^2 \mu_1^2\)
Proof
- This is an important, basic result that was proved in the section on basic properties.
- Since \( X_1^2 \) and \( X_2^2 \) are also independent, we have \(\E\left(X_1^2 X_2^2\right) = \E\left(X_1^2\right) \E\left(X_2^2\right) = (\sigma_1^2 + \mu_1^2) (\sigma_2^2 + \mu_2^2) \). The result then follows from the computational formula and algebra.
Marilyn Vos Savant has an IQ of 228. Assuming that the distribution of IQ scores has mean 100 and standard deviation 15, find Marilyn's standard score.
Answer
\(z = 8.53\)
Fix \( t \in (0, \infty) \). Suppose that \( X \) is the discrete random variable with probability density function defined by \( \P(X = t) = \P(X = -t) = p \), \( \P(X = 0) = 1 - 2 p \), where \( p \in (0, \frac{1}{2}) \). Then equality holds in Chebyshev's inequality at \( t \).
Proof
Note that \( \E(X) = 0 \) and \( \var(X) = \E(X^2) = 2 p t^2 \). So \( \P(|X| \ge t) = 2 p \) and \( \sigma^2 / t^2 = 2 p \).