26.2: Fitting More Complex Models
- Page ID
- 8851

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \) \( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)\(\newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\) \( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\) \( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\) \( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\) \( \newcommand{\Span}{\mathrm{span}}\) \(\newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\) \( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\) \( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\) \( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\) \( \newcommand{\Span}{\mathrm{span}}\)\(\newcommand{\AA}{\unicode[.8,0]{x212B}}\)
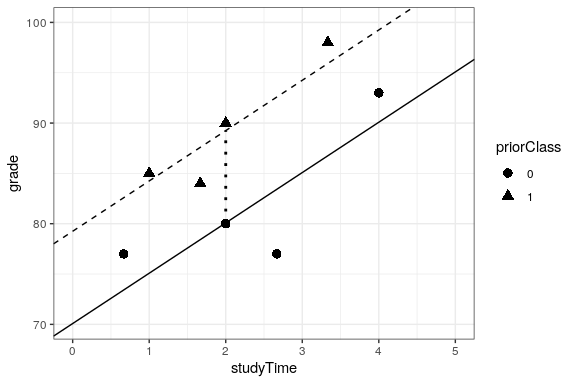
Often we would like to understand the effects of multiple variables on some particular outcome, and how they relate to one another. In the context of our study time example, let’s say that we discovered that some of the students had previously taken a course on the topic. If we plot their grades (see Figure 26.3), we can see that those who had a prior course perform much better than those who had not, given the same amount of study time. We would like to build a statistical model that takes this into account, which we can do by extending the model that we built above:
##
## Call:
## lm(formula = grade ~ studyTime + priorClass, data = df)
##
## Residuals:
## 1 2 3 4 5 6 7 8
## 3.5833 0.7500 -3.5833 -0.0833 0.7500 -6.4167 2.0833 2.9167
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 70.08 3.77 18.60 8.3e-06 ***
## studyTime 5.00 1.37 3.66 0.015 *
## priorClass1 9.17 2.88 3.18 0.024 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4 on 5 degrees of freedom
## Multiple R-squared: 0.803, Adjusted R-squared: 0.724
## F-statistic: 10.2 on 2 and 5 DF, p-value: 0.0173