
Zimeng Wang
- Page ID
- 2491
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)
-
ID: The unique code name for each review
-
Sentiment: It is a binary number consisting of 1 and 0. People can rate the movie from 1 to 10. When there are less than 5 IMDB rating, the score will be 0. Otherwise, the score will be 1. Overall, there are 12,500 zeros and 12,500 ones within these 25,000 IMDB movie reviews.
-
Review: A paragraph of raw text written by a reviewer.
By using this dataset, I want to do Sentiment Analysis by using SVM for the purpose of predicting the sentiment score of certain reviews. The general procedures are doing a text cleaning and processing to the raw text, applying the Bag of word method to create features and forming a Term-Document matrix to fit the SVM model.
\(\Rightarrow \textbf{STEP 1: Text cleaning}\)
As you can see in picture 1, the text has plenty of HTML symbols, stop words, unexpected punctuation, and extra space that may distract the computer to do machine learning. In order to transform the review to a relatively clean version, we removed all of them by following steps:
-
Removing HTML symbols
-
Removing punctuation, number and extra space
-
Converting each word to lower case
-
Splitting the review into individual word
-
Removing the Stop words
-
Putting the rest of the words altogether as the clean review
We will follow this procedure to all 25,000 movie reviews. Picture 2 is a comparison between the raw text and the clean text for a review. The first paragraph is the original review. The second paragraph is the clean review.


To be clarified, the words shown frequently without any meaning are called “stop words” such as “you”, “the”, and “I”. Their occurrence in the reviews doesn’t affect the sentiment score. For the convenience of feature extraction in the bag of words, we want to delete them as great as possible. In Python Natural Language Toolkit, there is a package having the list of stop words that we can directly use. Picture 3 is showing the Stop words list.

\(\Rightarrow \textbf{STEP 2: Bag of Words Model}\)
For the convenience of machine learning, we need to convert all the information from words into a numeric version and create features from it. The Bag of Words model will perfectly suit our requirements. It learns every single vocabulary from all of the reviews and counts the frequency of each word about how many times they appear in total. For example, here are two simple sentences:
Sentence 1: “stuff, go, moment, start, listening”
Sentence 2: “stuff, odd, start, start, cool”
We can see the words contained in each sentence and get the vocabulary as follow:
{start, stuff, go, odd, moment, listening, cool}
For each sentence, we will get a list of number that shows the count of a number of each word and form the feature vector for each sentence:
Sentence 1: {1,1,1,0,1,1,0}
Sentence 2: {2,1,0,1,0,0,1}
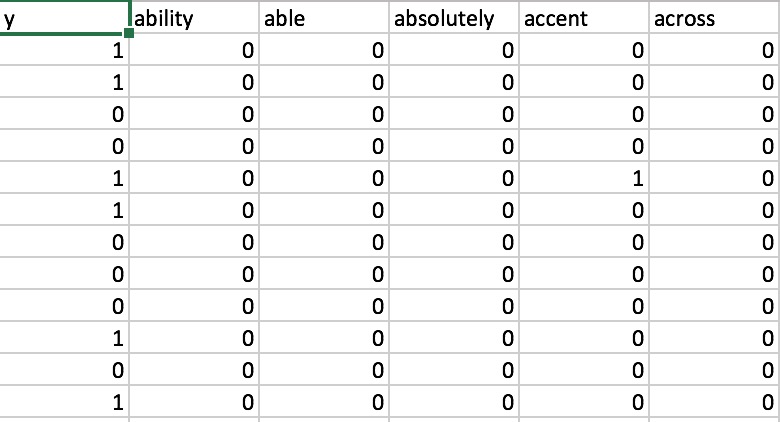
Similarly, we can form a feature vector for each review. However, the dataset size is too large to process. To limit the size of the feature vectors, we can choose the first 5000 reviews as our training dataset and extract the 1000 most frequent words as the feature. The final result will be a matrix formed by the frequency of 1000 features for 5000 reviews. Picture 4 shows a part of a term-document matrix which has 5000 rows * 1001 columns. The first column is the real sentiment label for each review and the rest of 1000 columns are the features we just extracted through Bag of words model.
.jpg?revision=1&size=bestfit&width=458&height=248)
\(\Rightarrow \textbf{STEP 3: Fitting a SVM Model}\)
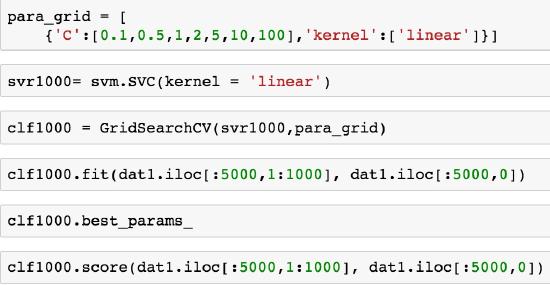
After the data processing, we fit a SVM model to the Document term matrix and see how great our model is by checking the accuracy score. Picture 6 shows the python code to achieve our goal. The parameter “C” here is a non-negative slack variable to control the over fitting. If C = 0, we would consider that none of the samples should be misclassified. If C \(>\) 0, then we can trade-off some misclassified samples in order to find the best margin that separates others into different classes. A large C means that we would like a narrow margin that separates most the samples correctly. Conversely, a small C gives a wider margin with the higher error of misclassification but it might strengthen the robustness.
\(\Rightarrow \textbf{STEP 4: Comparing the result under different feature and cost}\)
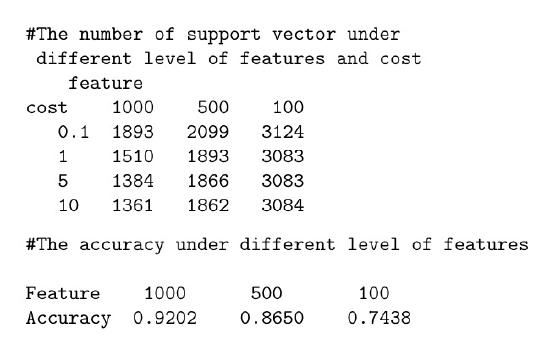
After we extract the different amount of features by changing the function named “max\(\_\)features” in the bag of word function, the accuracy score will change accordingly. Picture 7 is a table showing all the result we got from different SVM models.
Reference
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (\(2011\)). “Learning Word Vectors for Sentiment Analysis.”The 49th Annual Meeting of the Association for Computational Linguistics (ACL \(2011\)).
Bag of Words Meets Bags of Popcorn (\(2015\)). Kaggle. Retrieved from: \(https://www.kaggle.com/c/word2vec-nlp-tutorial\)