
2.1: Simulation of Continuous Probabilities
- Page ID
- 3126

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)In this section we shall show how we can use computer simulations for experiments that have a whole continuum of possible outcomes.
Probabilities
We begin by constructing a spinner, which consists of a circle of unit circumference and a pointer as shown in Figure 2.1. We pick a point on the circle and label it 0, and then label every other point on the circle with the distance, say x, from 0 to that point, measured counterclockwise. The experiment consists of spinning the pointer and recording the label of the point at the tip of the pointer. We let the random variable X denote the value of this outcome. The sample space is clearly the interval [0, 1). We would like to construct a probability model in which each outcome is equally likely to occur.
If we proceed as we did in Chapter 1 for experiments with a finite number of possible outcomes, then we must assign the probability 0 to each outcome, since otherwise, the sum of the probabilities, over all of the possible outcomes, would not equal 1. (In fact, summing an uncountable number of real numbers is a tricky business; in particular, in order for such a sum to have any meaning, at most countably many of the summands can be different than 0.) However, if all of the assigned probabilities are 0, then the sum is 0, not 1, as it should be.
In the next section, we will show how to construct a probability model in this situation. At present, we will assume that such a model can be constructed. We will also assume that in this model, if E is an arc of the circle, and E is of length p, then the model will assign the probability p to E. This means that if the pointer is spun, the probability that it ends up pointing to a point in E equals p, which is certainly a reasonable thing to expect.

To simulate this experiment on a computer is an easy matter. Many computer software packages have a function which returns a random real number in the interval [0, 1]. Actually, the returned value is always a rational number, and the values are determined by an algorithm, so a sequence of such values is not truly random. Nevertheless, the sequences produced by such algorithms behave much like theoretically random sequences, so we can use such sequences in the simulation of experiments. On occasion, we will need to refer to such a function. We will call this function rnd.
Monte Carlo Procedure and Areas
It is sometimes desirable to estimate quantities whose exact values are difficult or impossible to calculate exactly. In some of these cases, a procedure involving chance, called a Monte Carlo procedure, can be used to provide such an estimate.
In this example we show how simulation can be used to estimate areas of plane figures. Suppose that we program our computer to provide a pair (x, y) or numbers, each chosen independently at random from the interval [0, 1]. Then we can interpret this pair (x, y) as the coordinates of a point chosen at random from the unit square. Events are subsets of the unit square. Our experience with Example 2.1 suggests that the point is equally likely to fall in subsets of equal area. Since the total area of the square is 1, the probability of the point falling in a specific subset E of the unit square should be equal to its area. Thus, we can estimate the area of any subset of the unit square by estimating the probability that a point chosen at random from this square falls in the subset.
We can use this method to estimate the area of the region E under the curve y = x 2 in the unit square (see Figure \(\PageIndex{2}\)). We choose a large number of points (x, y) at random and record what fraction of them fall in the region E = { (x, y) : y ≤ x 2 }.
The program MonteCarlo will carry out this experiment for us. Running this program for 10,000 experiments gives an estimate of .325 (see Figure \(\PageIndex{3}\)).

From these experiments we would estimate the area to be about 1/3. Of course, for this simple region we can find the exact area by calculus. In fact,
\[\text{Area of E} =\int_0^1x^2dx = \frac{1}{3}\]
We have remarked in Chapter 1 that, when we simulate an experiment of this type n times to estimate a probability, we can expect the answer to be in error by at most 1/ √ n at least 95 percent of the time. For 10,000 experiments we can expect an accuracy of 0.01, and our simulation did achieve this accuracy.
This same argument works for any region E of the unit square. For example, suppose E is the circle with center (1/2, 1/2) and radius 1/2. Then the probability that our random point (x, y) lies inside the circle is equal to the area of the circle, that is,
\[P(E) = \pi \Big(\frac{1}{2}\Big)^2 = \frac{\pi}{4}\]
If we did not know the value of π, we could estimate the value by performing this experiment a large number of times!
The above example is not the only way of estimating the value of π by a chance experiment. Here is another way, discovered by Buffon.

Buffon's Needle
Suppose that we take a card table and draw across the top surface a set of parallel lines a unit distance apart. We then drop a common needle of unit length at random on this surface and observe whether or not the needle lies across one of the lines. We can describe the possible outcomes of this experiment by coordinates as follows: Let d be the distance from the center of the needle to the nearest line. Next, let L be the line determined by the needle, and define θ as the acute angle that the line L makes with the set of parallel lines. (The reader should certainly be wary of this description of the sample space. We are attempting to coordinatize a set of line segments. To see why one must be careful in the choice of coordinates, see Example \(\PageIndex{6}\).) Using this description, we have 0 ≤ d ≤ 1/2, and 0 ≤ θ ≤ π/2. Moreover, we see that the needle lies across the nearest line if and only if the hypotenuse of the triangle (see Figure \(\PageIndex{4}\)) is less than half the length of the needle, that is,
\[\frac{d}{\sin\theta} < \frac{1}{2}\]
Now we assume that when the needle drops, the pair (θ, d) is chosen at random from the rectangle 0 ≤ θ ≤ π/2, 0 ≤ d ≤ 1/2. We observe whether the needle lies across the nearest line (i.e., whether d ≤ (1/2) sin θ). The probability of this event E is the fraction of the area of the rectangle which lies inside E (see Figure \(\PageIndex{5}\)).


Now the area of the rectangle is π/4, while the area of E is
\[\text{Area} = \int_0^{\pi/2} \frac{1}{2}\sin\theta d\theta = \frac{1}{2}\]
Hence, we got
\[P(E) = \frac{1/2}{\pi/4}=\frac{2}{\pi}\]
The program BuffonsNeedle simulates this experiment. In Figure \(\PageIndex{6}\), we show the position of every 100th needle in a run of the program in which 10,000 needles were “dropped.” Our final estimate for π is 3.139. While this was within 0.003 of the true value for π we had no right to expect such accuracy. The reason for this is that our simulation estimates P(E). While we can expect this estimate to be in error by at most 0.01, a small error in P(E) gets magnified when we use this to compute π = 2/P(E). Perlman and Wichura, in their article “Sharpening Buffon’s

Needle,”2 show that we can expect to have an error of not more than \(5\sqrt{n}\) about 95 percent of the time. Here n is the number of needles dropped. Thus for 10,000 needles we should expect an error of no more than 0.05, and that was the case here. We see that a large number of experiments is necessary to get a decent estimate for π.
In each of our examples so far, events of the same size are equally likely. Here is an example where they are not. We will see many other such examples later.
Suppose that we choose two random real numbers in [0, 1] and add them together. Let X be the sum. How is X distributed? To help understand the answer to this question, we can use the program Areabargraph. This program produces a bar graph with the property that on each interval, the area, rather than the height, of the bar is equal to the fraction of outcomes that fell in the corresponding interval. We have carried out this experiment 1000 times; the data is shown in Figure \(\PageIndex{7}\). It appears that the function defined by
\[f(x) = \left\{ \begin{array}{cc} x, & \text{if } 0 \leq x \leq 1 \\ 2-x, & \text{if } 1 < x \leq 2 \end{array}\right \]
fits the data very well. (It is shown in the figure.) In the next section, we will see that this function is the “right” function. By this we mean that if a and b are any two real numbers between 0 and 2, with a ≤ b, then we can use this function to calculate the probability that a ≤ X ≤ b. To understand how this calculation might be performed, we again consider Figure . Because of the way the bars were constructed, the sum of the areas of the bars corresponding to the interval

[a, b] approximates the probability that a ≤ X ≤ b. But the sum of the areas of these bars also approximates the integral
\[ \int_a^bf(x)dx\]
This suggests that for an experiment with a continuum of possible outcomes, if we find a function with the above property, then we will be able to use it to calculate probabilities. In the next section, we will show how to determine the function f(x).
Suppose that we choose 100 random numbers in [0, 1], and let X represent their sum. How is X distributed? We have carried out this experiment 10000 times; the results are shown in Figure 2.8. It is not so clear what function fits the bars in this case. It turns out that the type of function which does the job is called a normal density function. This type of function is sometimes referred to as a “bell-shaped” curve. It is among the most important functions in the subject of probability, and will be formally defined in Section 5.2 of Chapter 4.3.
Our last example explores the fundamental question of how probabilities are assigned.
Bertrand's Paradox
A chord of a circle is a line segment both of whose endpoints lie on the circle. Suppose that a chord is drawn at random in a unit circle. What is the probability that its length exceeds √ 3? Our answer will depend on what we mean by random, which will depend, in turn, on what we choose for coordinates. The sample space Ω is the set of all possible chords in the circle. To find coordinates for these chords, we first introduce a
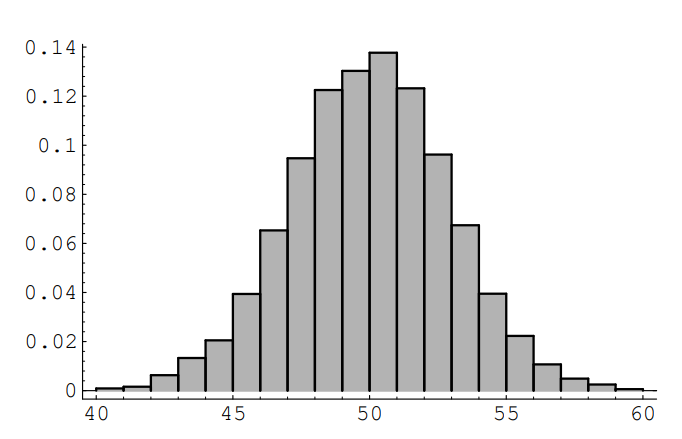
Figure \(\PageIndex{8}\): Sum of 100 random numbers.

rectangular coordinate system with origin at the center of the circle (see Figure \(\PageIndex{9}\)). We note that a chord of a circle is perpendicular to the radial line containing the midpoint of the chord. We can describe each chord by giving:
- The rectangular coordinates (x, y) of the midpoint M, or
- The polar coordinates (r, θ) of the midpoint M, or
- The polar coordinates (1, α) and (1, β) of the endpoints A and B.
In each case we shall interpret at random to mean: choose these coordinates at random.
We can easily estimate this probability by computer simulation. In programming this simulation, it is convenient to include certain simplifications, which we describe in turn:
1. To simulate this case, we choose values for x and y from [−1, 1] at random. Then we check whether x 2 + y 2 ≤ 1. If not, the point M = (x, y) lies outside the circle and cannot be the midpoint of any chord, and we ignore it. Otherwise, M lies inside the circle and is the midpoint of a unique chord, whose length L is given by the formula:
\[L = 2\sqrt{1-(x^2+y^2)}\]
2. To simulate this case, we take account of the fact that any rotation of the circle does not change the length of the chord, so we might as well assume in advance that the chord is horizontal. Then we choose r from [0, 1] at random, and compute the length of the resulting chord with midpoint (r, π/2) by the formula
\[L=2\sqrt{1-r^2}\]
3. To simulate this case, we assume that one endpoint, say B, lies at (1, 0) (i.e., that β = 0). Then we choose a value for α from [0, 2π] at random and compute the length of the resulting chord, using the Law of Cosines, by the formula:
\[L=\sqrt{2-2\cos\alpha}\]
The program BertrandsParadox carries out this simulation. Running this program produces the results shown in Figure 2.10. In the first circle in this figure, a smaller circle has been drawn. Those chords which intersect this smaller circle have length at least √ 3. In the second circle in the figure, the vertical line intersects all chords of length at least √ 3. In the third circle, again the vertical line intersects all chords of length at least √ 3.
In each case we run the experiment a large number of times and record the fraction of these lengths that exceed √ 3. We have printed the results of every 100th trial up to 10,000 trials.
It is interesting to observe that these fractions are not the same in the three cases; they depend on our choice of coordinates. This phenomenon was first observed by Bertrand, and is now known as Bertrand’s paradox.3 It is actually not a paradox at all; it is merely a reflection of the fact that different choices of coordinates will lead to different assignments of probabilities. Which assignment is “correct” depends on what application or interpretation of the model one has in mind.
One can imagine a real experiment involving throwing long straws at a circle drawn on a card table. A “correct” assignment of coordinates should not depend on where the circle lies on the card table, or where the card table sits in the room. Jaynes4 has shown that the only assignment which meets this requirement is (2). In this sense, the assignment (2) is the natural, or “correct” one (see Exercise ).

We can easily see in each case what the true probabilities are if we note that √ 3 is the length of the side of an inscribed equilateral triangle. Hence, a chord has length L > √ 3 if its midpoint has distance d < 1/2 from the origin (see Figure 2.9). The following calculations determine the probability that L > √ 3 in each of the three cases.
1. L > √ 3 if(x, y) lies inside a circle of radius 1/2, which occurs with probability
\[p = \frac{\pi(1/2)^2}{\pi(1)^2}=\frac{1}{4}\]
2. L > √ 3 if |r| < 1/2, which occurs with probability
\[\frac{1/2 -(-1/2)}{1-(-1)}=\frac{1}{2}\]
3. L > √ 3 if 2π/3 < α < 4π/3, which occurs with probability
\[\frac{4\pi/3-2\pi/3}{2\pi-0}=\frac{1}{3}\]
We see that our simulations agree quite well with these theoretical values.
Historical Remarks
G. L. Buffon (1707–1788) was a natural scientist in the eighteenth century who applied probability to a number of his investigations. His work is found in his monumental 44-volume Histoire Naturelle and its supplements. For example, he presented a number of mortality tables and used them to compute, for each age group, the expected remaining lifetime. From his table he observed: the expected remaining lifetime of an infant of one year is 33 years, while that of a man of 21 years is also approximately 33 years. Thus, a father who is not yet 21 can hope to live longer than his one year old son, but if the father is 40, the odds are already 3 to 2 that his son will outlive him.
G. L. Buffon, Histoire Naturelle, Generali et Particular avec le Description du Cabinet du Roy, 44 vols. (Paris: L`Imprimerie Royale, 1749{1803).
G. L. Buffon, \Essai d'Arithmetique Morale,"
Table \(\PageIndex{1}\):Buffon needle experiments to estimate \(\pi \)
|
Experimenter |
Length of Needle |
Number of Casts |
Number of Crossings |
Estimate for \(\pi\) |
|---|---|---|---|---|
|
Wolf, 1850 |
.8 |
5000 |
2532 |
3.1596 |
|
Smith, 1855 |
.6 |
3204 |
1218.5 |
3.1553 |
|
De Morgan, c.1860 |
1.0 |
600 |
382.5 |
3.137 |
|
Fox, 1864 |
.75 |
1030 |
489 |
3.1595 |
|
Lazzerini, 1901 |
.83 |
3408 |
1808 |
3.1415929 |
|
Reina, 1925 |
.5419 |
2520 |
869 |
3.1795 |
Buffon wanted to show that not all probability calculations rely only on algebra, but that some rely on geometrical calculations. One such problem was his famous “needle problem” as discussed in this chapter.7 In his original formulation, Buffon describes a game in which two gamblers drop a loaf of French bread on a wide-board floor and bet on whether or not the loaf falls across a crack in the floor. Buffon asked: what length L should the bread loaf be, relative to the width W of the floorboards, so that the game is fair. He found the correct answer (L = (π/4)W) using essentially the methods described in this chapter. He also considered the case of a checkerboard floor, but gave the wrong answer in this case. The correct answer was given later by Laplace.
The literature contains descriptions of a number of experiments that were actually carried out to estimate π by this method of dropping needles. N. T. Gridgeman8 discusses the experiments shown in Table \(\PageIndex{1}\). (The halves for the number of crossing comes from a compromise when it could not be decided if a crossing had actually occurred.) He observes, as we have, that 10,000 casts could do no more than establish the first decimal place of π with reasonable confidence. Gridgeman points out that, although none of the experiments used even 10,000 casts, they are surprisingly good, and in some cases, too good. The fact that the number of casts is not always a round number would suggest that the authors might have resorted to clever stopping to get a good answer. Gridgeman comments that Lazzerini’s estimate turned out to agree with a well-known approximation to π, 355/113 = 3.1415929, discovered by the fifth-century Chinese mathematician, Tsu Ch’ungchih. Gridgeman says that he did not have Lazzerini’s original report, and while waiting for it (knowing only the needle crossed a line 1808 times in 3408 casts) deduced that the length of the needle must have been 5/6. He calculated this from Buffon’s formula, assuming π = 355/113:
\[L = \frac{\pi P(E)}{2}=\frac{1}{2}\bigg(\frac{355}{113}\bigg)\bigg(\frac{1808}{3408}\bigg)=\frac{5}{6}=.8333.\]
Even with careful planning one would have to be extremely lucky to be able to stop so cleverly. The second author likes to trace his interest in probability theory to the Chicago World’s Fair of 1933 where he observed a mechanical device dropping needles and displaying the ever-changing estimates for the value of π. (The first author likes to trace his interest in probability theory to the second author.)
Exercises
\(\PageIndex{1}\)
In the spinner problem (see Example 2.1) divide the unit circumference into three arcs of length 1/2, 1/3, and 1/6. Write a program to simulate the spinner experiment 1000 times and print out what fraction of the outcomes fall in each of the three arcs. Now plot a bar graph whose bars have width 1/2, 1/3, and 1/6, and areas equal to the corresponding fractions as determined by your simulation. Show that the heights of the bars are all nearly the same.
\(\PageIndex{2}\)
Do the same as in Exercise 1, but divide the unit circumference into five arcs of length 1/3, 1/4, 1/5, 1/6, and 1/20.
\(\PageIndex{3}\)
Alter the program MonteCarlo to estimate the area of the circle of radius 1/2 with center at (1/2, 1/2) inside the unit square by choosing 1000 points at random. Compare your results with the true value of π/4. Use your results to estimate the value of π. How accurate is your estimate?
\(\PageIndex{4}\)
Alter the program MonteCarlo to estimate the area under the graph of y = sin πx inside the unit square by choosing 10,000 points at random. Now calculate the true value of this area and use your results to estimate the value of π. How accurate is your estimate?
\(\PageIndex{5}\)
Alter the program MonteCarlo to estimate the area under the graph of y = 1/(x + 1) in the unit square in the same way as in Exercise 4. Calculate the true value of this area and use your simulation results to estimate the value of log 2. How accurate is your estimate?
\(\PageIndex{6}\)
To simulate the Buffon’s needle problem we choose independently the distance d and the angle θ at random, with 0 ≤ d ≤ 1/2 and 0 ≤ θ ≤ π/2, and check whether d ≤ (1/2) sin θ. Doing this a large number of times, we estimate π as 2/a, where a is the fraction of the times that d ≤ (1/2) sin θ. Write a program to estimate π by this method. Run your program several times for each of 100, 1000, and 10,000 experiments. Does the accuracy of the experimental approximation for π improve as the number of experiments increases?
\(\PageIndex{7}\)
For Buffon’s needle problem, Laplace9 considered a grid with horizontal and vertical lines one unit apart. He showed that the probability that a needle of length L ≤ 1 crosses at least one line is
\[p = \frac{4L-L^2}{\pi}\]
To simulate this experiment we choose at random an angle θ between 0 and π/2 and independently two numbers d1 and d2 between 0 and L/2. (The two numbers represent the distance from the center of the needle to the nearest horizontal and vertical line.) The needle crosses a line if either d1 ≤ (L/2) sin θ or d2 ≤ (L/2) cos θ. We do this a large number of times and estimate π as
\[\bar{\pi} = \frac{4L-L^2}{a}\]
where a is the proportion of times that the needle crosses at least one line. Write a program to estimate π by this method, run your program for 100, 1000, and 10,000 experiments, and compare your results with Buffon’s method described in Exercise 6. (Take L = 1.)
\(\PageIndex{8}\)
A long needle of length L much bigger than 1 is dropped on a grid with horizontal and vertical lines one unit apart. We will see (in Exercise 6.3.28) that the average number a of lines crossed is approximately
\[a =\frac{4L}{\pi}\]
To estimate π by simulation, pick an angle θ at random between 0 and π/2 and compute Lsin θ + Lcos θ. This may be used for the number of lines crossed. Repeat this many times and estimate π by
\[\bar{\pi} =\frac{4L}{a}\]
where a is the average number of lines crossed per experiment. Write a program to simulate this experiment and run your program for the number of experiments equal to 100, 1000, and 10,000. Compare your results with the methods of Laplace or Buffon for the same number of experiments. (Use L = 100.)
The following exercises involve experiments in which not all outcomes are equally likely. We shall consider such experiments in detail in the next section, but we invite you to explore a few simple cases here.
\(\PageIndex{9}\)
A large number of waiting time problems have an exponential distribution of outcomes. We shall see (in Section 5.2) that such outcomes are simulated by computing (−1/λ) log(rnd), where λ > 0. For waiting times produced in this way, the average waiting time is 1/λ. For example, the times spent waiting for
a car to pass on a highway, or the times between emissions of particles from a radioactive source, are simulated by a sequence of random numbers, each of which is chosen by computing (−1/λ) log(rnd), where 1/λ is the average time between cars or emissions. Write a program to simulate the times between cars when the average time between cars is 30 seconds. Have your program compute an area bar graph for these times by breaking the time interval from 0 to 120 into 24 subintervals. On the same pair of axes, plot the function \(f(x)=(1/30)e^{-(1/30)x}\). Does the function fit the bar graph well?
\(\PageIndex{10}\)
In Exercise 9, the distribution came “out of a hat.” In this problem, we will again consider an experiment whose outcomes are not equally likely. We will determine a function f(x) which can be used to determine the probability of certain events. Let T be the right triangle in the plane with vertices at the points (0, 0), (1, 0), and (0, 1). The experiment consists of picking a point at random in the interior of T, and recording only the x-coordinate of the point. Thus, the sample space is the set [0, 1], but the outcomes do not seem to be equally likely. We can simulate this experiment by asking a computer to return two random real numbers in [0, 1], and recording the first of these two numbers if their sum is less than 1. Write this program and run it for 10,000 trials. Then make a bar graph of the result, breaking the interval [0, 1] into 10 intervals. Compare the bar graph with the function f(x) = 2 − 2x. Now show that there is a constant c such that the height of T at the x-coordinate value x is c times f(x) for every x in [0, 1]. Finally, show that
\[\int_0^1f(x)dx=1\]
How might one use the function f(x) to determine the probability that the outcome is between .2 and .5?
\(\PageIndex{11}\)
Here is another way to pick a chord at random on the circle of unit radius. Imagine that we have a card table whose sides are of length 100. We place coordinate axes on the table in such a way that each side of the table is parallel to one of the axes, and so that the center of the table is the origin. We now place a circle of unit radius on the table so that the center of the circle is the origin. Now pick out a point (x0, y0) at random in the square, and an angle θ at random in the interval (−π/2, π/2). Let m = tan θ. Then the equation of the line passing through (x0, y0) with slope m is
\[y=y_0+m(x-x_0)\]
and the distance of this line from the center of the circle (i.e., the origin) is
\[d=\bigg|\frac{y_0-mx_0}{\sqrt{m^2+!}}\bigg|\]
We can use this distance formula to check whether the line intersects the circle (i.e., whether d < 1). If so, we consider the resulting chord a random chord.
This describes an experiment of dropping a long straw at random on a table on which a circle is drawn.
Write a program to simulate this experiment 10000 times and estimate the probability that the length of the chord is greater than \(\sqrt{3}\). How does your estimate compare with the results of Example 2.6?