
9.1: Independent Classes of Random Variables
- Page ID
- 10859

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)The concept of independence for classes of events is developed in terms of a product rule. In this unit, we extend the concept to classes of random variables.
Independent pairs
Recall that for a random variable \(X\), the inverse image \(X^{-1} (M)\) (i.e., the set of all outcomes \(\omega \in \Omega\) which are mapped into \(M\) by \(X\)) is an event for each reasonable subset \(M\) on the real line. Similarly, the inverse image \(Y^{-1}(N)\) is an event determined by random variable \(Y\) for each reasonable set \(N\). We extend the notion of independence to a pair of random variables by requiring independence of the events they determine. More precisely,
Definition
A pair \(\{X, Y\}\) of random variables is (stochastically) independent iff each pair of events \(\{X^{-1} (M), Y^{-1} (N)\}\) is independent.
This condition may be stated in terms of the product rule
\(P(X \in M, Y \le N) = P(X \in M) P(Y \in N)\) for all (Borel) sets \(M, N\)
Independence implies
\[ \begin{align*} F_{XY} (t, u) &= P(X \in (-\infty, t], Y \in (-\infty, u]) \\[4pt] &= P(X \in (-\infty, t]) P(Y \in (-\infty, u]) \\[4pt] &= F_X (t) F_Y (u) \quad \forall t, u \end{align*}\]
Note that the product rule on the distribution function is equivalent to the condition the product rule holds for the inverse images of a special class of sets \(\{M, N\}\) of the form \(M = (-\infty, t]\) and \(N = (-\infty, u]\). An important theorem from measure theory ensures that if the product rule holds for this special class it holds for the general class of \(\{M, N\}\). Thus we may assert
The pair \(\{X, Y\}\) is independent iff the following product rule holds
\[F_{XY} (t, u) = F_X (t) F_Y (u) \quad \forall t, u\]
Example 9.1.1: an independent pair
Suppose \(F_{XY} (t, u) = (1 - e^{-\infty} ) (1 - e^{-\beta u})\) \(0 \le t\), \(0 \le u\). Taking limits shows
\[F_X (t) = \lim_{u \to \infty} F_{XY} (t, u) = 1 - e^{-\alpha t} \nonumber\]
and
\[F_Y(u) = \lim_{t \to \infty} F_{XY} (t, u) = 1- e^{-\beta u} \nonumber\]
so that the product rule \(F_{XY} (t, u) = F_X(t) F_Y(u)\) holds. The pair \(\{X, Y\}\) is therefore independent.
If there is a joint density function, then the relationship to the joint distribution function makes it clear that the pair is independent iff the product rule holds for the density. That is, the pair is independent iff
\(f_{XY} (t, u) = f_X (t) f_Y (u)\) \(\forall t, u\)
example 9.1.2: joint uniform distributin on a rectangle
suppose the joint probability mass distributions induced by the pair \(\{X, Y\}\) is uniform on a rectangle with sides \(I_1 = [a, b]\) and \(I_2 = [c, d]\). Since the area is \((b - a) (d - c)\), the constant value of \(f_{XY}\) is \(1/(b - a) (d - c)\). Simple integration gives
\[f_X(t) = \dfrac{1}{(b - a) (d - c)} \int_{c}^{d} du = \dfrac{1}{b - a} \quad a \le t \le b \nonumber\]
and
\[f_Y(u) = \dfrac{1}{(b - a)(d - c)} \int_{a}^{b} dt = \dfrac{1}{d - c} \quad c \le u \le d \nonumber\]
Thus it follows that \(X\) is uniform on \([a, b]\). \(Y\) is uniform on \([c, d]\), and \(f_{XY} (t, u) = f_X(t) f_Y(u)\) for all \(t, u\), so that the pair \(\{X, Y\}\) is independent. The converse is also true: if the pair is independent with \(X\) uniform on \([a, b]\) and \(Y\) is uniform on \([c, d]\), the pair has uniform joint distribution on \(I_1 \times I_2\).
The Joint Mass Distribution
It should be apparent that the independence condition puts restrictions on the character of the joint mass distribution on the plane. In order to describe this more succinctly, we employ the following terminology.
Definition
If \(M\) is a subset of the horizontal axis and \(N\) is a subset of the vertical axis, then the cartesian product \(M \times N\) is the (generalized) rectangle consisting of those points \((t, u)\) on the plane such that \(t \in M\) and \(u \in N\).
example 9.1.3: Rectangle with interval sides
The rectangle in Example 9.1.2 is the artesian product \(I_1 \times I_2\), consisting of all those points \((t, u)\) such that \(a \le t \le b\) and \(c \le u \le d\) (i.e. \(t \in I_1\) and \(u \in I_2\)).
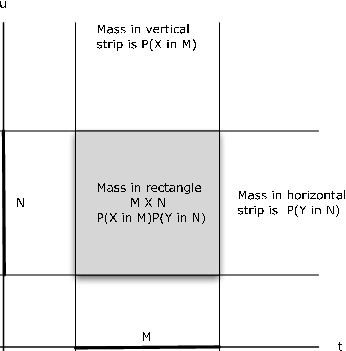
We restate the product rule for independence in terms of cartesian product sets.
\[P(X \in M, Y \in N) = P((X, Y) \in M \times N) = P(X \in M) P(Y \in N)\]
Reference to Figure 9.1.1 illustrates the basic pattern. If \(M, N\) are intervals on the horizontal and vertical axes, respectively, then the rectangle \(M \times N\) is the intersection of the vertical strip meeting the horizontal axis in \(M\) with the horizontal strip meeting the vertical axis in \(N\). The probability \(X \in M\) is the portion of the joint probability mass in the vertical strip; the probability \(Y \in N\) is the part of the joint probability in the horizontal strip. The probability in the rectangle is the product of these marginal probabilities.
This suggests a useful test for nonindependence which we call the rectangle test. We illustrate with a simple example.
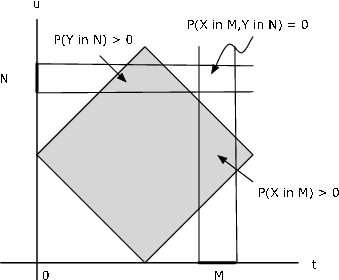
Figure 9.1.2. Rectangle test for nonindependence of a pair of random variables.
example 9.1.4: The rectangle test for nonindependence
Supose probability mass is uniformly distributed over the square with vertices at (1,0), (2,1), (1,2), (0,1). It is evident from Figure 9.1.2 that a value of \(X\) determines the possible values of \(Y\) and vice versa, so that we would not expect independence of the pair. To establish this, consider the small rectangle \(M \times N\) shown on the figure. There is no probability mass in the region. Yet \(P(X \in M) > 0\) and \(P(Y \in N) > 0\), so that
\(P(X \in M) P(Y \in N) > 0\), but \(P((X, Y) \in M \times N) = 0\). The product rule fails; hence the pair cannot be stochastically independent.
Remark. There are nonindependent cases for which this test does not work. And it does not provide a test for independence. In spite of these limitations, it is frequently useful. Because of the information contained in the independence condition, in many cases the complete joint and marginal distributions may be obtained with appropriate partial information. The following is a simple example.
example 9.1.5: Joint and marginal probabilities from partial information
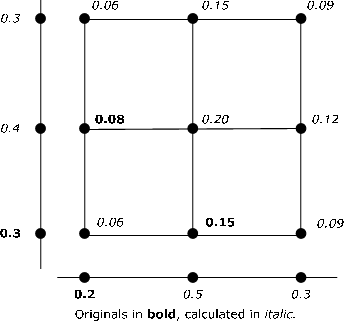
Suppose the pair \(\{X, Y\}\) is independent and each has three possible values. The following four items of information are available.
\(P(X = t_1) = 0.2\), \(P(Y = u_1) = 0.3\), \(P(X = t_1, Y = u_2) = 0.08\)
\(P(X = t_2, Y = u_1) = 0.15\)
These values are shown in bold type on Figure 9.1.3. A combination of the product rule and the fact that the total probability mass is one are used to calculate each of the marginal and joint probabilities. For example \(P(X = t_1) = 0.2\) and \(P(X = t_1, Y = u_2) = P(X = t_1) P(Y = u_2) = 0.8\) implies \(P(Y = u_2) = 0.4\). Then P(Y = u_3) = 1 - P(Y = u_1) - P(Y = u_2) = 0.3\). Others are calculated similarly. There is no unique procedure for solution. And it has not seemed useful to develop MATLAB procedures to accomplish this.
example 9.1.6: The joint normal distribution
A pair \(\{X, Y\}\) has the joint normal distribution iff the joint density is
\(f_{XY} (t, u) = \dfrac{1}{2\pi \sigma_{X} \sigma_{Y} (1 - \rho^2)^{1/2}} e^{-Q(t,u)/2}\)
where
\(Q(t, u) = \dfrac{1}{1 - \rho^2} [(\dfrac{t - \mu_X}{\sigma_X})^2 - 2 \rho (\dfrac{t - \mu_X}{\sigma_X}) (\dfrac{t - \mu_Y}{\sigma_Y}) + (\dfrac{t - \mu_Y}{\sigma_Y})^2]\)
The marginal densities are obtained with the aid of some algebraic tricks to integrate the joint density. The result is that \(X ~ N(\mu_X, \sigma_X^2)\) and \(Y ~ N(\mu_Y, \sigma_Y^2)\). If the parameter \(\rho\) is set to zero, the result is
\(f_{XY} (t, u) = f_X (t) f_Y(u)\)
so that the pair is independent iff \(\rho = 0\). The details are left as an exercise for the interested reader.
Remark. While it is true that every independent pair of normally distributed random variables is joint normal, not every pair of normally distributed random variables has the joint normal distribution.
Example 9.1.7: a normal pair not joint normally distributed
We start with the distribution for a joint normal pair and derive a joint distribution for a normal pair which is not joint normal. The function
\(\varphi (t, u) = \dfrac{1}{2\pi} \text{exp } (-\dfrac{t^2}{2} - \dfrac{u^2}{2})\)
is the joint normal density for an independent pair (\(\rho = 0\)) of standardized normal random variables. Now define the joint density for a pair \(\{X, Y\}\) by
\(f_{XY} (t, u) = 2 \varphi (t, u)\) in the first and third quadrants, and zero elsewhere
Both \(X\) ~ \(N(0,1)\) and \(Y\) ~ \(N(0,1)\). However, they cannot be joint normal, since the joint normal distribution is positive for all (\(t, u\)).
Independent classes
Since independence of random variables is independence of the events determined by the random variables, extension to general classes is simple and immediate.
Definition
A class \(\{X_i: i \in J\}\) of random variables is (stochastically) independent iff the product rule holds for every finite subclass of two or more.
Remark. The index set \(J\) in the definition may be finite or infinite.
For a finite class \(\{X_i: 1 \le i \le n\}\), independence is equivalent to the product rule
\(F_{X_1 X_2 \cdot\cdot\cdot X_n} (t_1, t_2, \cdot\cdot\cdot, t_n) = \prod_{i = 1}^{n} F_{X_i} (t_i)\) for all \((t_1, t_2, \cdot\cdot\cdot, t_n)\)
Since we may obtain the joint distribution function for any finite subclass by letting the arguments for the others be ∞ (i.e., by taking the limits as the appropriate \(t_i\) increase without bound), the single product rule suffices to account for all finite subclasses.
Absolutely continuous random variables
If a class \(\{X_i: i \in J\}\) is independent and the individual variables are absolutely continuous (i.e., have densities), then any finite subclass is jointly absolutely continuous and the product rule holds for the densities of such subclasses
\(f_{X_{i1}X_{i2} \cdot\cdot\cdot X_{im}} (t_{i1}, t_{i2}, \cdot\cdot\cdot, t_{im}) = \prod_{k = 1}^{m} f_{X_{ik}} (t_{ik})\) for all \((t_1, t_2, \cdot\cdot\cdot, t_n)\)
Similarly, if each finite subclass is jointly absolutely continuous, then each individual variable is absolutely continuous and the product rule holds for the densities. Frequently we deal with independent classes in which each random variable has the same marginal distribution. Such classes are referred to as iid classes (an acronym for independent,identically distributed). Examples are simple random samples from a given population, or the results of repetitive trials with the same distribution on the outcome of each component trial. A Bernoulli sequence is a simple example.
Simple random variables
Consider a pair \(\{X, Y\}\) of simple random variables in canonical form
\(X = \sum_{i = 1}^{n}t_i I_{A_i}\) \(Y = \sum_{j = 1}^{m} u_j I_{B_j}\)
Since \(A_i = \{X = t_i\}\) and \(B_j = \{Y = u_j\}\) the pair \(\{X, Y\}\) is independent iff each of the pairs \(\{A_i, B_j\}\) is independent. The joint distribution has probability mass at each point \((t_i, u_j)\) in the range of \(W = (X, Y)\). Thus at every point on the grid,
\(P(X = t_i, Y = u_j) = P(X = t_i) P(Y = u_j)\)
According to the rectangle test, no gridpoint having one of the \(t_i\) or \(u_j\) as a coordinate has zero probability mass . The marginal distributions determine the joint distributions. If \(X\) has \(n\) distinct values and \(Y\) has \(m\) distinct values, then the n+m marginal probabilities suffice to determine the m·n joint probabilities. Since the marginal probabilities for each variable must add to one, only \(n - 1) + (m - 1) = m + n - 2\) values are needed.
Suppose \(X\) and \(Y\) are in affine form. That is,
\(X =a_0 + \sum_{i = 1}^{n} a_i I_{E_i}\) \(Y = b_0 + \sum_{j = 1}^{m} b_j I_{E_j}\)
Since \(A_r = \{X = t_r\}\) is the union of minterms generated by the \(E_i\) and \(B_j = \{Y = u_s\}\) is the union of minterms generated by the \(F_j\), the pair \(\{X, Y\}\) is independent iff each pair of minterms \(\{M_a, N_b\}\) generated by the two classes, respectivly, is independent. Independence of the minterm pairs is implied by independence of the combined class
\(\{E_i, F_j: 1 \le i \le n, 1 \le j \le m\}\)
Calculations in the joint simple case are readily handled by appropriate m-functions and m-procedures.
MATLAB and independent simple random variables
In the general case of pairs of joint simple random variables we have the m-procedure jcalc, which uses information in matrices \(X, Y\) and \(P\) to determine the marginal probabilities and the calculation matrices \(t\) and \(u\). In the independent case, we need only the marginal distributions in matrices \(X\), \(PX\), \(Y\) and \(PY\) to determine the joint probability matrix (hence the joint distribution) and the calculation matrices \(t\) and \(u\). If the random variables are given in canonical form, we have the marginal distributions. If they are in affine form, we may use canonic (or the function form canonicf) to obtain the marginal distributions.
Once we have both marginal distributions, we use an m-procedure we call icalc. Formation of the joint probability matrix is simply a matter of determining all the joint probabilities
\(p(i, j) = P(X = t_i, Y = u_j) = P(X = t_i) P(Y = u_j)\)
Once these are calculated, formation of the calculation matrices \(t\) and \(u\) is achieved exactly as in jcalc.
Example 9.1.8: Use of icalc to set up for joint calculations
X = [-4 -2 0 1 3];
Y = [0 1 2 4];
PX = 0.01*[12 18 27 19 24];
PY = 0.01*[15 43 31 11];
icalc
Enter row matrix of X-values X
Enter row matrix of Y-values Y
Enter X probabilities PX
Enter Y probabilities PY
Use array operations on matrices X, Y, PX, PY, t, u, and P
disp(P) % Optional display of the joint matrix
0.0132 0.0198 0.0297 0.0209 0.0264
0.0372 0.0558 0.0837 0.0589 0.0744
0.0516 0.0774 0.1161 0.0817 0.1032
0.0180 0.0270 0.0405 0.0285 0.0360
disp(t) % Calculation matrix t
-4 -2 0 1 3
-4 -2 0 1 3
-4 -2 0 1 3
-4 -2 0 1 3
disp(u) % Calculation matrix u
4 4 4 4 4
2 2 2 2 2
1 1 1 1 1
0 0 0 0 0
M = (t>=-3)&(t<=2); % M = [-3, 2]
PM = total(M.*P) % P(X in M)
PM = 0.6400
N = (u>0)&(u.^2<=15); % N = {u: u > 0, u^2 <= 15}
PN = total(N.*P) % P(Y in N)
PN = 0.7400
Q = M&N; % Rectangle MxN
PQ = total(Q.*P) % P((X,Y) in MxN)
PQ = 0.4736
p = PM*PN
p = 0.4736 % P((X,Y) in MxN) = P(X in M)P(Y in N)
As an example, consider again the problem of joint Bernoulli trials described in the treatment of 4.3 Composite trials.
Example 9.1.9: The joint Bernoulli trial of Example 4.9
1 Bill and Mary take ten basketball free throws each. We assume the two seqences of trials are independent of each other, and each is a Bernoulli sequence.
Mary: Has probability 0.80 of success on each trial.
Bill: Has probability 0.85 of success on each trial.
What is the probability Mary makes more free throws than Bill?
Solution
Let \(X\) be the number of goals that Mary makes and \(Y\) be the number that Bill makes. Then \(X\) ~ binomial (10, 0.8) and \(Y\) ~ binomial (10, 0.85).
X = 0:10; Y = 0:10; PX = ibinom(10,0.8,X); PY = ibinom(10,0.85,Y); icalc Enter row matrix of X-values X % Could enter 0:10 Enter row matrix of Y-values Y % Could enter 0:10 Enter X probabilities PX % Could enter ibinom(10,0.8,X) Enter Y probabilities PY % Could enter ibinom(10,0.85,Y) Use array operations on matrices X, Y, PX, PY, t, u, and P PM = total((t>u).*P) PM = 0.2738 % Agrees with solution in Example 9 from "Composite Trials". Pe = total((u==t).*P) % Additional information is more easily Pe = 0.2276 % obtained than in the event formulation Pm = total((t>=u).*P) % of Example 9 from "Composite Trials". Pm = 0.5014
Example 9.1.10: Sprinters time trials
Twelve world class sprinters in a meet are running in two heats of six persons each. Each runner has a reasonable chance of breaking the track record. We suppose results for individuals are independent.
First heat probabilities: 0.61 0.73 0.55 0.81 0.66 0.43
Second heat probabilities: 0.75 0.48 0.62 0.58 0.77 0.51
Compare the two heats for numbers who break the track record.
Solution
Let \(X\) be the number of successes in the first heat and \(Y\) be the number who are successful in the second heat. Then the pair \(\{X, Y\}\) is independent. We use the m-function canonicf to determine the distributions for \(X\) and for \(Y\), then icalc to get the joint distribution.
c1 = [ones(1,6) 0]; c2 = [ones(1,6) 0]; P1 = [0.61 0.73 0.55 0.81 0.66 0.43]; P2 = [0.75 0.48 0.62 0.58 0.77 0.51]; [X,PX] = canonicf(c1,minprob(P1)); [Y,PY] = canonicf(c2,minprob(P2)); icalc Enter row matrix of X-values X Enter row matrix of Y-values Y Enter X probabilities PX Enter Y probabilities PY Use array operations on matrices X, Y, PX, PY, t, u, and P Pm1 = total((t>u).*P) % Prob first heat has most Pm1 = 0.3986 Pm2 = total((u>t).*P) % Prob second heat has most Pm2 = 0.3606 Peq = total((t==u).*P) % Prob both have the same Peq = 0.2408 Px3 = (X>=3)*PX' % Prob first has 3 or more Px3 = 0.8708 Py3 = (Y>=3)*PY' % Prob second has 3 or more Py3 = 0.8525
As in the case of jcalc, we have an m-function version icalcf
[x, y, t, u, px, py, p] = icalcf(X, Y, PX, PY)\)
We have a related m-function idbn for obtaining the joint probability matrix from the marginal probabilities. Its formation of the joint matrix utilizes the same operations as icalc.
Example 9.1.11: A numerical example
PX = 0.1*[3 5 2];
PY = 0.01*[20 15 40 25];
P = idbn(PX,PY)
P =
0.0750 0.1250 0.0500
0.1200 0.2000 0.0800
0.0450 0.0750 0.0300
0.0600 0.1000 0.0400
An m- procedure itest checks a joint distribution for independence. It does this by calculating the marginals, then forming an independent joint test matrix, which is compared with the original. We do not ordinarily exhibit the matrix \(P\) to be tested. However, this is a case in which the product rule holds for most of the minterms, and it would be very difficult to pick out those for which it fails. The m-procedure simply checks all of them.
idemo1 % Joint matrix in datafile idemo1
P = 0.0091 0.0147 0.0035 0.0049 0.0105 0.0161 0.0112
0.0117 0.0189 0.0045 0.0063 0.0135 0.0207 0.0144
0.0104 0.0168 0.0040 0.0056 0.0120 0.0184 0.0128
0.0169 0.0273 0.0065 0.0091 0.0095 0.0299 0.0208
0.0052 0.0084 0.0020 0.0028 0.0060 0.0092 0.0064
0.0169 0.0273 0.0065 0.0091 0.0195 0.0299 0.0208
0.0104 0.0168 0.0040 0.0056 0.0120 0.0184 0.0128
0.0078 0.0126 0.0030 0.0042 0.0190 0.0138 0.0096
0.0117 0.0189 0.0045 0.0063 0.0135 0.0207 0.0144
0.0091 0.0147 0.0035 0.0049 0.0105 0.0161 0.0112
0.0065 0.0105 0.0025 0.0035 0.0075 0.0115 0.0080
0.0143 0.0231 0.0055 0.0077 0.0165 0.0253 0.0176
itest
Enter matrix of joint probabilities P
The pair {X,Y} is NOT independent % Result of test
To see where the product rule fails, call for D
disp(D) % Optional call for D
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
1 1 1 1 1 1 1
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
1 1 1 1 1 1 1
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
Next, we consider an example in which the pair is known to be independent.
jdemo3 % call for data in m-file
disp(P) % call to display P
0.0132 0.0198 0.0297 0.0209 0.0264
0.0372 0.0558 0.0837 0.0589 0.0744
0.0516 0.0774 0.1161 0.0817 0.1032
0.0180 0.0270 0.0405 0.0285 0.0360
itest
Enter matrix of joint probabilities P
The pair {X,Y} is independent % Result of test
The procedure icalc can be extended to deal with an independent class of three random variables. We call the m-procedure icalc3. The following is a simple example of its use.
Example 9.1.14: Calculations for three independent random variables
X = 0:4; Y = 1:2:7; Z = 0:3:12; PX = 0.1*[1 3 2 3 1]; PY = 0.1*[2 2 3 3]; PZ = 0.1*[2 2 1 3 2]; icalc3 Enter row matrix of X-values X Enter row matrix of Y-values Y Enter row matrix of Z-values Z Enter X probabilities PX Enter Y probabilities PY Enter Z probabilities PZ Use array operations on matrices X, Y, Z, PX, PY, PZ, t, u, v, and P G = 3*t + 2*u - 4*v; % W = 3X + 2Y -4Z [W,PW] = csort(G,P); % Distribution for W PG = total((G>0).*P) % P(g(X,Y,Z) > 0) PG = 0.3370 Pg = (W>0)*PW' % P(Z > 0) Pg = 0.3370
An m-procedure icalc4 to handle an independent class of four variables is also available. Also several variations of the m-function mgsum and the m-function diidsum are used for obtaining distributions for sums of independent random variables. We consider them in various contexts in other units.
Approximation for the absolutely continuous case
In the study of functions of random variables, we show that an approximating simple random variable \(X_s\) of the type we use is a function of the random variable \(X\) which is approximated. Also, we show that if \(\{X, Y\}\) is an independent pair, so is \(\{g(X), h(Y)\}\) for any reasonable functions \(g\) and \(h\). Thus if \(\{X, Y\}\) is an independent pair, so is any pair of approximating simple functions \(\{X_s, Y_s\}\) of the type considered. Now it is theoretically possible for the approximating pair \(\{X_s, Y_s\}\) to be independent, yet have the approximated pair \(\{X, Y\}\) not independent. But this is highly unlikely. For all practical purposes, we may consider \(\{X, Y\}\) to be independent iff \(\{X_s, Y_s\}\) is independent. When in doubt, consider a second pair of approximating simple functions with more subdivision points. This decreases even further the likelihood of a false indication of independence by the approximating random variables.
Example 9.1.15: An independent pair
Suppose \(X\) ~ exponential (3) and \(Y\) ~ exponential (2) with
\(f_{XY} (t, u) = 6e^{-3t} e^{-2u} = 6e^{-(3t+2u)}\) \(t \ge 0, u \ge 0\)
Since \(e^{-12} \approx 6 \times 10^{-6}\), we approximate \(X\) for values up to 4 and \(Y\) for values up to 6.
tuappr
Enter matrix [a b] of X-range endpoints [0 4]
Enter matrix [c d] of Y-range endpoints [0 6]
Enter number of X approximation points 200
Enter number of Y approximation points 300
Enter expression for joint density 6*exp(-(3*t + 2*u))
Use array operations on X, Y, PX, PY, t, u, and P
itest
Enter matrix of joint probabilities P
The pair {X,Y} is independent
Example 9.1.16: Test for independence
The pair \(\{X, Y\}\) has joint density \(f_{XY} (t, u) = 4tu\) \(0 \le t \le 1\), \(0 \le u \le 1\). It is easy enough to determine the marginals in this case. By symmetry, they are the same.
\(f_X(t) = 4t \int_{0}^{1} udu = 2t\), \(0 \le t \le 1\)
so that \(f_{XY} = f_X f_Y\) which ensures the pair is independent. Consider the solution using tuappr and itest.
tuappr
Enter matrix [a b] of X-range endpoints [0 1]
Enter matrix [c d] of Y-range endpoints [0 1]
Enter number of X approximation points 100
Enter number of Y approximation points 100
Enter expression for joint density 4*t.*u
Use array operations on X, Y, PX, PY, t, u, and P
itest
Enter matrix of joint probabilities P
The pair {X,Y} is independent