
6.3: Continuous Random Variables
- Page ID
- 3146

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)In this section we consider the properties of the expected value and the variance of a continuous random variable. These quantities are defined just as for discrete random variables and share the same properties.
Expected Value
Let \(X\) be a real-valued random variable with density function \(f(x)\). The expected value \(\mu=E(X)\) is defined by
\[
\mu=E(X)=\int_{-\infty}^{+\infty} x f(x) d x,
\]
provided the integral
\[
\int_{-\infty}^{+\infty}|x| f(x) d x
\]
is finite.
The reader should compare this definition with the corresponding one for discrete random variables in Section 6.1. Intuitively, we can interpret \(E(X)\), as we did in the previous sections, as the value that we should expect to obtain if we perform a large number of independent experiments and average the resulting values of \(X\).
We can summarize the properties of \(E(X)\) as follows (cf. Theorem 6.2).
If \(X\) and \(Y\) are real-valued random variables and \(c\) is any constant, then
\[
\begin{aligned}
E(X+Y) & =E(X)+E(Y) \\
E(c X) & =c E(X) .
\end{aligned}
\]
The proof is very similar to the proof of Theorem 6.2 , and we omit it.
More generally, if \(X_1, X_2, \ldots, X_n\) are \(n\) real-valued random variables, and \(c_1, c_2\), \(\ldots, c_n\) are \(n\) constants, then
\[
E\left(c_1 X_1+c_2 X_2+\cdots+c_n X_n\right)=c_1 E\left(X_1\right)+c_2 E\left(X_2\right)+\cdots+c_n E\left(X_n\right) .
\]
Let \(X\) be uniformly distributed on the interval \([0,1]\). Then
\[
E(X)=\int_0^1 x d x=1 / 2
\]
It follows that if we choose a large number \(N\) of random numbers from \([0,1]\) and take the average, then we can expect that this average should be close to the expected value of \(1 / 2\).
Let \(Z=(x, y)\) denote a point chosen uniformly and randomly from the unit disk, as in the dart game in Example 2.8 and let \(X=\left(x^2+y^2\right)^{1 / 2}\) be the distance from \(Z\) to the center of the disk. The density function of \(X\) can easily be shown to equal \(f(x)=2 x\), so by the definition of expected value,
\[
\begin{aligned}
E(X) & =\int_0^1 x f(x) d x \\
& =\int_0^1 x(2 x) d x \\
& =\frac{2}{3} .
\end{aligned}
\]
In the example of the couple meeting at the Inn (Example 2.16), each person arrives at a time which is uniformly distributed between 5:00 and 6:00 PM. The random variable \(Z\) under consideration is the length of time the first person has to wait until the second one arrives. It was shown that
\[
f_Z(z)=2(1-z)
\]
for \(0 \leq z \leq 1\). Hence,
\[\begin{aligned}
E(Z)&=\int_0^1 z f_Z(z) d z\\
&=\int_0^1 2 z(1-z) d z \\
&=\left[z^2-\frac{2}{3} z^3\right]_0^1 \\
&=\frac{1}{3}
\end{aligned}\]
Expectation of a Function of a Random Variable
Suppose that \(X\) is a real-valued random variable and \(\phi(x)\) is a continuous function from \(\mathbf{R}\) to \(\mathbf{R}\). The following theorem is the continuous analogue of Theorem 6.1.
If \(X\) is a real-valued random variable and if \(\phi: \mathbf{R} \rightarrow \mathbf{R}\) is a continuous real-valued function with domain \([a, b]\), then
\[
E(\phi(X))=\int_{-\infty}^{+\infty} \phi(x) f_X(x) d x
\]
provided the integral exists.
For a proof of this theorem, see Ross. \({ }^{1}\)
Expectation of the Product of Two Random Variables
In general, it is not true that \(E(X Y)=E(X) E(Y)\), since the integral of a product is not the product of integrals. But if \(X\) and \(Y\) are independent, then the expectations multiply.
Let \(X\) and \(Y\) be independent real-valued continuous random variables with finite expected values. Then we have
\[
E(X Y)=E(X) E(Y) .
\]
- Proof
-
We will prove this only in the case that the ranges of \(X\) and \(Y\) are contained in the intervals \([a, b]\) and \([c, d]\), respectively. Let the density functions of \(X\) and \(Y\) be denoted by \(f_X(x)\) and \(f_Y(y)\), respectively. Since \(X\) and \(Y\) are independent, the joint density function of \(X\) and \(Y\) is the product of the individual density functions. Hence
\[
\begin{aligned}
E(X Y) & =\int_a^b \int_c^d x y f_X(x) f_Y(y) d y d x \\
& =\int_a^b x f_X(x) d x \int_c^d y f_Y(y) d y \\
& =E(X) E(Y) .
\end{aligned}
\]
The proof in the general case involves using sequences of bounded random variables that approach \(X\) and \(Y\), and is somewhat technical, so we will omit it.In the same way, one can show that if \(X_1, X_2, \ldots, X_n\) are \(n\) mutually independent real-valued random variables, then
\[
E\left(X_1 X_2 \cdots X_n\right)=E\left(X_1\right) E\left(X_2\right) \cdots E\left(X_n\right) .
\]
Let \(Z=(X, Y)\) be a point chosen at random in the unit square. Let \(A=X^2\) and \(B=Y^2\). Then Theorem 4.3 implies that \(A\) and \(B\) are independent. Using Theorem , the expectations of \(A\) and \(B\) are easy to calculate:
\[
\begin{aligned}
E(A)=E(B) & =\int_0^1 x^2 d x \\
& =\frac{1}{3} .
\end{aligned}
\]
Using Theorem , the expectation of \(A B\) is just the product of \(E(A)\) and \(E(B)\), or \(1 / 9\). The usefulness of this theorem is demonstrated by noting that it is quite a bit more difficult to calculate \(E(A B)\) from the definition of expectation. One finds that the density function of \(A B\) is
\[
f_{A B}(t)=\frac{-\log (t)}{4 \sqrt{t}},
\]
so
\[
\begin{aligned}
E(A B) & =\int_0^1 t f_{A B}(t) d t \\
& =\frac{1}{9} .
\end{aligned}
\]
Again let \(Z=(X, Y)\) be a point chosen at random in the unit square, and let \(W=X+Y\). Then \(Y\) and \(W\) are not independent, and we have
\[
\begin{aligned}
E(Y) & =\frac{1}{2}, \\
E(W) & =1, \\
E(Y W) & =E\left(X Y+Y^2\right)=E(X) E(Y)+\frac{1}{3}=\frac{7}{12} \neq E(Y) E(W) .
\end{aligned}
\]
We turn now to the variance.
Variance
Let \(X\) be a real-valued random variable with density function \(f(x)\). The variance \(\sigma^2=V(X)\) is defined by
\[
\sigma^2=V(X)=E\left((X-\mu)^2\right) .
\]
The next result follows easily from Theorem 6.1.1. There is another way to calculate the variance of a continuous random variable, which is usually slightly easier. It is given in Theorem .
If \(X\) is a real-valued random variable with \(E(X)=\mu\), then
\[
\sigma^2=\int_{-\infty}^{\infty}(x-\mu)^2 f(x) d x .
\]
The properties listed in the next three theorems are all proved in exactly the same way that the corresponding theorems for discrete random variables were proved in Section 6.2.
If \(X\) is a real-valued random variable defined on \(\Omega\) and \(c\) is any constant, then (cf. Theorem 6.2.7)
\[
\begin{aligned}
V(c X) & =c^2 V(X), \\
V(X+c) & =V(X) .
\end{aligned}
\]
If \(X\) is a real-valued random variable with \(E(X)=\mu\), then (cf. Theorem 6.2.6)
\[
V(X)=E\left(X^2\right)-\mu^2 .
\]
If \(X\) and \(Y\) are independent real-valued random variables on \(\Omega\), then (cf. Theorem 6.2.8)
\[
V(X+Y)=V(X)+V(Y) .
\]
If \(X\) is uniformly distributed on \([0,1]\), then, using Theorem , we have
\[
V(X)=\int_0^1\left(x-\frac{1}{2}\right)^2 d x=\frac{1}{12} .
\]
Let \(X\) be an exponentially distributed random variable with parameter \(\lambda\). Then the density function of \(X\) is
\[
f_X(x)=\lambda e^{-\lambda x} .
\]
From the definition of expectation and integration by parts, we have
\[
\begin{aligned}
E(X) & =\int_0^{\infty} x f_X(x) d x \\
& =\lambda \int_0^{\infty} x e^{-\lambda x} d x \\
& =-\left.x e^{-\lambda x}\right|_0 ^{\infty}+\int_0^{\infty} e^{-\lambda x} d x \\
& =0+\left.\frac{e^{-\lambda x}}{-\lambda}\right|_0 ^{\infty}=\frac{1}{\lambda} .
\end{aligned}
\]
Similarly, using Theorems and , we have
\[
\begin{aligned}
V(X) & =\int_0^{\infty} x^2 f_X(x) d x-\frac{1}{\lambda^2} \\
& =\lambda \int_0^{\infty} x^2 e^{-\lambda x} d x-\frac{1}{\lambda^2} \\
& =-\left.x^2 e^{-\lambda x}\right|_0 ^{\infty}+2 \int_0^{\infty} x e^{-\lambda x} d x-\frac{1}{\lambda^2} \\
& =-\left.x^2 e^{-\lambda x}\right|_0 ^{\infty}-\left.\frac{2 x e^{-\lambda x}}{\lambda}\right|_0 ^{\infty}-\left.\frac{2}{\lambda^2} e^{-\lambda x}\right|_0 ^{\infty}-\frac{1}{\lambda^2}=\frac{2}{\lambda^2}-\frac{1}{\lambda^2}=\frac{1}{\lambda^2} .
\end{aligned}
\]
In this case, both \(E(X)\) and \(V(X)\) are finite if \(\lambda>0\).
Let \(Z\) be a standard normal random variable with density function
\[
f_Z(x)=\frac{1}{\sqrt{2 \pi}} e^{-x^2 / 2} .
\]
Since this density function is symmetric with respect to the \(y\)-axis, then it is easy to show that
\[
\int_{-\infty}^{\infty} x f_Z(x) d x
\]
has value 0 . The reader should recall however, that the expectation is defined to be the above integral only if the integral
\[
\int_{-\infty}^{\infty}|x| f_Z(x) d x
\]
is finite. This integral equals
\[
2 \int_0^{\infty} x f_Z(x) d x
\]
which one can easily show is finite. Thus, the expected value of \(Z\) is 0 .
To calculate the variance of \(Z\), we begin by applying Theorem :
\[
V(Z)=\int_{-\infty}^{+\infty} x^2 f_Z(x) d x-\mu^2
\]
If we write \(x^2\) as \(x \cdot x\), and integrate by parts, we obtain
\[
\left.\frac{1}{\sqrt{2 \pi}}\left(-x e^{-x^2 / 2}\right)\right|_{-\infty} ^{+\infty}+\frac{1}{\sqrt{2 \pi}} \int_{-\infty}^{+\infty} e^{-x^2 / 2} d x .
\]
The first summand above can be shown to equal 0 , since as \(x \rightarrow \pm \infty, e^{-x^2 / 2}\) gets small more quickly than \(x\) gets large. The second summand is just the standard normal density integrated over its domain, so the value of this summand is 1 . Therefore, the variance of the standard normal density equals 1 .
Now let \(X\) be a (not necessarily standard) normal random variable with parameters \(\mu\) and \(\sigma\). Then the density function of \(X\) is
\[
f_X(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-(x-\mu)^2 / 2 \sigma^2} .
\]
We can write \(X=\sigma Z+\mu\), where \(Z\) is a standard normal random variable. Since \(E(Z)=0\) and \(V(Z)=1\) by the calculation above, Theorems 6.10 and 6.14 imply that
\[
\begin{aligned}
E(X) & =E(\sigma Z+\mu)=\mu, \\
V(X) & =V(\sigma Z+\mu)=\sigma^2 .
\end{aligned}
\]
Let \(X\) be a continuous random variable with the Cauchy density function
\[
f_X(x)=\frac{a}{\pi} \frac{1}{a^2+x^2} .
\]
Then the expectation of \(X\) does not exist, because the integral
\[
\frac{a}{\pi} \int_{-\infty}^{+\infty} \frac{|x| d x}{a^2+x^2}
\]
diverges. Thus the variance of \(X\) also fails to exist. Densities whose variance is not defined, like the Cauchy density, behave quite differently in a number of important respects from those whose variance is finite. We shall see one instance of this difference in Section 8.2.
Independent Trials
If \(X_1, X_2, \ldots, X_n\) is an independent trials process of real-valued random variables, with \(E\left(X_i\right)=\mu\) and \(V\left(X_i\right)=\sigma^2\), and if
\[
\begin{array}{l}
S_n=X_1+X_2+\cdots+X_n, \\
A_n=\frac{S_n}{n},
\end{array}
\]
then
\[
\begin{aligned}
E\left(S_n\right) & =n \mu, \\
E\left(A_n\right) & =\mu, \\
V\left(S_n\right) & =n \sigma^2, \\
V\left(A_n\right) & =\frac{\sigma^2}{n} .
\end{aligned}
\]
It follows that if we set
\[
S_n^*=\frac{S_n-n \mu}{\sqrt{n \sigma^2}},
\]
then
\[
\begin{array}{l}
E\left(S_n^*\right)=0, \\
V\left(S_n^*\right)=1 .
\end{array}
\]
We say that \(S_n^*\) is a standardized version of \(S_n\) (see Exercise 12 in Section 6.2).
Queues
Let us consider again the queueing problem, that is, the problem of the customers waiting in a queue for service (see Example 5.7). We suppose again that customers join the queue in such a way that the time between arrivals is an exponentially distributed random variable \(X\) with density function
\[
f_X(t)=\lambda e^{-\lambda t} .
\]
Then the expected value of the time between arrivals is simply \(1 / \lambda\) (see Example 6.26), as was stated in Example 5.7. The reciprocal \(\lambda\) of this expected value is often referred to as the arrival rate. The service time of an individual who is first in line is defined to be the amount of time that the person stays at the head of the line before leaving. We suppose that the customers are served in such a way that the service time is another exponentially distributed random variable \(Y\) with density function
\[
f_X(t)=\mu e^{-\mu t} .
\]
Then the expected value of the service time is
\[
E(X)=\int_0^{\infty} t f_X(t) d t=\frac{1}{\mu} .
\]
The reciprocal \(\mu\) if this expected value is often referred to as the service rate
We expect on grounds of our everyday experience with queues that if the service rate is greater than the arrival rate, then the average queue size will tend to stabilize, but if the service rate is less than the arrival rate, then the queue will tend to increase in length without limit (see Figure 5.7). The simulations in Example 5.7 tend to bear out our everyday experience. We can make this conclusion more precise if we introduce the traffic intensity as the product
\[
\rho=(\text { arrival rate })(\text { average service time })=\frac{\lambda}{\mu}=\frac{1 / \mu}{1 / \lambda} .
\]
The traffic intensity is also the ratio of the average service time to the average time between arrivals. If the traffic intensity is less than 1 the queue will perform reasonably, but if it is greater than 1 the queue will grow indefinitely large. In the critical case of \(\rho=1\), it can be shown that the queue will become large but there will always be times at which the queue is empty. \({ }^{22}\)
In the case that the traffic intensity is less than 1 we can consider the length of the queue as a random variable \(Z\) whose expected value is finite,
\[
E(Z)=N .
\]
The time spent in the queue by a single customer can be considered as a random variable \(W\) whose expected value is finite,
\[
E(W)=T .
\]
Then we can argue that, when a customer joins the queue, he expects to find \(N\) people ahead of him, and when he leaves the queue, he expects to find \(\lambda T\) people behind him. Since, in equilibrium, these should be the same, we would expect to find that
\[
N=\lambda T .
\]
This last relationship is called Little's law for queues. \({ }^{23}\) We will not prove it here. A proof may be found in Ross. \({ }^{24}\) Note that in this case we are counting the waiting time of all customers, even those that do not have to wait at all. In our simulation in Section 4.2, we did not consider these customers.
If we knew the expected queue length then we could use Little's law to obtain the expected waiting time, since
\[
T=\frac{N}{\lambda} .
\]
The queue length is a random variable with a discrete distribution. We can estimate this distribution by simulation, keeping track of the queue lengths at the times at which a customer arrives. We show the result of this simulation (using the program Queue) in Figure \(\PageIndex{1}\).
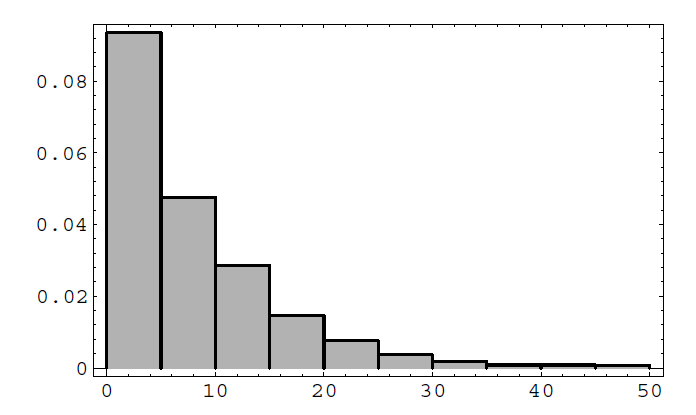
We note that the distribution appears to be a geometric distribution. In the study of queueing theory it is shown that the distribution for the queue length in equilibrium is indeed a geometric distribution with
\[
s_j=(1-\rho) \rho^j \quad \text { for } j=0,1,2, \ldots,
\]
if \(\rho<1\). The expected value of a random variable with this distribution is
\[
N=\frac{\rho}{(1-\rho)}
\]
(see Example 6.4). Thus by Little's result the expected waiting time is
\[
T=\frac{\rho}{\lambda(1-\rho)}=\frac{1}{\mu-\lambda},
\]
where \(\mu\) is the service rate, \(\lambda\) the arrival rate, and \(\rho\) the traffic intensity.
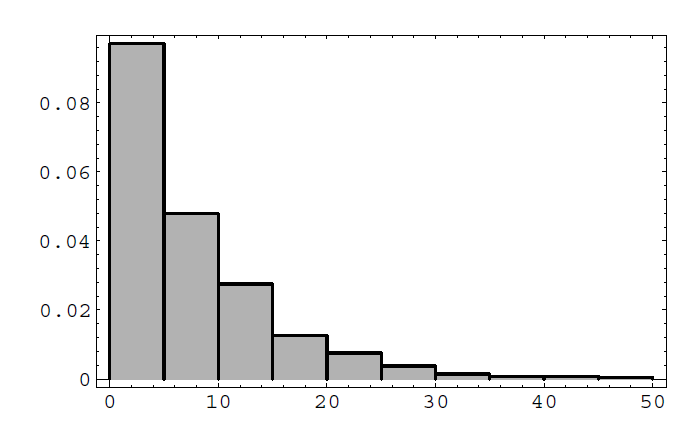
In our simulation, the arrival rate is 1 and the service rate is 1.1. Thus, the traffic intensity is \(1 / 1.1=10 / 11\), the expected queue size is
\[
\frac{10 / 11}{(1-10 / 11)}=10
\]
and the expected waiting time is
\[
\frac{1}{1.1-1}=10
\]
In our simulation the average queue size was 8.19 and the average waiting time was 7.37. In Figure \(\PageIndex{2}\), we show the histogram for the waiting times. This histogram suggests that the density for the waiting times is exponential with parameter \(\mu-\lambda\), and this is the case.
\({ }^{1}\) Ross, A First Course in Probability, (New York: Macmillan, 1984), pgs. 241-245
\({ }^{2}\) L. Kleinrock, Queueing Systems, vol. 2 (New York: John Wiley and Sons, 1975).
\({ }^{3}\) ibid., p. 17.
\({ }^{4}\) S. M. Ross, Applied Probability Models with Optimization Applications, (San Francisco:Holden-Day, 1970)
Exercises
Exercise \(\PageIndex{1}\)
Let \(X\) be a random variable with range \([-1,1]\) and let \(f_X(x)\) be the density function of \(X\). Find \(\mu(X)\) and \(\sigma^2(X)\) if, for \(|x|<1\),
(a) \(f_X(x)=1 / 2\).
(b) \(f_X(x)=|x|\).
(c) \(f_X(x)=1-|x|\).
(d) \(f_X(x)=(3 / 2) x^2\).
Exercise \(\PageIndex{2}\)
Let \(X\) be a random variable with range \([-1,1]\) and \(f_X\) its density function. Find \(\mu(X)\) and \(\sigma^2(X)\) if, for \(|x|>1, f_X(x)=0\), and for \(|x|<1\),
(a) \(f_X(x)=(3 / 4)\left(1-x^2\right)\).
(b) \(f_X(x)=(\pi / 4) \cos (\pi x / 2)\).
(c) \(f_X(x)=(x+1) / 2\).
(d) \(f_X(x)=(3 / 8)(x+1)^2\).
Exercise \(\PageIndex{3}\)
The lifetime, measure in hours, of the ACME super light bulb is a random variable \(T\) with density function \(f_T(t)=\lambda^2 t e^{-\lambda t}\), where \(\lambda=.05\). What is the expected lifetime of this light bulb? What is its variance?
Exercise \(\PageIndex{4}\)
Let \(X\) be a random variable with range \([-1,1]\) and density function \(f_X(x)=\) \(a x+b\) if \(|x|<1\).
(a) Show that if \(\int_{-1}^{+1} f_X(x) d x=1\), then \(b=1 / 2\).
(b) Show that if \(f_X(x) \geq 0\), then \(-1 / 2 \leq a \leq 1 / 2\).
(c) Show that \(\mu=(2 / 3) a\), and hence that \(-1 / 3 \leq \mu \leq 1 / 3\).
(d) Show that \(\sigma^2(X)=(2 / 3) b-(4 / 9) a^2=1 / 3-(4 / 9) a^2\).
Exercise \(\PageIndex{5}\)
Let \(X\) be a random variable with range \([-1,1]\) and density function \(f_X(x)=\) \(a x^2+b x+c\) if \(|x|<1\) and 0 otherwise.
(a) Show that \(2 a / 3+2 c=1\) (see Exercise 4).
(b) Show that \(2 b / 3=\mu(X)\).
(c) Show that \(2 a / 5+2 c / 3=\sigma^2(X)\).
(d) Find \(a, b\), and \(c\) if \(\mu(X)=0, \sigma^2(X)=1 / 15\), and sketch the graph of \(f_X\).
(e) Find \(a, b\), and \(c\) if \(\mu(X)=0, \sigma^2(X)=1 / 2\), and sketch the graph of \(f_X\).
Exercise \(\PageIndex{6}\)
Let \(T\) be a random variable with range \([0, \infty]\) and \(f_T\) its density function. Find \(\mu(T)\) and \(\sigma^2(T)\) if, for \(t<0, f_T(t)=0\), and for \(t>0\),
(a) \(f_T(t)=3 e^{-3 t}\).
(b) \(f_T(t)=9 t e^{-3 t}\).
(c) \(f_T(t)=3 /(1+t)^4\).
Exercise \(\PageIndex{7}\)
Let \(X\) be a random variable with density function \(f_X\). Show, using elementary calculus, that the function
\[
\phi(a)=E\left((X-a)^2\right)
\]
takes its minimum value when \(a=\mu(X)\), and in that case \(\phi(a)=\sigma^2(X)\).
Exercise \(\PageIndex{8}\)
Let \(X\) be a random variable with mean \(\mu\) and variance \(\sigma^2\). Let \(Y=a X^2+\) \(b X+c\). Find the expected value of \(Y\).
Exercise \(\PageIndex{9}\)
Let \(X, Y\), and \(Z\) be independent random variables, each with mean \(\mu\) and variance \(\sigma^2\).
(a) Find the expected value and variance of \(S=X+Y+Z\).
(b) Find the expected value and variance of \(A=(1 / 3)(X+Y+Z)\).
(c) Find the expected value of \(S^2\) and \(A^2\).
Exercise \(\PageIndex{10}\)
Let \(X\) and \(Y\) be independent random variables with uniform density functions on \([0,1]\). Find
(a) \(E(|X-Y|)\).
(b) \(E(\max (X, Y))\).
(c) \(E(\min (X, Y))\).
(d) \(E\left(X^2+Y^2\right)\).
(e) \(E\left((X+Y)^2\right)\).
Exercise \(\PageIndex{11}\)
The Pilsdorff Beer Company runs a fleet of trucks along the 100 mile road from Hangtown to Dry Gulch. The trucks are old, and are apt to break down at any point along the road with equal probability. Where should the company locate a garage so as to minimize the expected distance from a typical breakdown to the garage? In other words, if \(X\) is a random variable giving the location of the breakdown, measured, say, from Hangtown, and \(b\) gives the location of the garage, what choice of \(b\) minimizes \(E(|X-b|)\) ? Now suppose \(X\) is not distributed uniformly over \([0,100]\), but instead has density function \(f_X(x)=2 x / 10,000\). Then what choice of \(b\) minimizes \(E(|X-b|)\) ?
Exercise \(\PageIndex{12}\)
Find \(E\left(X^Y\right)\), where \(X\) and \(Y\) are independent random variables which are uniform on \([0,1]\). Then verify your answer by simulation.
Exercise \(\PageIndex{13}\)
Let \(X\) be a random variable that takes on nonnegative values and has distribution function \(F(x)\). Show that
\[
E(X)=\int_0^{\infty}(1-F(x)) d x .
\]
Hint: Integrate by parts.
Illustrate this result by calculating \(E(X)\) by this method if \(X\) has an exponential distribution \(F(x)=1-e^{-\lambda x}\) for \(x \geq 0\), and \(F(x)=0\) otherwise.
Exercise \(\PageIndex{14}\)
Let \(X\) be a continuous random variable with density function \(f_X(x)\). Show that if
\[
\int_{-\infty}^{+\infty} x^2 f_X(x) d x<\infty
\]
then
\[
\int_{-\infty}^{+\infty}|x| f_X(x) d x<\infty .
\]
Hint: Except on the interval \([-1,1]\), the first integrand is greater than the second integrand.
Exercise \(\PageIndex{15}\)
Let \(X\) be a random variable distributed uniformly over \([0,20]\). Define a new random variable \(Y\) by \(Y=\lfloor X\rfloor\) (the greatest integer in \(X\) ). Find the expected value of \(Y\). Do the same for \(Z=\lfloor X+.5\rfloor\). Compute \(E(|X-Y|)\) and \(E(|X-Z|)\). (Note that \(Y\) is the value of \(X\) rounded off to the nearest smallest integer, while \(Z\) is the value of \(X\) rounded off to the nearest integer. Which method of rounding off is better? Why?)
Exercise \(\PageIndex{16}\)
Assume that the lifetime of a diesel engine part is a random variable \(X\) with density \(f_X\). When the part wears out, it is replaced by another with the same density. Let \(N(t)\) be the number of parts that are used in time \(t\). We want to study the random variable \(N(t) / t\). Since parts are replaced on the average every \(E(X)\) time units, we expect about \(t / E(X)\) parts to be used in time \(t\). That is, we expect that
\[
\lim _{t \rightarrow \infty} E\left(\frac{N(t)}{t}\right)=\frac{1}{E(X)} .
\]
This result is correct but quite difficult to prove. Write a program that will allow you to specify the density \(f_X\), and the time \(t\), and simulate this experiment to find \(N(t) / t\). Have your program repeat the experiment 500 times and plot a bar graph for the random outcomes of \(N(t) / t\). From this data, estimate \(E(N(t) / t)\) and compare this with \(1 / E(X)\). In particular, do this for \(t=100\) with the following two densities:
(a) \(f_X=e^{-t}\).
(b) \(f_X=t e^{-t}\).
Exercise \(\PageIndex{17}\)
Let \(X\) and \(Y\) be random variables. The covariance \(\operatorname{Cov}(\mathrm{X}, \mathrm{Y})\) is defined by (see Exercise 6.2.23)
\[
\operatorname{cov}(\mathrm{X}, \mathrm{Y})=\mathrm{E}((\mathrm{X}-\mu(\mathrm{X}))(\mathrm{Y}-\mu(\mathrm{Y}))) .
\]
(a) Show that \(\operatorname{cov}(\mathrm{X}, \mathrm{Y})=\mathrm{E}(\mathrm{XY})-\mathrm{E}(\mathrm{X}) \mathrm{E}(\mathrm{Y})\).
(b) Using (a), show that \(\operatorname{cov}(X, Y)=0\), if \(X\) and \(Y\) are independent. (Caution: the converse is not always true.)
(c) Show that \(V(X+Y)=V(X)+V(Y)+2 \operatorname{cov}(X, Y)\).
Exercise \(\PageIndex{18}\)
Let \(X\) and \(Y\) be random variables with positive variance. The correlation of \(X\) and \(Y\) is defined as
\[
\rho(X, Y)=\frac{\operatorname{cov}(X, Y)}{\sqrt{V(X) V(Y)}} .
\]
(a) Using Exercise 17(c), show that
\[
0 \leq V\left(\frac{X}{\sigma(X)}+\frac{Y}{\sigma(Y)}\right)=2(1+\rho(X, Y)) .
\]
(b) Now show that
\[
0 \leq V\left(\frac{X}{\sigma(X)}-\frac{Y}{\sigma(Y)}\right)=2(1-\rho(X, Y)) .
\]
(c) Using (a) and (b), show that
\[
-1 \leq \rho(X, Y) \leq 1 .
\]
Exercise \(\PageIndex{19}\)
Let \(X\) and \(Y\) be independent random variables with uniform densities in \([0,1]\). Let \(Z=X+Y\) and \(W=X-Y\). Find
(a) \(\rho(X, Y)\) (see Exercise 18).
(b) \(\rho(X, Z)\).
(c) \(\rho(Y, W)\).
(d) \(\rho(Z, W)\).
Exercise \(\PageIndex{20}\)
When studying certain physiological data, such as heights of fathers and sons, it is often natural to assume that these data (e.g., the heights of the fathers and the heights of the sons) are described by random variables with normal densities. These random variables, however, are not independent but rather are correlated. For example, a two-dimensional standard normal density for correlated random variables has the form
\[
f_{X, Y}(x, y)=\frac{1}{2 \pi \sqrt{1-\rho^2}} \cdot e^{-\left(x^2-2 \rho x y+y^2\right) / 2\left(1-\rho^2\right)} .
\]
(a) Show that \(X\) and \(Y\) each have standard normal densities.
(b) Show that the correlation of \(X\) and \(Y\) (see Exercise 18) is \(\rho\).
Exercise \(\PageIndex{21}\)
For correlated random variables \(X\) and \(Y\) it is natural to ask for the expected value for \(X\) given \(Y\). For example, Galton calculated the expected value of the height of a son given the height of the father. He used this to show that tall men can be expected to have sons who are less tall on the average. Similarly, students who do very well on one exam can be expected to do less well on the next exam, and so forth. This is called regression on the mean. To define this conditional expected value, we first define a conditional density of \(X\) given \(Y=y\) by
\[
f_{X \mid Y}(x \mid y)=\frac{f_{X, Y}(x, y)}{f_Y(y)},
\]
where \(f_{X, Y}(x, y)\) is the joint density of \(X\) and \(Y\), and \(f_Y\) is the density for \(Y\). Then the conditional expected value of \(X\) given \(Y\) is
\[
E(X \mid Y=y)=\int_a^b x f_{X \mid Y}(x \mid y) d x .
\]
For the normal density in Exercise 20, show that the conditional density of \(f_{X \mid Y}(x \mid y)\) is normal with mean \(\rho y\) and variance \(1-\rho^2\). From this we see that if \(X\) and \(Y\) are positively correlated \((0<\rho<1)\), and if \(y>E(Y)\), then the expected value for \(X\) given \(Y=y\) will be less than \(y\) (i.e., we have regression on the mean).
Exercise \(\PageIndex{22}\)
A point \(Y\) is chosen at random from \([0,1]\). A second point \(X\) is then chosen from the interval \([0, Y]\). Find the density for \(X\). Hint: Calculate \(f_{X \mid Y}\) as in Exercise 21 and then use
\[
f_X(x)=\int_x^1 f_{X \mid Y}(x \mid y) f_Y(y) d y .
\]
Can you also derive your result geometrically?
Exercise \(\PageIndex{23}\)
Let \(X\) and \(V\) be two standard normal random variables. Let \(\rho\) be a real number between -1 and 1 .
- Let \(Y=\rho X+\sqrt{1-\rho^2} V\). Show that \(E(Y)=0\) and \(\operatorname{Var}(Y)=1\). We shall see later (see Example 7.5 and Example 10.17), that the sum of two independent normal random variables is again normal. Thus, assuming this fact, we have shown that \(Y\) is standard normal.
- Using Exercises 17 and 18, show that the correlation of \(X\) and \(Y\) is \(\rho\).
- In Exercise 20, the joint density function \(f_{X, Y}(x, y)\) for the random variable \((X, Y)\) is given. Now suppose that we want to know the set of points \((x, y)\) in the \(x y\)-plane such that \(f_{X, Y}(x, y)=C\) for some constant \(C\). This set of points is called a set of constant density. Roughly speaking, a set of constant density is a set of points where the outcomes \((X, Y)\) are equally likely to fall. Show that for a given \(C\), the set of points of constant density is a curve whose equation is \[
x^2-2 \rho x y+y^2=D,
\]
where \(D\) is a constant which depends upon \(C\). (This curve is an ellipse.) - One can plot the ellipse in part (c) by using the parametric equations \[
\begin{array}{l}
x=\dfrac{r \cos \theta}{\sqrt{2(1-\rho)}}+\dfrac{r \sin \theta}{\sqrt{2(1+\rho)}}, \\
y=\dfrac{r \cos \theta}{\sqrt{2(1-\rho)}}-\dfrac{r \sin \theta}{\sqrt{2(1+\rho)}} .
\end{array}
\]Write a program to plot 1000 pairs \((X, Y)\) for \(\rho=-1 / 2,0,1 / 2\). For each plot, have your program plot the above parametric curves for \(r=1,2,3\).
Exercise \(\PageIndex{24}\)
Following Galton, let us assume that the fathers and sons have heights that are dependent normal random variables. Assume that the average height is 68 inches, standard deviation is 2.7 inches, and the correlation coefficient is .5 (see Exercises 20 and 21). That is, assume that the heights of the fathers and sons have the form \(2.7 X+68\) and \(2.7 Y+68\), respectively, where \(X\) and \(Y\) are correlated standardized normal random variables, with correlation coefficient .5.
(a) What is the expected height for the son of a father whose height is 72 inches?
(b) Plot a scatter diagram of the heights of 1000 father and son pairs. Hint: You can choose standardized pairs as in Exercise 23 and then plot \((2.7 X+\) \(68,2.7 Y+68)\).
Exercise \(\PageIndex{25}\)
When we have pairs of data \(\left(x_i, y_i\right)\) that are outcomes of the pairs of dependent random variables \(X, Y\) we can estimate the coorelation coefficient \(\rho\) by
\[
\bar{r}=\frac{\sum_i\left(x_i-\bar{x}\right)\left(y_i-\bar{y}\right)}{(n-1) s_X s_Y},
\]
where \(\bar{x}\) and \(\bar{y}\) are the sample means for \(X\) and \(Y\), respectively, and \(s_X\) and \(s_Y\) are the sample standard deviations for \(X\) and \(Y\) (see Exercise 6.2.17). Write a program to compute the sample means, variances, and correlation for such dependent data. Use your program to compute these quantities for Galton's data on heights of parents and children given in Appendix B.
Plot the equal density ellipses as defined in Exercise 23 for \(r=4,6\), and 8 , and on the same graph print the values that appear in the table at the appropriate points. For example, print 12 at the point \((70.5,68.2)\), indicating that there were 12 cases where the parent's height was 70.5 and the child's was 68.12. See if Galton's data is consistent with the equal density ellipses.
Exercise \(\PageIndex{26}\)
(from Hamming \({ }^{25}\) ) Suppose you are standing on the bank of a straight river.
(a) Choose, at random, a direction which will keep you on dry land, and walk \(1 \mathrm{~km}\) in that direction. Let \(P\) denote your position. What is the expected distance from \(P\) to the river?
(b) Now suppose you proceed as in part (a), but when you get to \(P\), you pick a random direction (from among all directions) and walk \(1 \mathrm{~km}\). What is the probability that you will reach the river before the second walk is completed?
Exercise \(\PageIndex{27}\)
(from Hamming \({ }^{26}\) ) A game is played as follows: A random number \(X\) is chosen uniformly from \([0,1]\). Then a sequence \(Y_1, Y_2, \ldots\) of random numbers is chosen independently and uniformly from \([0,1]\). The game ends the first time that \(Y_i>X\). You are then paid \((i-1)\) dollars. What is a fair entrance fee for this game?
Exercise \(\PageIndex{28}\)
A long needle of length \(L\) much bigger than 1 is dropped on a grid with horizontal and vertical lines one unit apart. Show that the average number \(a\) of lines crossed is approximately
\[
a=\frac{4 L}{\pi} .
\]