
5.4: Finding Distributions of Functions of Continuous Random Variables
- Page ID
- 3275

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)Single Variable Case
In addition to considering the probability distributions of random variables simultaneously using joint distribution functions, there is also occasion to consider the probability distribution of functions applied to random variables as the following example demonstrates.
Example \(\PageIndex{1}\)
Consider again the context of Example 5.2.2, where the random variable \(X\) represented the amount of gas stocked in a given week at a specific gas station. In Example 5.3.5, we showed that the pdf of \(X\) is given by
$$f_X(x) = \left\{\begin{array}{l l}
3x^2, & \text{for}\ 0\leq x\leq 1 \\
0, & \text{otherwise.}
\end{array}\right.\notag$$
Suppose that the storage tank at the gas station holds 10,000 gallons, then \(10,000X\) gives the number of gallons stocked in a week. If the current price of gas is $3/gallon and there are fixed delivery costs of $2000, then the total cost to stock \(10,000X\) gallons in a given week is given by the following
$$3(10,000X) + 2000 \quad\Rightarrow\quad C = 30,000X + 2000,\label{cost}$$
where the random variable \(C\) denotes the total cost of delivery.
One approach to finding the probability distribution of a function of a random variable relies on the relationship between the pdf and cdf for a continuous random variable:
$$\frac{d}{dx} [F(x)] = f(x) \qquad\text{''derivative of cdf = pdf"}\notag$$
As we will see in the following examples, it is often easier to find the cdf of a function of a continuous random variable, and then use the above relationship to derive the pdf.
Example \(\PageIndex{2}\)
Continuing with Example 5.4.1, we find the pdf of the total cost, \(C\). First, we derive the cdf for \(X\). If we let \(0\leq x\leq 1\), i.e., select a value of \(x\) where the pdf of \(X\) is nonzero, then we have
$$F_X(x) = P(X\leq x) = \int_{-\infty}^x \! f_X(t)\, dt = \int^x_0\! 3t^2\, dt = t^3\Big|^x_0 = x^3.\notag$$
For any \(x<0\), the cdf of \(X\) is necessarily 0, since \(X\) cannot be negative (we cannot stock a negative proportion of the tank). And for any \(x>1\), the cdf of \(X\) is necessarily equal to 1, since the proportion of gas stocked will always be less than or equal to 100% of the tank's capacity. Putting it all together, we have the cdf of \(X\) given as follows:
$$F_X(x) = \left\{\begin{array}{l l}
0, & x<0\\
x^3, & 0\leq x\leq 1 \\
1, & 1<x
\end{array}\right.\label{cdfX}$$
We can now use the cdf of \(X\) to find the cdf of \(C\). Let \(c\) denote a possible value for the random variable \(C\). We relate the cdf of \(C\) to the cdf of \(X\) by substituting the expression of \(C\) in terms of \(X\) given in Equation \ref{cost}, and then solving for \(X\), as follows:
$$F_C(c) = P(C\leq c) = P(30000X+2000\leq c) = P\left(X\leq \frac{c-2000}{30000}\right) = F_X\left(\frac{c-2000}{30000}\right)\notag$$
If \(0 \leq (c-2000)/30000 \leq 1 \Rightarrow 2000 \leq c \leq 32000\), then, using the formula for the cdf of \(X\) we derived in Equation \ref{cdfX}, we find that the cdf of \(C\) is
$$F_C(c) = \left(\frac{c-2000}{30000}\right)^3, \quad\text{for}\ 2000\leq c\leq 32000.\label{cdfC}$$
Note that \(2000\leq c\leq32000\) gives the possible values of \(C\). \(C\) cannot be less than $2,000 because of the fixed delivery costs, and \(C\) cannot be more than $32,000, which is the cost of stocking the entire tank.
We now find the pdf of \(C\) by taking the derivative of the cdf in Equation \ref{cdfC}:
$$f_C(c) = \frac{d}{dc}\left[F_C(c)\right] = \frac{d}{dc} \left[\left(\frac{c-2000}{30000}\right)^3\right] = 3\left(\frac{c-2000}{30000}\right)^2\times \left(\frac{1}{30000}\right), \text{ for } 2000\leq c\leq32000\notag$$
Video: Motivating Example (Walkthrough of Examples 5.4.1 & 5.4.2)
Example 5.4.2 demonstrates the general strategy to finding the probability distribution of a function of a random variable: we first find the cdf of the random variable in terms of the random variable it is a function of (assuming we know the cdf of that random variable), then we differentiate to find the pdf. Let's look at another example before formalizing the strategy.
Example \(\PageIndex{3}\)
Let \(X\) be uniform on \([0,1]\). We find the pdf of \(Y = X^2\).
Recall that the pdf for a uniform\([0,1]\) random variable is \(f_X(x) = 1, \) for \(0\leq x\leq 1\), and that the cdf is
$$F_X(x) = \left\{\begin{array}{l l}
0, & x<0 \\
x, & 0\leq x\leq 1\\
1, & x>1
\end{array}\right.\notag$$
Note that the possible values of \(Y\) are \(0\leq y\leq 1\).
First, we find the cdf of \(Y\), for \(0\leq y\leq 1\):
$$F_Y(y) = P(Y\leq y) = P(X^2\leq y) = P\left(X\leq \sqrt{y}\right) = F_X\left(\sqrt{y}\right) = \sqrt{y}, \text{ for } 0\leq y\leq 1\notag$$
Now we differentiate the cdf to get the pdf of \(Y\):
$$f_Y(y) = \frac{d}{dy}[F_Y(y)] = \frac{d}{dy}\left[\sqrt{y}\right] = \frac{1}{2}y^{-\frac{1}{2}}, \text{ for } 0\leq y\leq 1\notag$$
The following formalizes the strategy we took to find the cdf's in the previous examples.
Change-of-Variable Technique
Suppose that \(X\) is a continuous random variable with pdf \(f_X(x)\), which is nonzero on interval \(I\).
Further suppose that \(g\) is a differentiable function that is strictly monotonic on \(I\).
Then the pdf of \(Y=g(X)\) is given by
$$f_Y(y) = f_X\left(g^{-1}(y)\right)\times\left|\frac{d}{dy}\left[g^{-1}(y)\right]\right|,\qquad\ \text{for}\ x\in I\ \text{and } y=g(x).\label{cov}$$
Video: Change-of-Variable Technique & Walkthrough of Example 5.4.5
Returning to Example 5.4.2, we demonstrate the Change-of-Variable technique.
Example \(\PageIndex{4}\)
Recall that the random variable \(X\) denotes the amount of gas stocked. We now let \(Y\) denote the total cost of delivery for the gas stocked, i.e., \(Y = 30000X+2000\). We know that the pdf of \(X\) is given by
$$f_X(x) = 3x^2, \text{ for } 0\leq x\leq 1,\notag$$
so that \(I = [0,1]\), using the notation of the Change-of-Variable technique. We also have that \(y = g(x) = 30000x+2000\), and note that \(g\) is increasing on the interval \(I\). Thus, the Change-of-Variable technique can be applied, and so we find the inverse of \(g\) and its derivative:
$$x= g^{-1}(y) = \frac{y-2000}{30000} \quad\text{ and }\quad \frac{d}{dy}[g^{-1}(y)] = \frac{d}{dy}\left[\frac{y-2000}{30000}\right] = \frac{1}{30000}\notag$$
So, applying Change-of-Variable formula given in Equaton \ref{cov}, we get
$$f_Y(y) = f_X(g^{-1}(y))\times \frac{d}{dy}[g^{-1}(y)] = 3(g^{-1}(y))^2\times\frac{1}{30000} = 3\left(\frac{y-2000}{30000}\right)^2\times\frac{1}{30000},\notag$$
which matches the result found in Example 5.4.2.
Informally, the Change-of-Variable technique can be restated as follows.
- Find the cdf of \(Y=g(X)\) in terms of the cdf for \(X\) using the inverse of \(g\), i.e., isolate \(X\).
- Take the derivative of the cdf of \(Y\) to get the pdf of \(Y\) using the chain rule. An absolute value is needed if \(g\) is decreasing.
The advantage of the Change-of-Variable technique is that we do not have to find the cdf of \(X\) in order to find the pdf of \(Y\), as the next example demonstrates.
Example \(\PageIndex{5}\)
Let the random variable \(X\) have pdf given by \(f_X(x) = 5x^4\), for \(0\leq x\leq 1\), i.e., \(I = [0,1]\). Also, let \(g(x) = 1-x^2\). To find the pdf for \(Y= g(X) = 1-X^2\), we first find \(g^{-1}\):
\begin{align*}
y &= g(x) \\
y &= 1-x^2 \\
y-1 &= -x^2 \\
\Rightarrow g^{-1}(y) = \sqrt{1-y} &= x
\end{align*}
Now we can find the derivative of \(g^{-1}\):
$$\frac{d}{dy}[g^{-1}(y)] = \frac{d}{dy}\left[\sqrt{1-y}\right] = -\frac{1}{2}(1-y)^{-\frac{1}{2}}\notag$$
Applying the Change-of-Variable formula we find the pdf of \(Y\):
$$f_Y(y) = f_X(g^{-1}(y))\times\bigg|\frac{d}{dy}[g^{-1}(y)]\bigg| = 5\left(\sqrt{1-y}\right)^4\times\bigg|-\frac{1}{2}(1-y)^{-\frac{1}{2}}\bigg| = \frac{5}{2}\left(\sqrt{1-y}\right)^3, \quad\text{ for } 0\leq y\leq 1.\notag$$
The Change-of-Variable technique requires that a monotonic function \(g\) is applied. However, if that is not the case, we can just consider the monotonic pieces separately, as in the next example.
Example \(\PageIndex{6}\)
Let \(X\) be uniform on \([-1, 1]\). Then the pdf of \(X\) is
$$f_X(x) = \frac{1}{2}, \text{ for } -1\leq x\leq 1,\notag$$
and the cdf of \(X\) is
$$F_X(x) = \left\{\begin{array}{ll}
0, & \text{ for } x<-1 \\
\displaystyle{\frac{x+1}{2}}, & \text{ for } -1\leq x\leq 1 \\
1, & \text{ for } x>1
\end{array}\right.\notag$$
We find the pdf for \(Y=X^2\).
Following the general strategy, we first find the cdf of \(Y\) in terms of \(X\):
\begin{align*}
F_Y(y) = P(Y\leq y) &= P(X^2\leq y) = 0, \quad\text{ if } y<0 \\
\text{and}\ F_Y(y) &= P\left(-\sqrt{y}\leq X \leq \sqrt{y}\right), \quad\text{ if } y\geq 0 \\
\Rightarrow F_Y(y) &= F_X\left(\sqrt{y}\right) - F_X\left(-\sqrt{y}\right) = \frac{\sqrt{y} + 1}{2} - \frac{-\sqrt{y}+1}{2} = \sqrt{y}, \quad\text{if}\ 0\leq \sqrt{y} \leq 1,
\end{align*}
which gives
$$F_Y(y) = \left\{\begin{array}{l l}
0 & \text{ if } y<0 \\
\sqrt{y}, & \text{ if } 0\leq y\leq 1\\
1, & \text{ if } y>1
\end{array}\right.\notag$$
Now we take the derivative of the cdf to get the pdf of \(Y\):
$$f_Y(y) = \frac{d}{dy}[F_Y(y)] =\left\{\begin{array}{ll}
\displaystyle{\frac{d}{dy}[0]} = 0, & \text{ if } y<0 \\
\displaystyle{\frac{d}{dy}\left[\sqrt{y}\right] = \frac{1}{2\sqrt{y}}}, & \text{ if } 0\leq y\leq 1\\
\displaystyle{\frac{d}{dy}[1]=0}, & \text{ if } y>1
\end{array}\right.\notag$$
In summary, the pdf of \(Y=X^2\) is given by
$$f_Y(y) = \left\{\begin{array}{ll}
\displaystyle{\frac{1}{2\sqrt{y}}}, & \text{ if } 0\leq y\leq 1\\
0, & \text{ otherwise }
\end{array}\right.\notag$$
Special Case: Normal Distributions
Functions of normally distributed random variables are of particular importance in statistics. In the next example, we derive the probability distribution of the square of a standard normal random variable.
Example \(\PageIndex{7}\)
Let \(Z\) be a standard normal random variable, i.e., \(Z\sim N(0,1)\). We find the pdf of \(Y=Z^2\).
Let \(\Phi\) denote the cdf of \(Z\), i.e., \(\Phi(z) = P(Z\leq z) = F_Z(z)\). We first find the cdf of \(Y=Z^2\) in terms of \(\Phi\) (recall that there is no closed form expression for \(\Phi\)):
\begin{align*}
F_Y(y) = P(Y\leq y) &= P(Z^2\leq y)\\
&= P\left(-\sqrt{y} \leq Z \leq \sqrt{y}\right), \text{ for } y\geq0\\
&= \Phi\left(\sqrt{y}) - \Phi(-\sqrt{y}\right)
\end{align*}
Note that if \(y<0\), then \(F_Y(y) = 0\), since it is not possible for \(Y=Z^2\) to be negative. In other words, the possible values of \(Y=Z^2\) are \(y\geq 0\).
Next, we take the derivative of the cdf of \(Y\) to find its pdf. Before doing so, we note that if \(\Phi\) is the cdf for \(Z\), then its derivative is the pdf for \(Z\), which is denoted \(\varphi\). Since \(Z\) is a standard normal random variable, we know that
$$\varphi(z) = f_Z(z) = \frac{1}{\sqrt{2\pi}}e^{-z^2/2}, \quad\text{for}\ z\in\mathbb{R}.\notag$$
Using this, we now find the pdf of \(Y\):
\begin{align*}
f_Y(y) = \frac{d}{dy}[F_Y(y)] &= \frac{d}{dy}\left[\Phi\left(\sqrt{y}\right)-\Phi\left(-\sqrt{y}\right)\right]\\
&=\frac{d}{dy}\left[\Phi\left(\sqrt{y}\right)\right] - \frac{d}{dy}\left[\Phi\left(-\sqrt{y}\right)\right]\\
&= \varphi\left(\sqrt{y}\right)\cdot\frac{1}{2\sqrt{y}} + \varphi\left(-\sqrt{y}\right)\cdot\frac{1}{2\sqrt{y}}\\
&= \frac{1}{\sqrt{2\pi}}e^{-(\sqrt{y})^2/2}\cdot\frac{1}{2\sqrt{y}} + \frac{1}{\sqrt{2\pi}}e^{-(-\sqrt{y})^2/2}\cdot\frac{1}{2\sqrt{y}} \\
&= \frac{1}{\sqrt{2\pi}}e^{-y/2} \cdot \frac{1}{\sqrt{y}}.
\end{align*}
In summary, if \(Y= Z^2\), where \(Z\sim N(0,1)\), then the pdf for \(Y\) is given by
$$f_Y(y) = \frac{y^{-1/2}}{\sqrt{2\pi}}e^{-y/2}, \text{ for } y\geq 0.\notag$$
Note that the pdf for \(Y\) is a gamma pdf with \(\alpha = \lambda = \frac{1}{2}\). This is also referred to as the chi-square distribution, denoted \(\chi^2\). See below for a video walkthrough of this example.
Multivariate Case
We can extend the Change-of-Variable technique to the multivariate case as well.
Example \(\PageIndex{8}\)
Suppose that \(X\) and \(Y\) have joint pdf given by
$$f(x,y) = e^{-x}, \quad\text{for}\ 0\leq y\leq x < \infty.\notag$$
The following figure shows the region (shaded in blue) over which the joint pdf of \(X\) and \(Y\) is nonzero.
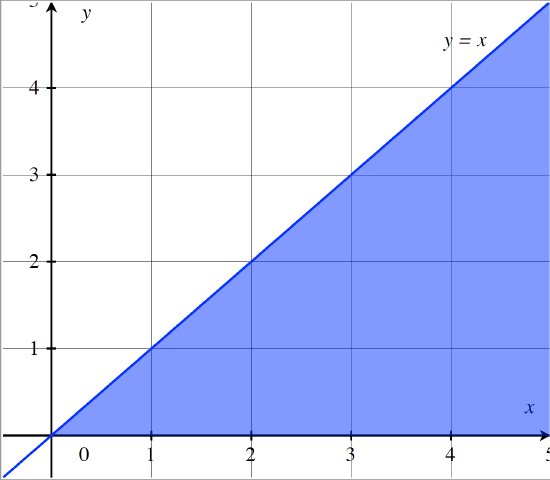
Let's define the random variable \(W = g(X,Y) = X-Y\), and find the pdf of \(W\).
First, we find the cdf of \(W\),
$$F_W(w) = P(W\leq w) = P(X-Y\leq w),\notag$$
for which we need to find where the region given by \(\{(x,y) | x-y \leq w\}\) intersects the region over which the joint pdf \(f(x,y)\) is nonzero. Note that if \(w<0\), then \(P(X-Y\leq w) = 0\), since there is no intersection with where the joint pdf \(f(x,y)\) is nonzero. If \(w \geq 0\), then
\begin{align*}
P(X-1\leq w) &= \int^{\infty}_0\int^{y+w}_{y}\!e^{-x}\,dxdy = \int^{\infty}_0\!-e^{-x}\Big|^{y+w}_{y}\,dy\\
&= \int^{\infty}_0\! (-e^{-(y+w)}+e^{-y}) dy\\
&= \int^{\infty}_0\! (-e^{-y}e^{-w}+e^{-1}) dy\\
&= \int^{\infty}_0\! e^{-y}(-e^{-w}+1)dy\\
&=(-e^{-w})(-e^{-y})\Big|^{\infty}_0\\
&= 1-e^{-w}
\end{align*}
In summary, we have found the following
$$F_W(w) = \left\{\begin{array}{ll}
0, & \text{ if } w<0\\
1-e^{-w}, & \text{ if } w\geq 0
\end{array}\right.\notag$$
We then take derivative of cdf to find pdf:
$$f_W(w) = \frac{d}{dw}[F_W(w)] = \left\{\begin{array}{ll}
0, & \text{ if } w<0 \\
\frac{d}{dw}[1-e^{-w}] = e^{-w}, & \text{ if } w\geq 0
\end{array}\right.\notag$$
Note: \(W\) is exponential with \(\lambda = 1\).
Using Moment-Generating Functions
There is another approach to finding the probability distribution of functions of random variables, which involves moment-generating functions. Recall the following properties of mgf's.
Theorem 3.8.4
The mgf \(M_X(t)\) of random variable \(X\) uniquely determines the probability distribution of \(X\). In other words, if random variables \(X\) and \(Y\) have the same mgf, \(M_X(t) = M_Y(t)\), then \(X\) and \(Y\) have the same probability distribution.
Theorem 3.8.2
Let \(X\) be a random variable with mgf \(M_X(t)\), and let \(a,b\) be constants. If random variable \(Y= aX + b\), then the mgf of \(Y\) is given by
$$M_Y(t) = e^{bt}M_X(at).\notag$$
Theorem 3.8.3
If \(X_1, \ldots, X_n\) are independent random variables with mgf's \(M_{X_1}(t), \ldots, M_{X_n}(t)\), respectively, then the mgf of random variable \(Y = X_1 + \cdots + X_n\) is given by
$$M_Y(t) = M_{X_1}(t) \cdots M_{X_n}(t).\notag$$
Theorem 3.8.4 states that mgf's are unique, and Theorems 3.8.2 & 3.8.3 combined provide a process for finding the mgf of a linear combination of random variables. All three theorems provide a Moment-Generating-Function technique for finding the probability distribution of a function of random variable(s), which we demonstrate with the following examples involving the normal distribution.
Example \(\PageIndex{9}\)
Suppose that \(X\sim N(\mu,\sigma)\). It can be shown that the mgf of \(X\) is given by
$$M_X(t) = e^{\mu t + (\sigma^2 t^2/2)}, \quad\text{for}\ t\in\mathbb{R}.\notag$$
Using this mgf formula, we can show that \(\displaystyle{Z = \frac{X-\mu}{\sigma}}\) has the standard normal distribution.
- Note that if \(Z\sim N(0,1)\), then the mgf is \(M_Z(t) = e^{0t+(1^2t^2/2)} = e^{t^2/2}\)
- Also note that \(\displaystyle{\frac{X-\mu}{\sigma} = \left(\frac{1}{\sigma}\right)X+\left(\frac{-\mu}{\sigma}\right)}\), so by Theorem 3.8.2,
$$M_{\frac{1}{\sigma}X-\frac{\mu}{\sigma}}(t) = e^{-\frac{\mu t}{\sigma}}M_X\left(\frac{t}{\sigma}\right) = e^{t^2/2}.\notag$$
Thus, we have shown that \(Z\) and \(\displaystyle{\frac{X-\mu}{\sigma}}\) have the same mgf, which by Theorem 3.8.4, says that they have the same distribution.
Now suppose \(X_1, \ldots, X_n\) are each independent normally distributed with means \(\mu_1, \ldots, \mu_n\) and sd's \(\sigma_1, \ldots, \sigma_n\), respectively.
Let's find the probability distribution of the sum \(Y = a_1X_1 + \cdots + a_nX_n\) (\(a_1,\ldots,a_n\) constants) using the mgf technique:
By Theorem 3.8.2, we have
$$M_{a_iX_i}(t) = M_{X_i}(a_it) = e^{\mu_ia_it+(\sigma_i)^2(a_i)^2t^2/2},\quad\text{for}\ i=1, \cdots, n,\notag$$
and then by Theorem 3.8.3 we get the following:
\begin{align*}
M_Y(t) &= M_{a_1X_1}(t)\cdot M_{a_2X_2}(t)\cdots M_{a_nX_n}(t)\\
&= e^{\mu_1a_1t+\sigma_1^2a_1^2t^2/2}e^{\mu_2a_2t+\sigma_2^2a_2^2t^2/2}\cdots e^{\mu_na_nt+\sigma_n^2a_n^2t^2/2}\\
&= e^{(\mu_1a_1+\mu_2a_2+\cdots+\mu_na_n)t+(\sigma_1^2a_1^2+\sigma_2^2a_2^2+\cdots+\sigma_n^2a_n^2)\frac{t^2}{2}}\\
\Rightarrow M_Y(t) &= e^{\mu_yt+\sigma_y^2t^2/2}
\end{align*}
Thus, by Theorem 3.8.4, \(Y\sim N(\mu_y,\sigma_y)\).
The second part of Example 5.4.9 proved the following.
Sums of Independent Normal Random Variables
If \(X_1,\ldots,X_n\) are mutually independent normal random variables with means \(\mu_1, \ldots, \mu_n\) and standard deviations \(\sigma_1, \ldots, \sigma_n\), respectively, then the linear combination
$$Y = a_1X_1 + \cdots + c_nX_n = \sum^n_{i=1} a_iX_i,\notag$$
is normally distributed with the following mean and variance:
$$\mu_Y = a_1\mu_1 + \cdots + a_n\mu_n = \sum^n_{i=1}a_i\mu_i \qquad \sigma^2_Y = a_1^2\sigma^2_1 + \cdots + a_n\sigma^2_n = \sum^n_{i=1}a^2_i\sigma^2_i\notag$$