
15.1: Introduction
- Page ID
- 10277

\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\dsum}{\displaystyle\sum\limits} \)
\( \newcommand{\dint}{\displaystyle\int\limits} \)
\( \newcommand{\dlim}{\displaystyle\lim\limits} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\(\newcommand{\longvect}{\overrightarrow}\)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\(\newcommand{\avec}{\mathbf a}\) \(\newcommand{\bvec}{\mathbf b}\) \(\newcommand{\cvec}{\mathbf c}\) \(\newcommand{\dvec}{\mathbf d}\) \(\newcommand{\dtil}{\widetilde{\mathbf d}}\) \(\newcommand{\evec}{\mathbf e}\) \(\newcommand{\fvec}{\mathbf f}\) \(\newcommand{\nvec}{\mathbf n}\) \(\newcommand{\pvec}{\mathbf p}\) \(\newcommand{\qvec}{\mathbf q}\) \(\newcommand{\svec}{\mathbf s}\) \(\newcommand{\tvec}{\mathbf t}\) \(\newcommand{\uvec}{\mathbf u}\) \(\newcommand{\vvec}{\mathbf v}\) \(\newcommand{\wvec}{\mathbf w}\) \(\newcommand{\xvec}{\mathbf x}\) \(\newcommand{\yvec}{\mathbf y}\) \(\newcommand{\zvec}{\mathbf z}\) \(\newcommand{\rvec}{\mathbf r}\) \(\newcommand{\mvec}{\mathbf m}\) \(\newcommand{\zerovec}{\mathbf 0}\) \(\newcommand{\onevec}{\mathbf 1}\) \(\newcommand{\real}{\mathbb R}\) \(\newcommand{\twovec}[2]{\left[\begin{array}{r}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\ctwovec}[2]{\left[\begin{array}{c}#1 \\ #2 \end{array}\right]}\) \(\newcommand{\threevec}[3]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\cthreevec}[3]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \end{array}\right]}\) \(\newcommand{\fourvec}[4]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\cfourvec}[4]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \end{array}\right]}\) \(\newcommand{\fivevec}[5]{\left[\begin{array}{r}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\cfivevec}[5]{\left[\begin{array}{c}#1 \\ #2 \\ #3 \\ #4 \\ #5 \\ \end{array}\right]}\) \(\newcommand{\mattwo}[4]{\left[\begin{array}{rr}#1 \amp #2 \\ #3 \amp #4 \\ \end{array}\right]}\) \(\newcommand{\laspan}[1]{\text{Span}\{#1\}}\) \(\newcommand{\bcal}{\cal B}\) \(\newcommand{\ccal}{\cal C}\) \(\newcommand{\scal}{\cal S}\) \(\newcommand{\wcal}{\cal W}\) \(\newcommand{\ecal}{\cal E}\) \(\newcommand{\coords}[2]{\left\{#1\right\}_{#2}}\) \(\newcommand{\gray}[1]{\color{gray}{#1}}\) \(\newcommand{\lgray}[1]{\color{lightgray}{#1}}\) \(\newcommand{\rank}{\operatorname{rank}}\) \(\newcommand{\row}{\text{Row}}\) \(\newcommand{\col}{\text{Col}}\) \(\renewcommand{\row}{\text{Row}}\) \(\newcommand{\nul}{\text{Nul}}\) \(\newcommand{\var}{\text{Var}}\) \(\newcommand{\corr}{\text{corr}}\) \(\newcommand{\len}[1]{\left|#1\right|}\) \(\newcommand{\bbar}{\overline{\bvec}}\) \(\newcommand{\bhat}{\widehat{\bvec}}\) \(\newcommand{\bperp}{\bvec^\perp}\) \(\newcommand{\xhat}{\widehat{\xvec}}\) \(\newcommand{\vhat}{\widehat{\vvec}}\) \(\newcommand{\uhat}{\widehat{\uvec}}\) \(\newcommand{\what}{\widehat{\wvec}}\) \(\newcommand{\Sighat}{\widehat{\Sigma}}\) \(\newcommand{\lt}{<}\) \(\newcommand{\gt}{>}\) \(\newcommand{\amp}{&}\) \(\definecolor{fillinmathshade}{gray}{0.9}\)A renewal process is an idealized stochastic model for events
that occur randomly in time. These temporal events are generically referred to as renewals or arrivals. Here are some typical interpretations and applications.
- The arrivals are
customers
arriving at aservice station
. Again, the terms are generic. A customer might be a person and the service station a store, but also a customer might be a file request and the service station a web server. - A device is placed in service and eventually fails. It is replaced by a device of the same type and the process is repeated. We do not count the replacement time in our analysis; equivalently we can assume that the replacement is immediate. The times of the replacements are the renewals
- The arrivals are times of some natural event, such as a lightening strike, a tornado or an earthquake, at a particular geographical point.
- The arrivals are emissions of elementary particles from a radioactive source.
Basic Processes
The basic model actually gives rise to several interrelated random processes: the sequence of interarrival times, the sequence of arrival times, and the counting process. The term renewal process can refer to any (or all) of these. There are also several natural age
processes that arise. In this section we will define and study the basic properties of each of these processes in turn.
Interarrival Times
Let \(X_1\) denote the time of the first arrival, and \(X_i\) the time between the \((i - 1)\)st and \(i\)th arrivals for \(i \in \{2, 3, \ldots)\). Our basic assumption is that the sequence of interarrival times \(\bs{X} = (X_1, X_2, \ldots)\) is an independent, identically distributed sequence of random variables. In statistical terms, \(\bs{X}\) corresponds to sampling from the distribution of a generic interarrival time \(X\). We assume that \(X\) takes values in \([0, \infty)\) and \(\P(X \gt 0) \gt 0\), so that the interarrival times are nonnegative, but not identically 0. Let \(\mu = \E(X)\) denote the common mean of the interarrival times. We allow that possibility that \(\mu = \infty\). On the other hand,
\(\mu \gt 0\).
Proof
This is a basic fact from properties of expected value. For a simple proof, note that if \(\mu = 0\) then \(\P(X \gt x) = 0\) for every \(x \gt 0\) by Markov's inequality. But then \(\P(X = 0) = 1\).
If \(\mu \lt \infty\), we will let \(\sigma^2 = \var(X)\) denote the common variance of the interarrival times. Let \(F\) denote the common distribution function of the interarrival times, so that \[ F(x) = \P(X \le x), \quad x \in [0, \infty) \] The distribution function \(F\) turns out to be of fundamental importance in the study of renewal processes. We will let \(f\) denote the probability density function of the interarrival times if the distribution is discrete or if the distribution is continuous and has a probability density function (that is, if the distribution is absolutely continuous with respect to Lebesgue measure on \( [0, \infty) \)). In the discrete case, the following definition turns out to be important:
If \( X \) takes values in the set \( \{n d: n \in \N\} \) for some \( d \in (0, \infty) \), then \( X \) (or its distribution) is said to be arithmetic (the terms lattice and periodic are also used). The largest such \( d \) is the span of \( X \).
The reason the definition is important is because the limiting behavior of renewal processes turns out to be more complicated when the interarrival distribution is arithmetic.
The Arrival Times
Let \[ T_n = \sum_{i=1}^n X_i, \quad n \in \N \] We follow our usual convention that the sum over an empty index set is 0; thus \(T_0 = 0\). On the other hand, \(T_n\) is the time of the \(n\)th arrival for \(n \in \N_+\). The sequence \(\bs{T} = (T_0, T_1, \ldots)\) is called the arrival time process, although note that \(T_0\) is not considered an arrival. A renewal process is so named because the process starts over, independently of the past, at each arrival time.
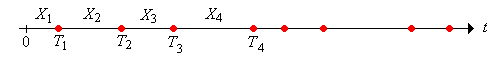
The sequence \(\bs{T}\) is the partial sum process associated with the independent, identically distributed sequence of interarrival times \(\bs{X}\). Partial sum processes associated with independent, identically distributed sequences have been studied in several places in this project. In the remainder of this subsection, we will collect some of the more important facts about such processes. First, we can recover the interarrival times from the arrival times: \[ X_i = T_i - T_{i-1}, \quad i \in \N_+ \] Next, let \(F_n\) denote the distribution function of \(T_n\), so that \[ F_n(t) = \P(T_n \le t), \quad t \in [0, \infty) \] Recall that if \(X\) has probability density function \(f\) (in either the discrete or continuous case), then \(T_n\) has probability density function \(f_n = f^{*n} = f * f * \cdots * f\), the \(n\)-fold convolution power of \(f\).
The sequence of arrival times \(\bs{T}\) has stationary, independent increments:
- If \(m \le n\) then \(T_n - T_m\) has the same distribution as \(T_{n-m}\) and thus has distribution function \(F_{n-m}\)
- If \(n_1 \le n_2 \le n_3 \le \cdots\) then \(\left(T_{n_1}, T_{n_2} - T_{n_1}, T_{n_3} - T_{n_2}, \ldots\right)\) is a sequence of independent random variables.
Proof
Recall that these are properties that hold generally for the partial sum sequence associated with a sequence of IID variables.
If \(n, \, m \in \N\) then
- \(\E\left(T_n\right) = n \mu\)
- \(\var\left(T_n\right) = n \sigma^2\)
- \(\cov\left(T_m, T_n\right) = \min\{m,n\} \sigma^2\)
Proof
Part (a) follows, of course, from the additive property of expected value, and part (b) from the additive property of variance for sums of independent variables. For part (c), assume that \(m \le n\). Then \(T_n = T_m + (T_n - T_m)\). But \(T_m\) and \(T_n - T_m\) are independent, so \[ \cov\left(T_m, T_n\right) = \cov\left[T_m, T_m + (T_n - T_m)\right] = \cov(T_m, T_m) + \cov(T_m, T_n - T_m) = \var(T_m) = m \sigma^2 \]
Recall the law of large numbers: \(T_n / n \to \mu\) as \(n \to \infty\)
- With probability 1 (the strong law).
- In probability (the weak law).
Note that \(T_n \le T_{n+1}\) for \(n \in \N\) since the interarrival times are nonnegative. Also \(\P(T_n = T_{n-1}) = \P(X_n = 0) = F(0)\). This can be positive, so with positive probability, more than one arrival can occur at the same time. On the other hand, the arrival times are unbounded:
\(T_n \to \infty\) as \(n \to \infty\) with probability 1.
Proof
Since \(\P(X \gt 0) \gt 0\), there exits \(t \gt 0\) such that \(\P(X \gt t) \gt 0\). From the second Borel-Cantelli lemma it follows that with probability 1, \(X_i \gt t\) for infinitely many \(n \in \N_+\). Therefore \(\sum_{i=1}^\infty X_i = \infty\) with probability 1.
The Counting Process
For \(t \ge 0\), let \(N_t\) denote the number of arrivals in the interval \([0, t]\): \[ N_t = \sum_{n=1}^\infty \bs{1}(T_n \le t), \quad t \in [0, \infty) \] We will refer to the random process \(\bs{N} = (N_t: t \ge 0)\) as the counting process. Recall again that \( T_0 = 0 \) is not considered an arrival, but it's possible to have \( T_n = 0 \) for \( n \in \N_+ \), so there may be one or more arrivals at time 0.
\(N_t = \max\{n \in \N: T_n \le t\}\) for \(t \ge 0\).
If \(s, \, t \in [0, \infty)\) and \(s \le t\) then \(N_t - N_s\) is the number of arrivals in \((s, t]\).
Note that as a function of \(t\), \(N_t\) is a (random) step function with jumps at the distinct values of \((T_1, T_2, \ldots)\); the size of the jump at an arrival time is the number of arrivals at that time. In particular, \(N\) is an increasing function of \(t\).
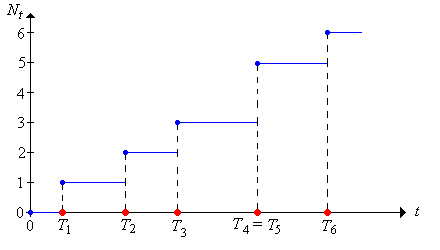
More generally, we can define the (random) counting measure corresponding to the sequence of random points \((T_1, T_2, \ldots)\) in \([0, \infty)\). Thus, if \(A\) is a (measurable) subset of \([0, \infty)\), we will let \(N(A)\) denote the number of the random points in \(A\): \[ N(A) = \sum_{n=1}^\infty \bs{1}(T_n \in A) \] In particular, note that with our new notation, \(N_t = N[0, t]\) for \(t \ge 0\) and \(N(s, t] = N_t - N_s\) for \(s \le t\). Thus, the random counting measure is completely determined by the counting process. The counting process is the cumulative measure function
for the counting measure, analogous the cumulative distribution function of a probability measure.
For \(t \ge 0\) and \(n \in \N\),
- \(T_n \le t\) if and only if \(N_t \ge n\)
- \(N_t = n\) if and only if \(T_n \le t \lt T_{n+1}\)
Proof
Note that the event in part (a) means that at there are at least \(n\) arrivals in \([0, t]\). The event in part (b) means that there are exactly \(n\) arrivals in \([0, t]\).
Of course, the complements of the events in (a) are also equivalent, so \( T_n \gt t \) if and only if \( N_t \lt n \). On the other hand, neither of the events \( N_t \le n \) and \( T_n \ge t \) implies the other. For example, we couse easily have \( N_t = n \) and \( T_n \lt t \lt T_{n + 1} \). Taking complements, neither of the events \( N_t \gt n \) and \( T_n \lt t \) implies the other. The last result also shows that the arrival time process \( \bs{T} \) and the counting process \( \bs{N} \) are inverses of each other in a sense.
The following events have probability 1:
- \(N_t \lt \infty\) for all \( t \in [0, \infty) \)
- \(N_t \to \infty\) as \(t \to \infty\)
Proof
The event in part (a) occurs if and only if \(T_n \to \infty\) as \(n \to \infty\), which occurs with probability 1 by the result above. The event in part (b) occurs if and only if \(T_n \lt \infty\) for all \(n \in \N\) which also occurs with probability 1.
All of the results so far in this subsection show that the arrival time process \(\bs{T}\) and the counting process \(\bs{N}\) are inverses of one another in a sense. The important equivalences above can be used to obtain the probability distribution of the counting variables in terms of the interarrival distribution function \(F\).
For \(t \ge 0\) and \(n \in \N\),
- \(\P(N_t \ge n) = F_n(t)\)
- \(\P(N_t = n) = F_n(t) - F_{n+1}(t)\)
The next result is little more than a restatement of the result above relating the counting process and the arrival time process. However, you may need to review the section on filtrations and stopping times to understand the result
For \( t \in [0, \infty) \), \( N_t + 1 \) is a stopping time for the sequence of interarrival times \( \bs{X} \)
Proof
Note that \( N_t + 1 \) takes values in \( \N_+ \), so we need to show that the event \( \left\{N_t + 1 = n\right\} \) is measurable with respect to \( \mathscr{F}_n = \sigma\{X_1, X_2, \ldots, X_n\} \) for \( n \in \N_+ \). But from the result above, \( N_t + 1 = n \) if and only if \( N_t = n - 1 \) if and only if \( T_{n-1} \le t \lt T_n \). The last event is clearly measurable with respect to \( \mathscr{F}_n \).
The Renewal Function
The function \( M \) that gives the expected number of arrivals up to time \(t\) is known as the renewal function: \[ M(t) = \E(N_t), \quad t \in [0, \infty) \]
The renewal function turns out to be of fundamental importance in the study of renewal processes. Indeed, the renewal function essentially characterizes the renewal process. It will take awhile to fully understand this, but the following theorem is a first step:
The renewal function is given in terms of the interarrival distribution function by \[ M(t) = \sum_{n=1}^\infty F_n(t), \quad 0 \le t \lt \infty \]
Proof
Recall that \(N_t = \sum_{n=1}^\infty \bs{1}(T_n \le t)\). Taking expected values gives the result. Note that the interchange of sum and expected value is valid because the terms are nonnegative.
Note that we have not yet shown that \(M(t) \lt \infty\) for \(t \ge 0\), and note also that this does not follow from the previous theorem. However, we will establish this finiteness condition in the subsection on moment generating functions below. If \( M \) is differentiable, the derivative \( m = M^\prime \) is known as the renewal density, so that \( m(t) \) gives the expected rate of arrivals per unit time at \( t \in [0, \infty) \).
More generally, if \(A\) is a (measurable) subset of \([0, \infty)\), let \(M(A) = \E[N(A)]\), the expected number of arrivals in \(A\).
\(M\) is a positive measure on \([0, \infty)\). This measure is known as the renewal measure.
Proof
\(N\) is a measure on \([0, \infty)\) (albeit a random one). So if \((A_1, A_2, \ldots)\) is a sequence of disjoint, measurable subsets of \([0, \infty)\) then \[ N\left(\bigcup_{i=1}^\infty A_i \right) = \sum_{i=1}^\infty N(A_i) \] Taking expected values gives \[ m\left(\bigcup_{i=1}^\infty A_i \right) = \sum_{i=1}^\infty m(A_i) \] Again, the interchange of sum and expected value is justified since the terms are nonnegative.
The renewal measure is also given by \[ M(A) = \sum_{n=1}^\infty \P(T_n \in A), \quad A \subset [0, \infty) \]
Proof
Recall that \(N(A) = \sum_{n=1}^\infty \bs{1}(T_n \in A)\). Taking expected values gives the result. Again, the interchange of expected value and infinite series is justified since the terms are nonnegative.
If \( s\, \, t \in [0, \infty) \) with \(s \le t\) then \(M(t) - M(s) = m(s, t]\), the expected number of arrivals in \((s, t]\).
The last theorem implies that the renewal function actually determines the entire renewal measure. The renewal function is the cumulative measure function
, analogous to the cumulative distribution function of a probability measure. Thus, every renewal process naturally leads to two measures on \([0, \infty)\), the random counting measure corresponding to the arrival times, and the measure associated with the expected number of arrivals.
The Age Processes
For \(t \in [0, \infty)\), \(T_{N_t} \le t \lt T_{N_t + 1}\). That is, \(t\) is in the random renewal interval \([T_{N_t}, T_{N_t + 1})\).
Consider the reliability setting in which whenever a device fails, it is immediately replaced by a new device of the same type. Then the sequence of interarrival times \(\bs{X}\) is the sequence of lifetimes, while \(T_n\) is the time that the \(n\)th device is placed in service. There are several other natural random processes that can be defined.
The random variable \[ C_t = t - T_{N_t}, \quad t \in [0, \infty) \] is called the current life at time \(t\). This variable takes values in the interval \([0, t]\) and is the age of the device that is in service at time \(t\). The random process \(\bs{C} = (C_t: t \ge 0)\) is the current life process.
The random variable \[ R_t = T_{N_t + 1} - t, \quad t \in [0, \infty) \] is called the remaining life at time \(t\). This variable takes values in the interval \((0, \infty)\) and is the time remaining until the device that is in service at time \(t\) fails. The random process \(\bs{R} = (R_t: t \ge 0)\) is the remaining life process.
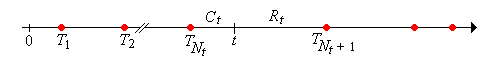
The random variable \[ L_t = C_t + R_t = T_{N_t+1} - T_{N_t} = X_{N_t + 1}, \quad t \in [0, \infty) \] is called the total life at time \(t\). This variable takes values in \([0, \infty)\) and gives the total life of the device that is in service at time \(t\). The random process \(\bs{L} = (L_t: t \ge 0)\) is the total life process.
Tail events of the current and remaining life can be written in terms of each other and in terms of the counting variables.
Suppose that \(t \in [0, \infty)\), \(x \in [0, t]\), and \(y \in [0, \infty)\). Then
- \(\{R_t \gt y\} = \{N_{t+y} - N_t = 0\}\)
- \(\{C_t \ge x \} = \{R_{t-x} \gt x\} = \{N_t - N_{t-x} = 0\}\)
- \(\{C_t \ge x, R_t \gt y\} = \{R_{t-x} \gt x + y\} = \{N_{t+y} - N_{t-x} = 0\}\)
Proof
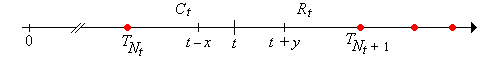
Of course, the various equivalent events in the last result must have the same probability. In particular, it follows that if we know the distribution of \(R_t\) for all \(t\) then we also know the distribution of \(C_t\) for all \(t\), and in fact we know the joint distribution of \( (R_t, C_t) \) for all \(t\) and hence also the distribution of \(L_t\) for all \(t\).
For fixed \( t \in (0, \infty) \) the total life at \( t \) (the lifetime of the device in service at time \( t \)) is stochastically larger than a generic lifetime. This result, a bit surprising at first, is known as the inspection paradox. Let \( X \) denote fixed interarrival time.
\( \P(L_t \gt x) \ge \P(X \gt x) \) for \( x \ge 0 \).
Proof
Recall that \( L_t = X_{N_t + 1} \). The proof is by conditioning on \( N_t \). An important tool is the fact that if \( A \) and \( B \) are nested events in a probability space (one a subset of the other), then the events are positively correlated, so that \( \P(A \mid B) \ge \P(A) \). Recall that \( F \) is the common CDF of the interarrival times. First \[ \P\left(X_{N_t + 1} \gt x \mid N_t = 0\right) = \P(X_1 \gt x \mid X_1 \gt t) \ge \P(X_1 \gt x) = 1 - F(x) \] Next, for \( n \in \N_+ \), \[ \P\left(X_{N_t + 1} \gt x \mid N_t = n\right) = \P\left(X_{n + 1} \gt x \mid T_n \le t \lt T_{n + 1}\right) = \P(X_{n+1} \gt x \mid T_n \le t \lt T_n + X_{n+1}) \] We condition this additionally on \( T_n \), the time of the \( n \)th arrival. For \( s \le t \), and since \( X_{n+1} \) is independent of \( T_n \), we have \[ \P(X_{n+1} \gt x \mid T_n = s, \, X_{n+1} \gt t - s) = \P(X_{n+1} \gt x \mid X_{n + 1} \gt t - s) \ge \P(X_{n + 1} \gt x) = 1 - F(x) \] It follows that \( \P\left(X_{N_t + 1} \gt x \mid N_t = n\right) \ge 1 - F(x) \) for every \( n \in \N \), and hence \[ \P\left(X_{N_t + 1} \gt x\right) = \sum_{n=0}^\infty \P\left(X_{N_t + 1} \gt x \mid N_t = n\right) \P(N_t = n) \ge \sum_{n=0}^\infty \left[1 - F(x)\right] \P(N_n = n) = 1 - F(x) \]
Basic Comparison
The basic comparison in the following result is often useful, particularly for obtaining various bounds. The idea is very simple: if the interarrival times are shortened, the arrivals occur more frequently.
Suppose now that we have two interarrival sequences, \(\bs{X} = (X_1, X_2, \ldots)\) and \(\bs{Y} = (Y_1, Y_2, \ldots)\) defined on the same probability space, with \(Y_i \le X_i\) (with probability 1) for each \(i\). Then for \(n \in \N\) and \(t \in [0, \infty)\),
- \(T_{Y,n} \le T_{X,n}\)
- \(N_{Y,t} \ge N_{X,t}\)
- \(m_Y(t) \ge m_X(t)\)
Examples and Special Cases
Bernoulli Trials
Suppose that \( \bs{X} = (X_1, X_2, \ldots) \) is a sequence of Bernoulli trials with success parameter \(p \in (0, 1)\). Recall that \(\bs{X}\) is a sequence of independent, identically distributed indicator variables with \(\P(X = 1) = p\).
Recall the random processes derived from \(\bs{X}\):
- \(\bs{Y} = (Y_0, Y_1, \ldots)\) where \(Y_n\) the number of success in the first \(n\) trials. The sequence \(\bs{Y}\) is the partial sum process associated with \(\bs{X}\). The variable \(Y_n\) has the binomial distribution with parameters \(n\) and \(p\).
- \(\bs{U} = (U_1, U_2, \ldots)\) where \(U_n\) the number of trials needed to go from success number \(n - 1\) to success number \(n\). These are independent variables, each having the geometric distribution on \( \N_+ \) with parameter \(p\).
- \(\bs{V} = (V_0, V_1, \ldots)\) where \(V_n\) is the trial number of success \(n\). The sequence \(\bs{V}\) is the partial sum process associated with \(\bs{U}\). The variable \(V_n\) has the negative binomial distribution with parameters \(n\) and \(p\).
It is natural to view the successes as arrivals in a discrete-time renewal process.
Consider the renewal process with interarrival sequence \(\bs{U}\). Then
- The basic assumptions are satisfied and that the mean interarrival time is \(\mu = 1 / p\).
- \(\bs{V}\) is the sequence of arrival times.
- \(\bs{Y}\) is the counting process (restricted to \(\N\)).
- The renewal function is \(m(n) = n p\) for \(n \in \N\).
It follows that the renewal measure is proportional to counting measure on \(\N_+\).
Run the binomial timeline experiment 1000 times for various values of the parameters \(n\) and \(p\). Compare the empirical distribution of the counting variable to the true distribution.
Run the negative binomial experiment 1000 times for various values of the parameters \(k\) and \(p\). Comare the empirical distribution of the arrival time to the true distribution.
Consider again the renewal process with interarrival sequence \(\bs{U}\). For \(n \in \N\),
- The current life and remaining life at time \(n\) are independent.
- The remaining life at time \(n\) has the same distribution as an interarrival time \(U\), namely the geometric distribution on \( \N_+ \) with parameter \(p\).
- The current life at time \(n\) has a truncated geometric distribution with parameters \(n\) and \(p\): \[ \P(C_n = k) = \begin{cases} p(1 - p)^k, & k \in \{0, 1, \ldots, n - 1\} \\ (1 - p)^n, & k = n \end{cases} \]
Proof
These results follow from age process events above.
This renewal process starts over, independently of the past, not only at the arrival times, but at fixed times \(n \in \N\) as well. The Bernoulli trials process (with the successes as arrivals) is the only discrete-time renewal process with this property, which is a consequence of the memoryless property of the geometric interarrival distribution.
We can also use the indicator variables as the interarrival times. This may seem strange at first, but actually turns out to be useful.
Consider the renewal process with interarrival sequence \(\bs{X}\).
- The basic assumptions are satisfied and that the mean interarrival time is \(\mu = p\).
- \(\bs{Y}\) is the sequence of arrival times.
- The number of arrivals at time 0 is \(U_1 - 1\) and the number of arrivals at time \(i \in \N_+\) is \(U_{i+1}\).
- The number of arrivals in the interval \([0, n]\) is \(V_{n+1} - 1\) for \(n \in \N\). This gives the counting process.
- The renewal function is \(m(n) = \frac{n + 1}{p} - 1\) for \(n \in \N\).
The age processes are not very interesting for this renewal process.
For \(n \in \N\) (with probability 1),
- \(C_n = 0\)
- \(R_n = 1\)
The Moment Generating Function of the Counting Variables
As an application of the last renewal process, we can show that the moment generating function of the counting variable \(N_t\) in an arbitrary renewal process is finite in an interval about 0 for every \(t \in [0, \infty)\). This implies that \(N_t\) has finite moments of all orders and in particular that \(m(t) \lt \infty\) for every \(t \in [0, \infty)\).
Suppose that \(\bs{X} = (X_1, X_2, \ldots)\) is the interarrival sequence for a renewal process. By the basic assumptions, there exists \(a \gt 0\) such that \(p = \P(X \ge a) \gt 0\). We now consider the renewal process with interarrival sequence \(\bs{X}_a = (X_{a,1}, X_{a,2}, \ldots)\), where \(X_{a,i} = a\,\bs{1}(X_i \ge a)\) for \(i \in \N_+\). The renewal process with interarrival sequence \(\bs{X}_a\) is just like the renewal process with Bernoulli interarrivals, except that the arrival times occur at the points in the sequence \((0, a, 2 a, \ldots)\), instead of \( (0, 1, 2, \ldots) \).
For each \(t \in [0, \infty)\), \(N_t\) has finite moment generating function in an interval about 0, and hence \( N_t \) has moments of all orders at 0.
Proof
Note first that \(X_{a,i} \le X_i\) for each \(i \in \N_+\). Recall the moment generating function \(\Gamma\) of the geometric distribution with parameter \(p\) is \[ \Gamma(s) = \frac{e^s p}{1 - (1 - p) e^s}, \quad s \lt -\ln(1 - p) \] But as with the process with Bernoulli interarrival times, \(N_{a,t}\) can be written as \(a (V_{n + 1} - 1)\) where \(n = \lfloor a / t \rfloor\) and where \(V_{n + 1}\) is a sum of \(n + 1\) IID geometric variables, each with parameter \(p\). We don't really care about the explicit form of the MGF of \(N_{a, t}\), but it is clearly finite in an interval of the from \((-\infty, \epsilon)\) where \(\epsilon \gt 0\). But \(N_t \le N_{t,a}\), so its MGF is also finite on this interval.
The Poisson Process
The Poisson process, named after Simeon Poisson, is the most important of all renewal processes. The Poisson process is so important that it is treated in a separate chapter in this project. Please review the essential properties of this process:
Properties of the Poisson process with rate \( r \in (0, \infty) \).
- The interarrival times have an exponential distribution with rate parameter \(r\). Thus, the basic assumptions above are satisfied and the mean interarrival time is \(\mu = 1 / r\).
- The exponential distribution is the only distribution with the memoryless property on \([0, \infty)\).
- The time of the \(n\)th arrival \(T_n\) has the gamma distribution with shape parameter \(n\) and rate parameter \(r\).
- The counting process \(\bs{N} = (N_t: t \ge 0)\) has stationary, independent increments and \(N_t\) has the Poisson distribution with parameter \(r t\) for \(t \in [0, \infty)\).
- In particular, the renewal function is \(m(t) = r t\) for \(t \in [0, \infty)\). Hence, the renewal measure is a multiple of the standard length measure (Lebesgue measure) on \([0, \infty)\).
Consider again the Poisson process with rate parameter \(r\). For \(t \in [0, \infty)\),
- The current life and remaining life at time \(t\) are independent.
- The remaining life at time \(t\) has the same distribution as an interarrival time \(X\), namely the exponential distribution with rate parameter \(r\).
- The current life at time \(t\) has a truncated exponential distribution with parameters \(t\) and \(r\): \[ \P(C_t \ge s) = \begin{cases} e^{-r s}, & 0 \le s \le t \\ 0, & s \gt t \end{cases} \]
Proof
These results follow from age process events given above.
The Poisson process starts over, independently of the past, not only at the arrival times, but at fixed times \(t \in [0, \infty)\) as well. The Poisson process is the only renewal process with this property, which is a consequence of the memoryless property of the exponential interarrival distribution.
Run the Poisson experiment 1000 times for various values of the parameters \(t\) and \(r\). Compare the empirical distribution of the counting variable to the true distribution.
Run the gamma experiment 1000 times for various values of the parameters \(n\) and \(r\). Compare the empirical distribution of the arrival time to the true distribution.
Simulation Exercises
Open the renewal experiment and set \( t = 10 \). For each of the following interarrival distributions, run the simulation 1000 times and note the shape and location of the empirical distribution of the counting variable. Note also the mean of the interarrival distribution in each case.
- The continuous uniform distribution on the interval \( [0, 1] \) (the standard uniform distribution).
- the discrete uniform distribution starting at \( a = 0 \), with step size \( h = 0.1 \), and with \( n = 10 \) points.
- The gamma distribution with shape parameter \( k = 2 \) and scale parameter \( b = 1 \).
- The beta distribution with left shape parameter \( a = 3 \) and right shape parameter \( b = 2 \).
- The exponential-logarithmic distribution with shape parameter \( p = 0.1 \) and scale parameter \( b = 1 \).
- The Gompertz distribution with shape paraemter \( a = 1 \) and scale parameter \( b = 1 \).
- The Wald distribution with mean \( \mu = 1 \) and shape parameter \( \lambda = 1 \).
- The Weibull distribution with shape parameter \( k = 2 \) and scale parameter \( b = 1 \).