
5.2: Important Densities
- Page ID
- 3141

In this section, we will introduce some important probability density functions and give some examples of their use. We will also consider the question of how one simulates a given density using a computer.
Continuous Uniform Density
The simplest density function corresponds to the random variable \(U\) whose value represents the outcome of the experiment consisting of choosing a real number at random from the interval \([a, b]\). \[f(\omega) = \left \{ \matrix{ 1/(b - a), &\,\,\, \mbox{if}\,\,\, a \leq \omega \leq b, \cr 0, &\,\,\, \mbox{otherwise.}\cr}\right.\]
It is easy to simulate this density on a computer. We simply calculate the expression \[(b - a) rnd + a\ .\]
Exponential and Gamma Densities
The exponential density function is defined by
\[f(x) = \left \{ \matrix{ \lambda e^{-\lambda x}, &\,\,\, \mbox{if}\,\,\, 0 \leq x < \infty, \cr 0, &\,\,\, \mbox{otherwise}. \cr} \right.\]
Here \(\lambda\) is any positive constant, depending on the experiment. The reader has seen this density in Example 2.2.11. In Figure \(\PageIndex{1}\) we show graphs of several exponential densities for different choices of \(\lambda\). The exponential density is often used to describe experiments involving a question of the form: How long until something happens? For example, the exponential density is often used to study the time between emissions of particles from a radioactive source.

The cumulative distribution function of the exponential density is easy to compute. Let \(T\) be an exponentially distributed random variable with parameter \(\lambda\). If \(x \ge 0\), then we have
\[\begin{aligned} F(x) & = & P(T \le x) \\ & = & \int_0^x \lambda e^{-\lambda t}\,dt \\ & = & 1 - e^{-\lambda x}\ .\\\end{aligned}\]
Both the exponential density and the geometric distribution share a property known as the “memoryless" property. This property was introduced in Example 5.1.1; it says that \[P(T > r + s\,|\,T > r) = P(T > s)\ .\] This can be demonstrated to hold for the exponential density by computing both sides of this equation. The right-hand side is just \[1 - F(s) = e^{-\lambda s}\ ,\] while the left-hand side is
\[\begin{align} {\frac{P(T > r + s)}{P(T > r)}} & = & {\frac{1 - F(r + s)}{1 - F(r)}} & = & {\frac{e^{-\lambda (r+s)}}{e^{-\lambda r}}} \\ & = & e^{-\lambda s}\end{align}\]
There is a very important relationship between the exponential density and the Poisson distribution. We begin by defining \(X_1,\ X_2,\ \ldots\) to be a sequence of independent exponentially distributed random variables with parameter \(\lambda\). We might think of \(X_i\) as denoting the amount of time between the \(i\)th and \((i+1)\)st emissions of a particle by a radioactive source. (As we shall see in Chapter 6, we can think of the parameter \(\lambda\) as representing the reciprocal of the average length of time between emissions. This parameter is a quantity that might be measured in an actual experiment of this type.)
We now consider a time interval of length \(t\), and we let \(Y\) denote the random variable which counts the number of emissions that occur in the time interval. We would like to calculate the distribution function of \(Y\) (clearly, \(Y\) is a discrete random variable). If we let \(S_n\) denote the sum \(X_1 + X_2 + \cdots + X_n\), then it is easy to see that \[P(Y = n) = P(S_n \le t\ \mbox{and}\ S_{n+1} > t)\ .\] Since the event \(S_{n+1} \le t\) is a subset of the event \(S_n \le t\), the above probability is seen to be equal to
\[P(S_n \le t) - P(S_{n+1} \le t)\ .\label{eq 5.8}\]
We will show in Chapter 7 that the density of \(S_n\) is given by the following formula: \[g_n(x) = \left \{ \begin{array}{ll} \lambda{ \frac{(\lambda x)^{n-1}}{(n-1)!}}e^{-\lambda x}, & \mbox{if $x > 0$,} \\ 0, & \mbox{otherwise.} \end{array} \right.\] This density is an example of a gamma density with parameters \(\lambda\) and \(n\). The general gamma density allows \(n\) to be any positive real number. We shall not discuss this general density.
It is easy to show by induction on \(n\) that the cumulative distribution function of \(S_n\) is given by:
\[G_n(x) = \left \{ \begin{array}{ll} 1 - e^{-\lambda x}\bigg(1+\frac{\lambda x}{1!} + \cdots + \frac{(\lambda x)^{n-1}}{(n-1)!}\bigg), & \text{if } x > 0, \\ 0, & \mbox{otherwise.} \end{array} \right.\]
Using this expression, the quantity in ([eq 5.8]) is easy to compute; we obtain \[e^{-\lambda t}\frac{(\lambda t)^n}{n!} ,\]
which the reader will recognize as the probability that a Poisson-distributed random variable, with parameter \(\lambda t\), takes on the value \(n\).
The above relationship will allow us to simulate a Poisson distribution, once we have found a way to simulate an exponential density. The following random variable does the job:
\[Y = -{1\over\lambda} \log(rnd)\ .\label{eq 5.9}\]
Using Corollary \(\PageIndex{1}\) (below), one can derive the above expression (see Exercise \(\PageIndex{3}\)). We content ourselves for now with a short calculation that should convince the reader that the random variable \(Y\) has the required property. We have
\[\begin{aligned} P(Y \le y) & = & P\Bigl(-{1\over\lambda} \log(rnd) \le y\Bigr) \\ & = & P(\log(rnd) \ge -\lambda y) \\ & = & P(rnd \ge e^{-\lambda y}) \\ & = & 1 - e^{-\lambda y}\ . \\\end{aligned}\]
This last expression is seen to be the cumulative distribution function of an exponentially distributed random variable with parameter \(\lambda\).
To simulate a Poisson random variable \(W\) with parameter \(\lambda\), we simply generate a sequence of values of an exponentially distributed random variable with the same parameter, and keep track of the subtotals \(S_k\) of these values. We stop generating the sequence when the subtotal first exceeds \(\lambda\). Assume that we find that \[S_n \le \lambda < S_{n+1}\ .\] Then the value \(n\) is returned as a simulated value for \(W\).
Suppose that customers arrive at random times at a service station with one server, and suppose that each customer is served immediately if no one is ahead of him, but must wait his turn in line otherwise. How long should each customer expect to wait? (We define the waiting time of a customer to be the length of time between the time that he arrives and the time that he begins to be served.)
- Answer
-
Let us assume that the interarrival times between successive customers are given by random variables \(X_1\), \(X_2\), …, \(X_n\) that are mutually independent and identically distributed with an exponential cumulative distribution function given by \[F_X(t) = 1 - e^{-\lambda t}.\] Let us assume, too, that the service times for successive customers are given by random variables \(Y_1\), \(Y_2\), …, \(Y_n\) that again are mutually independent and identically distributed with another exponential cumulative distribution function given by \[F_Y(t) = 1 - e^{-\mu t}.\]
The parameters \(\lambda\) and \(\mu\) represent, respectively, the reciprocals of the average time between arrivals of customers and the average service time of the customers. Thus, for example, the larger the value of \(\lambda\), the smaller the average time between arrivals of customers. We can guess that the length of time a customer will spend in the queue depends on the relative sizes of the average interarrival time and the average service time.
It is easy to verify this conjecture by simulation. The program Queue simulates this queueing process. Let \(N(t)\) be the number of customers in the queue at time \(t\). Then we plot \(N(t)\) as a function of \(t\) for different choices of the parameters \(\lambda\) and \(\mu\) (see Figure \(\PageIndex{1}\) ).
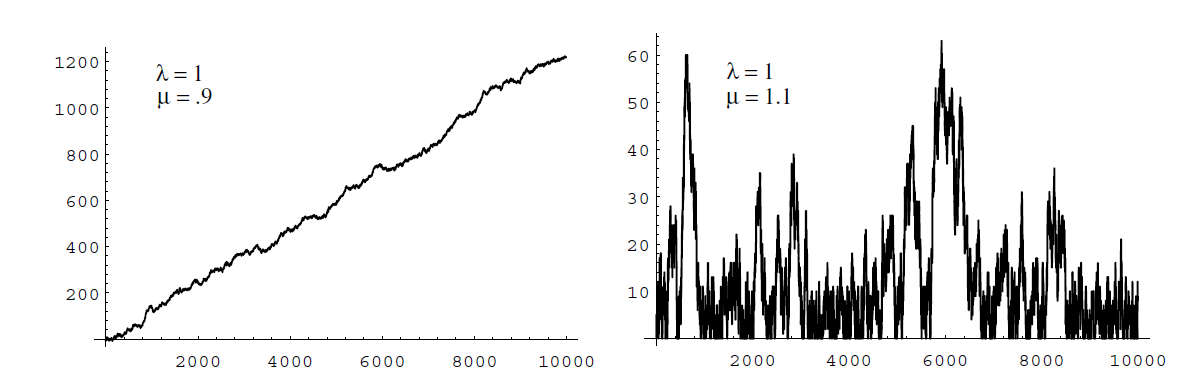
Figure \(\PageIndex{2}\): Queue sizes. 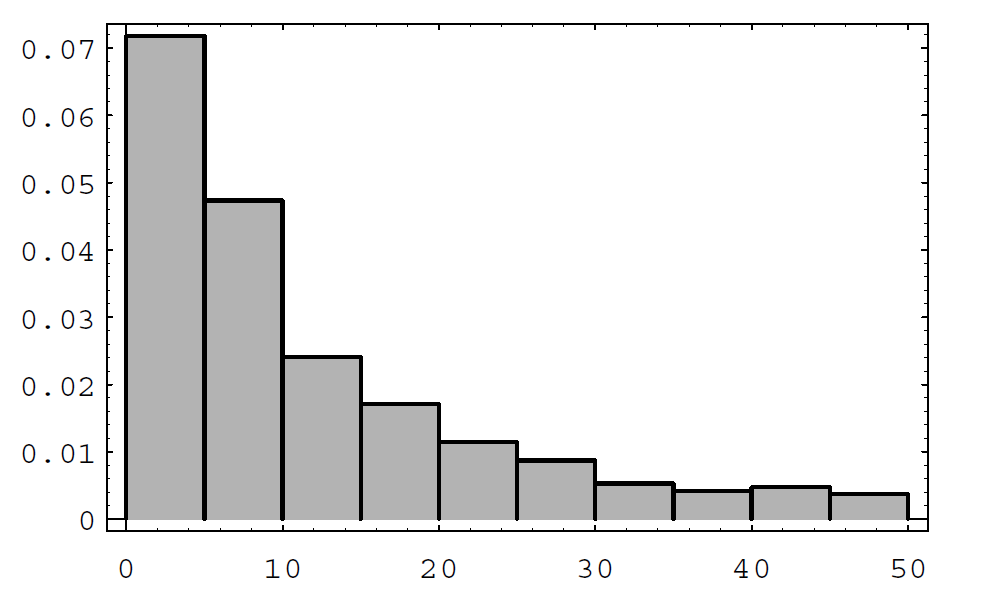
Figure \(\PageIndex{3}\): Waiting times. We note that when \(\lambda < \mu\), then \(1/\lambda > 1/\mu\), so the average interarrival time is greater than the average service time, i.e., customers are served more quickly, on average, than new ones arrive. Thus, in this case, it is reasonable to expect that \(N(t)\) remains small. However, if \(\lambda > \mu\) then customers arrive more quickly than they are served, and, as expected, \(N(t)\) appears to grow without limit.
We can now ask: How long will a customer have to wait in the queue for service? To examine this question, we let \(W_i\) be the length of time that the \(i\)th customer has to remain in the system (waiting in line and being served). Then we can present these data in a bar graph, using the program Queue, to give some idea of how the \(W_i\) are distributed (see Figure \(\PageIndex{3}\)). (Here \(\lambda = 1\) and \(\mu = 1.1\).)
We see that these waiting times appear to be distributed exponentially. This is always the case when \(\lambda < \mu\). The proof of this fact is too complicated to give here, but we can verify it by simulation for different choices of \(\lambda\) and \(\mu\), as above.
Functions of a Random Variable
Before continuing our list of important densities, we pause to consider random variables which are functions of other random variables. We will prove a general theorem that will allow us to derive expressions such as Equation [eq 5.9].
Let \(X\) be a continuous random variable, and suppose that \(\phi(x)\) is a strictly increasing function on the range of \(X\). Define \(Y = \phi(X)\). Suppose that \(X\) and \(Y\) have cumulative distribution functions \(F_X\) and \(F_Y\) respectively. Then these functions are related by \[F_Y(y) = F_X(\phi^{-1}(y)).\] If \(\phi(x)\) is strictly decreasing on the range of \(X\), then \[F_Y(y) = 1 - F_X(\phi^{-1}(y))\ .\]
- Proof
-
Since \(\phi\) is a strictly increasing function on the range of \(X\), the events \((X \le \phi^{-1}(y))\) and \((\phi(X) \le y)\) are equal. Thus, we have \[\begin{aligned} F_Y(y) & = & P(Y \le y) \\ & = & P(\phi(X) \le y) \\ & = & P(X \le \phi^{-1}(y)) \\ & = & F_X(\phi^{-1}(y))\ . \\\end{aligned}\]
If \(\phi(x)\) is strictly decreasing on the range of \(X\), then we have \[\begin{aligned} F_Y(y) & = & P(Y \leq y) \\ & = & P(\phi(X) \leq y) \\ & = & P(X \geq \phi^{-1}(y)) \\ & = & 1 - P(X < \phi^{-1}(y)) \\ & = & 1 - F_X(\phi^{-1}(y))\ . \\\end{aligned}\] This completes the proof.
Let \(X\) be a continuous random variable, and suppose that \(\phi(x)\) is a strictly increasing function on the range of \(X\). Define \(Y = \phi(X)\). Suppose that the density functions of \(X\) and \(Y\) are \(f_X\) and \(f_Y\), respectively. Then these functions are related by
\[f_Y(y) = f_X ( \phi^{-1}(y)){\frac{d}{dy}}\phi^{-1}(y) \]
If \(\phi(x)\) is strictly decreasing on the range of \(X\), then \[f_Y(y) = -f_X(\phi^{-1}(y)){\frac{d }{dy}}\phi^{-1}(y) \]
- Proof
-
This result follows from Theorem 5.1.1 by using the Chain Rule.
If the function \(\phi\) is neither strictly increasing nor strictly decreasing, then the situation is somewhat more complicated but can be treated by the same methods. For example, suppose that \(Y = X^2\), Then \(\phi(x) = x^2\), and \[\begin{aligned} F_Y(y) & = & P(Y \leq y) \\ & = & P(-\sqrt y \leq X \leq +\sqrt y) \\ & = & P(X \leq +\sqrt y) - P(X \leq -\sqrt y) \\ & = & F_X(\sqrt y) - F_X(-\sqrt y)\ .\\\end{aligned}\] Moreover, \[\begin{aligned} f_Y(y) & = & \frac d{dy} F_Y(y) \\ & = & \frac d{dy} (F_X(\sqrt y) - F_X(-\sqrt y)) \\ & = & \Bigl(f_X(\sqrt y) + f_X(-\sqrt y)\Bigr) \frac 1{2\sqrt y}\ . \\\end{aligned}\]
We see that in order to express \(F_Y\) in terms of \(F_X\) when \(Y = \phi(X)\), we have to express \(P(Y \leq y)\) in terms of \(P(X \leq x)\), and this process will depend in general upon the structure of \(\phi\).
Simulation
Theorem \(\PageIndex{1}\) tells us, among other things, how to simulate on the computer a random variable \(Y\) with a prescribed cumulative distribution function \(F\). We assume that \(F(y)\) is strictly increasing for those values of \(y\) where \(0 < F(y) < 1\). For this purpose, let \(U\) be a random variable which is uniformly distributed on \([0, 1]\). Then \(U\) has cumulative distribution function \(F_U(u) = u\). Now, if \(F\) is the prescribed cumulative distribution function for \(Y\), then to write \(Y\) in terms of \(U\) we first solve the equation
\[F(y) = u\]
for \(y\) in terms of \(u\). We obtain \(y = F^{-1}(u)\). Note that since \(F\) is an increasing function this equation always has a unique solution (see Figure 5.9). Then we set \(Z = F^{-1}(U)\) and obtain, by Theorem \(\PageIndex{1}\),
\[F_Z(y) = F_U(F(y)) = F(y)\ ,\]
since \(F_U(u) = u\). Therefore, \(Z\) and \(Y\) have the same cumulative distribution function. Summarizing, we have the following.
If \(F(y)\) is a given cumulative distribution function that is strictly increasing when \(0 < F(y) < 1\) and if \(U\) is a random variable with uniform distribution on \([0,1]\), then
\[Y = F^{-1}(U)\] h
as the cumulative distribution \(F(y)\)
Thus, to simulate a random variable with a given cumulative distribution \(F\) we need only set \(Y = F^{-1}(\mbox{rnd})\).

Normal Density
We now come to the most important density function, the normal density function. We have seen in Chapter 3 that the binomial distribution functions are bell-shaped, even for moderate size values of \(n\). We recall that a binomially-distributed random variable with parameters \(n\) and \(p\) can be considered to be the sum of \(n\) mutually independent 0-1 random variables. A very important theorem in probability theory, called the Central Limit Theorem, states that under very general conditions, if we sum a large number of mutually independent random variables, then the distribution of the sum can be closely approximated by a certain specific continuous density, called the normal density. This theorem will be discussed in Chapter 9.
The normal density function with parameters \(\mu\) and \(\sigma\) is defined as follows:
\[f_X(x) = \frac 1{\sqrt{2\pi}\sigma} e^{-(x - \mu)^2/2\sigma^2}\ .\]
The parameter \(\mu\) represents the “center" of the density (and in Chapter 6, we will show that it is the average, or expected, value of the density). The parameter \(\sigma\) is a measure of the “spread" of the density, and thus it is assumed to be positive. (In Chapter 6, we will show that \(\sigma\) is the standard deviation of the density.) We note that it is not at all obvious that the above function is a density, i.e., that its integral over the real line equals 1. The cumulative distribution function is given by the formula
\[F_X(x) = \int_{-\infty}^x \frac 1{\sqrt{2\pi}\sigma} e^{-(u - \mu)^2/2\sigma^2}\,du\ .\]
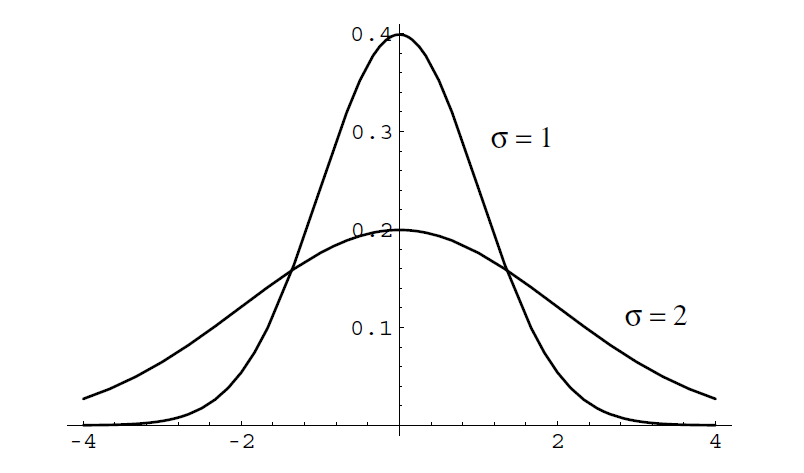
In Figure \(\PageIndex{3}\) we have included for comparison a plot of the normal density for the cases \(\mu = 0\) and \(\sigma = 1\), and \(\mu = 0\) and \(\sigma = 2\).
One cannot write \(F_X\) in terms of simple functions. This leads to several problems. First of all, values of \(F_X\) must be computed using numerical integration. Extensive tables exist containing values of this function (see Appendix A). Secondly, we cannot write \(F^{-1}_X\) in closed form, so we cannot use Corollary \(\PageIndex{2}\) to help us simulate a normal random variable. For this reason, special methods have been developed for simulating a normal distribution. One such method relies on the fact that if \(U\) and \(V\) are independent random variables with uniform densities on \([0,1]\), then the random variables \[X = \sqrt{-2\log U} \cos 2\pi V\] and \[Y = \sqrt{-2\log U} \sin 2\pi V\] are independent, and have normal density functions with parameters \(\mu = 0\) and \(\sigma = 1\). (This is not obvious, nor shall we prove it here. See Box and Muller.9)
Let \(Z\) be a normal random variable with parameters \(\mu = 0\) and \(\sigma = 1\). A normal random variable with these parameters is said to be a normal random variable. It is an important and useful fact that if we write \[X = \sigma Z + \mu\ ,\] then \(X\) is a normal random variable with parameters \(\mu\) and \(\sigma\). To show this, we will use Theorem 5.1.1. We have \(\phi(z) = \sigma z + \mu\), \(\phi^{-1}(x) = (x - \mu)/\sigma\), and
\[\begin{aligned} F_X(x) & = & F_Z\left(\frac {x - \mu}\sigma \right), \\ f_X(x) & = & f_Z\left(\frac {x - \mu}\sigma \right) \cdot \frac 1\sigma \\ & = & \frac 1{\sqrt{2\pi}\sigma} e^{-(x - \mu)^2/2\sigma^2}\ . \\\end{aligned}\]
The reader will note that this last expression is the density function with parameters \(\mu\) and \(\sigma\), as claimed.
We have seen above that it is possible to simulate a standard normal random variable \(Z\). If we wish to simulate a normal random variable \(X\) with parameters \(\mu\) and \(\sigma\), then we need only transform the simulated values for \(Z\) using the equation \(X = \sigma Z + \mu\).
Suppose that we wish to calculate the value of a cumulative distribution function for the normal random variable \(X\), with parameters \(\mu\) and \(\sigma\). We can reduce this calculation to one concerning the standard normal random variable \(Z\) as follows:
\[\begin{aligned} F_X(x) & = & P(X \leq x) \\ & = & P\left(Z \leq \frac {x - \mu}\sigma \right) \\ & = & F_Z\left(\frac {x - \mu}\sigma \right)\ . \\\end{aligned}\]
This last expression can be found in a table of values of the cumulative distribution function for a standard normal random variable. Thus, we see that it is unnecessary to make tables of normal distribution functions with arbitrary \(\mu\) and \(\sigma\).
The process of changing a normal random variable to a standard normal random variable is known as standardization. If \(X\) has a normal distribution with parameters \(\mu\) and \(\sigma\) and if \[Z = \frac{X - \mu}\sigma\ ,\] then \(Z\) is said to be the standardized version of \(X\).
The following example shows how we use the standardized version of a normal random variable \(X\) to compute specific probabilities relating to \(X\).
Suppose that \(X\) is a normally distributed random variable with parameters \(\mu = 10\) and \(\sigma = 3\). Find the probability that \(X\) is between 4 and 16.
- Answer
-
To solve this problem, we note that \(Z = (X-10)/3\) is the standardized version of \(X\). So, we have
\[\begin{aligned} P(4 \le X \le 16) & = & P(X \le 16) - P(X \le 4) \\ & = & F_X(16) - F_X(4) \\ & = & F_Z\left(\frac {16 - 10}3 \right) - F_Z\left(\frac {4-10}3 \right) \\ & = & F_Z(2) - F_Z(-2)\ . \\\end{aligned}\]
This last expression can be evaluated by using tabulated values of the standard normal distribution function (see [app_a]); when we use this table, we find that \(F_Z(2) = .9772\) and \(F_Z(-2) = .0228\). Thus, the answer is .9544.
In Chapter 6, we will see that the parameter \(\mu\) is the mean, or average value, of the random variable \(X\). The parameter \(\sigma\) is a measure of the spread of the random variable, and is called the standard deviation. Thus, the question asked in this example is of a typical type, namely, what is the probability that a random variable has a value within two standard deviations of its average value.
Maxwell and Rayleigh Densities
Suppose that we drop a dart on a large table top, which we consider as the \(x\)\(y\)-plane, and suppose that the \(x\) and \(y\) coordinates of the dart point are independent and have a normal distribution with parameters \(\mu = 0\) and \(\sigma = 1\). How is the distance of the point from the origin distributed?
- Answer
-
This problem arises in physics when it is assumed that a moving particle in \(R^n\) has components of the velocity that are mutually independent and normally distributed and it is desired to find the density of the speed of the particle. The density in the case \(n = 3\) is called the Maxwell density.
The density in the case \(n = 2\) (i.e. the dart board experiment described above) is called the Rayleigh density. We can simulate this case by picking independently a pair of coordinates \((x,y)\), each from a normal distribution with \(\mu = 0\) and \(\sigma = 1\) on \((-\infty,\infty)\), calculating the distance \(r = \sqrt{x^2 + y^2}\) of the point \((x,y)\) from the origin, repeating this process a large number of times, and then presenting the results in a bar graph. The results are shown in Figure \(\PageIndex{4}\)
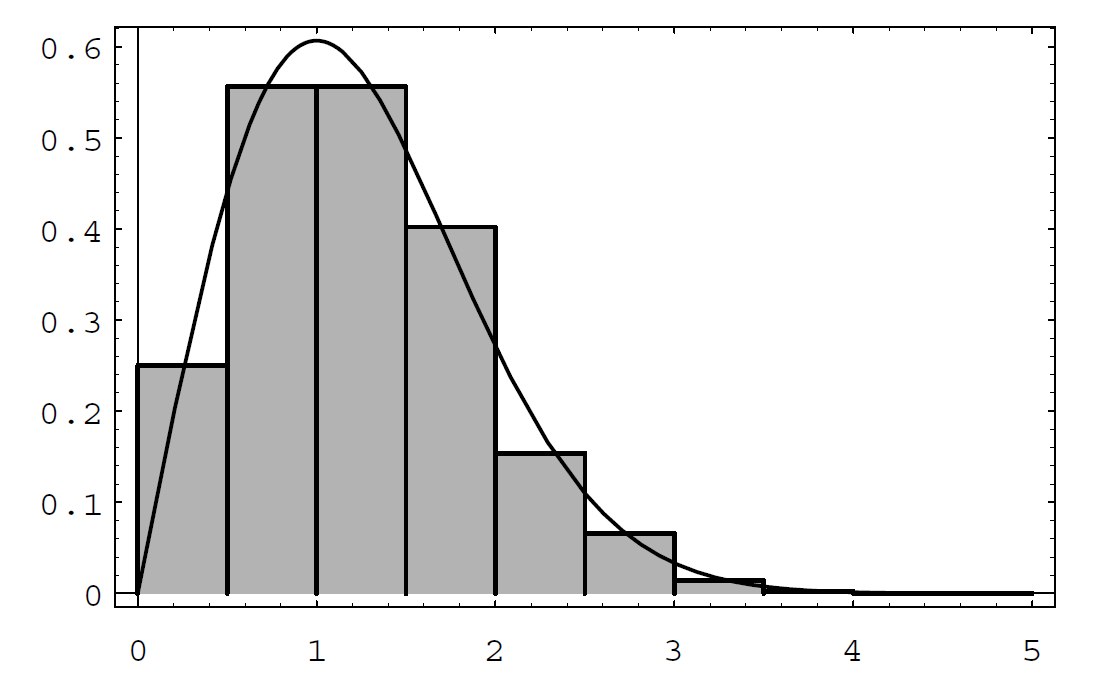
Figure \(\PageIndex{4}\): Distribution of dart distances in 1000 drops. We have also plotted the theoretical density \[f(r) = re^{-r^2/2}\ .\] This will be derived in Chapter 7; see Example 7.2.5
Chi-Squared Density
We return to the problem of independence of traits discussed in Example 5.1.6. It is frequently the case that we have two traits, each of which have several different values. As was seen in the example, quite a lot of calculation was needed even in the case of two values for each trait. We now give another method for testing independence of traits, which involves much less calculation.
Suppose that we have the data shown in Table \(\PageIndex{1}\) concerning grades and gender of students in a Calculus class.
| Female |
Male |
||
|---|---|---|---|
| A |
37 |
56 |
93 |
| B |
63 |
60 |
123 |
| C |
47 |
43 |
90 |
| Below C |
5 |
8 |
13 |
|
152 |
167 |
319 |
We can use the same sort of model in this situation as was used in Example 5.1.6. We imagine that we have an urn with 319 balls of two colors, say blue and red, corresponding to females and males, respectively. We now draw 93 balls, without replacement, from the urn. These balls correspond to the grade of A. We continue by drawing 123 balls, which correspond to the grade of B. When we finish, we have four sets of balls, with each ball belonging to exactly one set. (We could have stipulated that the balls were of four colors, corresponding to the four possible grades. In this case, we would draw a subset of size 152, which would correspond to the females. The balls remaining in the urn would correspond to the males. The choice does not affect the final determination of whether we should reject the hypothesis of independence of traits.)
The expected data set can be determined in exactly the same way as in Example 5.1.6. If we do this, we obtain the expected values shown in Table \(\PageIndex{2}\).
| Female |
Male |
||
|---|---|---|---|
| A |
44.3 |
48.7 |
93 |
| B |
58.6 |
64.4 |
123 |
| C |
42.9 |
47.1 |
90 |
| Below C |
6.2 |
6.8 |
13 |
| 152 | 167 |
319 |
Even if the traits are independent, we would still expect to see some differences between the numbers in corresponding boxes in the two tables. However, if the differences are large, then we might suspect that the two traits are not independent. In Example 5.1.6, we used the probability distribution of the various possible data sets to compute the probability of finding a data set that differs from the expected data set by at least as much as the actual data set does. We could do the same in this case, but the amount of computation is enormous.
Instead, we will describe a single number which does a good job of measuring how far a given data set is from the expected one. To quantify how far apart the two sets of numbers are, we could sum the squares of the differences of the corresponding numbers. (We could also sum the absolute values of the differences, but we would not want to sum the differences.) Suppose that we have data in which we expect to see 10 objects of a certain type, but instead we see 18, while in another case we expect to see 50 objects of a certain type, but instead we see 58. Even though the two differences are about the same, the first difference is more surprising than the second, since the expected number of outcomes in the second case is quite a bit larger than the expected number in the first case. One way to correct for this is to divide the individual squares of the differences by the expected number for that box. Thus, if we label the values in the eight boxes in the first table by \(O_i\) (for observed values) and the values in the eight boxes in the second table by \(E_i\) (for expected values), then the following expression might be a reasonable one to use to measure how far the observed data is from what is expected: \[\sum_{i = 1}^8 \frac{(O_i - E_i)^2}{E_i}\ .\] This expression is a random variable, which is usually denoted by the symbol \(\chi^2\), pronounced “ki-squared." It is called this because, under the assumption of independence of the two traits, the density of this random variable can be computed and is approximately equal to a density called the chi-squared density. We choose not to give the explicit expression for this density, since it involves the gamma function, which we have not discussed. The chi-squared density is, in fact, a special case of the general gamma density.
In applying the chi-squared density, tables of values of this density are used, as in the case of the normal density. The chi-squared density has one parameter \(n\), which is called the number of degrees of freedom. The number \(n\) is usually easy to determine from the problem at hand. For example, if we are checking two traits for independence, and the two traits have \(a\) and \(b\) values, respectively, then the number of degrees of freedom of the random variable \(\chi^2\) is \((a-1)(b-1)\). So, in the example at hand, the number of degrees of freedom is 3.
We recall that in this example, we are trying to test for independence of the two traits of gender and grades. If we assume these traits are independent, then the ball-and-urn model given above gives us a way to simulate the experiment. Using a computer, we have performed 1000 experiments, and for each one, we have calculated a value of the random variable \(\chi^2\). The results are shown in Figure \(\PageIndex{5}\), together with the chi-squared density function with three degrees of freedom.

As we stated above, if the value of the random variable \(\chi^2\) is large, then we would tend not to believe that the two traits are independent. But how large is large? The actual value of this random variable for the data above is 4.13. In Figure [fig 5.14.5], we have shown the chi-squared density with 3 degrees of freedom. It can be seen that the value 4.13 is larger than most of the values taken on by this random variable.
Typically, a statistician will compute the value \(v\) of the random variable \(\chi^2\), just as we have done. Then, by looking in a table of values of the chi-squared density, a value \(v_0\) is determined which is only exceeded 5% of the time. If \(v \ge v_0\), the statistician rejects the hypothesis that the two traits are independent. In the present case, \(v_0 = 7.815\), so we would not reject the hypothesis that the two traits are independent.
Cauchy Density
The following example is from Feller.10
Suppose that a mirror is mounted on a vertical axis, and is free to revolve about that axis. The axis of the mirror is 1 foot from a straight wall of infinite length. A pulse of light is shown onto the mirror, and the reflected ray hits the wall. Let \(\phi\) be the angle between the reflected ray and the line that is perpendicular to the wall and that runs through the axis of the mirror. We assume that \(\phi\) is uniformly distributed between \(-\pi/2\) and \(\pi/2\). Let \(X\) represent the distance between the point on the wall that is hit by the reflected ray and the point on the wall that is closest to the axis of the mirror. We now determine the density of \(X\).
Let \(B\) be a fixed positive quantity. Then \(X \ge B\) if and only if \(\tan(\phi) \ge B\), which happens if and only if \(\phi \ge \arctan(B)\). This happens with probability \[\frac{\pi/2 - \arctan(B)}{\pi}\ .\] Thus, for positive \(B\), the cumulative distribution function of \(X\) is \[F(B) = 1 - \frac{\pi/2 - \arctan(B)}{\pi}\ .\] Therefore, the density function for positive \(B\) is \[f(B) = \frac{1}{\pi (1 + B^2)}\ .\] Since the physical situation is symmetric with respect to \(\phi = 0\), it is easy to see that the above expression for the density is correct for negative values of \(B\) as well.
The Law of Large Numbers, which we will discuss in Chapter 8, states that in many cases, if we take the average of independent values of a random variable, then the average approaches a specific number as the number of values increases. It turns out that if one does this with a Cauchy-distributed random variable, the average does not approach any specific number.
Exercises
Exercise \(\PageIndex{1}\)
Choose a number \(U\) from the unit interval \([0,1]\) with uniform distribution. Find the cumulative distribution and density for the random variables
- \(Y = U + 2\).
- \(Y = U^3\).
Exercise \(\PageIndex{2}\)
Choose a number \(U\) from the interval \([0,1]\) with uniform distribution. Find the cumulative distribution and density for the random variables
- \(Y = 1/(U + 1)\).
- \(Y = \log(U + 1)\).
Exercise \(\PageIndex{3}\)
Use Corollary \(\PageIndex{2}\) to derive the expression for the random variable given in Equation [eq 5.9]. : The random variables \(1 - rnd\) and \(rnd\) are identically distributed.
Exercise \(\PageIndex{4}\)
Suppose we know a random variable \(Y\) as a function of the uniform random variable \(U\): \(Y = \phi(U)\), and suppose we have calculated the cumulative distribution function \(F_Y(y)\) and thence the density \(f_Y(y)\). How can we check whether our answer is correct? An easy simulation provides the answer: Make a bar graph of \(Y = \phi(\mbox{\)rnd\(})\) and compare the result with the graph of \(f_Y(y)\). These graphs should look similar. Check your answers to Exercises 5.2.1 and 5.2.2 by this method.
Exercise \(\PageIndex{5}\)
Choose a number \(U\) from the interval \([0,1]\) with uniform distribution. Find the cumulative distribution and density for the random variables
- \(Y = |U - 1/2|\).
- \(Y = (U - 1/2)^2\).
Exercise \(\PageIndex{6}\)
Check your results for Exercise \(\PageIndex{5}\) by simulation as described in Exercise \(\PageIndex{4}\).
Exercise \(\PageIndex{7}\)
Explain how you can generate a random variable whose cumulative distribution function is \[F(x) = \left \{ \begin{array}{ll} 0, & \mbox{if $x < 0$}, \\ x^2, & \mbox{if $0 \leq x \leq 1$}, \\ 1, & \mbox{if $x > 1.$} \end{array} \right.\]
Exercise \(\PageIndex{8}\)
Write a program to generate a sample of 1000 random outcomes each of which is chosen from the distribution given in \(\PageIndex{7}\) Plot a bar graph of your results and compare this empirical density with the density for the cumulative distribution given in Exercise \(\PageIndex{7}\)
Exercise \(\PageIndex{9}\)
Let \(U\), \(V\) be random numbers chosen independently from the interval \([0,1]\) with uniform distribution. Find the cumulative distribution and density of each of the variables
- \(Y = U + V\).
- \(Y = |U - V|\).
Exercise \(PageIndex{10}\)
Let \(U\), \(V\) be random numbers chosen independently from the interval \([0,1]\). Find the cumulative distribution and density for the random variables
- \(Y = \max(U,V)\).
- \(Y = \min(U,V)\).
Exercise \(\PageIndex{11}\)
Write a program to simulate the random variables of Exercises \(\PageIndex{9}\) and \(\PageIndex{10}\) and plot a bar graph of the results. Compare the resulting empirical density with the density found in Exercises \(\PageIndex{9}\) and \(\PageIndex{10}\).
Exercise \(\PageIndex{12}\)
A number \(U\) is chosen at random in the interval \([0,1]\). Find the probability that
- \(R = U^2 < 1/4\).
- \(S = U(1 - U) < 1/4\).
- \(T = U/(1 - U) < 1/4\).
Exercise \(PageIndex{13}\)
Find the cumulative distribution function \(F\) and the density function \(f\) for each of the random variables \(R\), \(S\), and \(T\) in Exercise \(\PageIndex{12}\).
Exercise \(\PageIndex{14}\)
A point \(P\) in the unit square has coordinates \(X\) and \(Y\) chosen at random in the interval \([0,1]\). Let \(D\) be the distance from \(P\) to the nearest edge of the square, and \(E\) the distance to the nearest corner. What is the probability that
- \(D < 1/4\)?
- \(E < 1/4\)?
Exercise \(\PageIndex{15}\)
In Exercise \(\PageIndex{14}\) find the cumulative distribution \(F\) and density \(f\) for the random variable \(D\).
Exercise \(\PageIndex{16}\)
Let \(X\) be a random variable with density function \[f_X(x) = \left \{ \begin{array}{ll} cx(1 - x), & \mbox{if $0 < x < 1$}, \\ 0, & \mbox{otherwise.} \end{array} \right.\]
- What is the value of \(c\)?
- What is the cumulative distribution function \(F_X\) for \(X\)?
- What is the probability that \(X < 1/4\)?
Exercise \(\PageIndex{17}\)
Let \(X\) be a random variable with cumulative distribution function \[F(x) = \left \{ \begin{array}{ll} 0, & \mbox{if $x < 0$}, \\ \sin^2(\pi x/2), & \mbox{if $0 \leq x \leq 1$}, \\ 1, & \mbox{if $1 < x$}. \end{array} \right.\]
- What is the density function \(f_X\) for \(X\)?
- What is the probability that \(X < 1/4\)?
Exercise \(PageIndex{18}\)
Let \(X\) be a random variable with cumulative distribution function \(F_X\), and let \(Y = X + b\), \(Z = aX\), and \(W = aX + b\), where \(a\) and \(b\) are any constants. Find the cumulative distribution functions \(F_Y\), \(F_Z\), and \(F_W\). : The cases \(a > 0\), \(a = 0\), and \(a < 0\) require different arguments.
Exercise \(\PageIndex{19}\)
Let \(X\) be a random variable with density function \(f_X\), and let \(Y = X + b\), \(Z = aX\), and \(W = aX + b\), where \(a \ne 0\). Find the density functions \(f_Y\), \(f_Z\), and \(f_W\). (See Exercise \(\PageIndex{18}\).)
Exercise \(\PageIndex{20}\)
Let \(X\) be a random variable uniformly distributed over \([c,d]\), and let \(Y = aX + b\). For what choice of \(a\) and \(b\) is \(Y\) uniformly distributed over \([0,1]\)?
Exercise \(PageIndex{21}\)
Let \(X\) be a random variable with cumulative distribution function \(F\) strictly increasing on the range of \(X\). Let \(Y = F(X)\). Show that \(Y\) is uniformly distributed in the interval \([0,1]\). (The formula \(X = F^{-1}(Y)\) then tells us how to construct \(X\) from a uniform random variable \(Y\).)
Exercise \(\PageIndex{22}\)
Let \(X\) be a random variable with cumulative distribution function \(F\). The of \(X\) is the value \(m\) for which \(F(m) = 1/2\). Then \(X < m\) with probability 1/2 and \(X > m\) with probability 1/2. Find \(m\) if \(X\) is
- uniformly distributed over the interval \([a,b]\).
- normally distributed with parameters \(\mu\) and \(\sigma\).
- exponentially distributed with parameter \(\lambda\).
Exercise \(PageIndex{23}\)
Let \(X\) be a random variable with density function \(f_X\). The mean of \(X\) is the value \(\mu = \int xf_x(x)\,dx\). Then \(\mu\) gives an average value for \(X\) (see Section 6.3). Find \(\mu\) if \(X\) is distributed uniformly, normally, or exponentially, as in Exercise \(\PageIndex{22}\)
Exercise \(\PageIndex{24}\)
Let \(X\) be a random variable with density function \(f_X\). The of \(X\) is the value \(M\) for which \(f(M)\) is maximum. Then values of \(X\) near \(M\) are most likely to occur. Find \(M\) if \(X\) is distributed normally or exponentially, as in Exercise \(\PageIndex{22}\) What happens if \(X\) is distributed uniformly?
Exercise \(\PageIndex{25}\)
Let \(X\) be a random variable normally distributed with parameters \(\mu = 70\), \(\sigma = 10\). Estimate
- \(P(X > 50)\).
- \(P(X < 60)\).
- \(P(X > 90)\).
- \(P(60 < X < 80)\).
Exercise \(\PageIndex{26}\)
Bridies’ Bearing Works manufactures bearing shafts whose diameters are normally distributed with parameters \(\mu = 1\), \(\sigma = .002\). The buyer’s specifications require these diameters to be \(1.000 \pm .003\) cm. What fraction of the manufacturer’s shafts are likely to be rejected? If the manufacturer improves her quality control, she can reduce the value of \(\sigma\). What value of \(\sigma\) will ensure that no more than 1 percent of her shafts are likely to be rejected?
Exercise \(\PageIndex{27}\)
A final examination at Podunk University is constructed so that the test scores are approximately normally distributed, with parameters \(\mu\) and \(\sigma\). The instructor assigns letter grades to the test scores as shown in Table \(\PageIndex{3}\) (this is the process of “grading on the curve").
| Test Score | Letter grade |
|---|---|
| \(\mu + \sigma < x\) | A |
| \(\mu < x < \mu + \sigma\) | B |
| \(\mu - \sigma < x < \mu\) | C |
| \(\mu - 2\sigma < x < \mu - \sigma\) | D |
| \(x < \mu - 2\sigma\) | F |
What fraction of the class gets A, B, C, D, F?
Exercise \(\PageIndex{28}\)
(Ross11) An expert witness in a paternity suit testifies that the length (in days) of a pregnancy, from conception to delivery, is approximately normally distributed, with parameters \(\mu = 270\), \(\sigma = 10\). The defendant in the suit is able to prove that he was out of the country during the period from 290 to 240 days before the birth of the child. What is the probability that the defendant was in the country when the child was conceived?
Exercise \(\PageIndex{29}\)
Suppose that the time (in hours) required to repair a car is an exponentially distributed random variable with parameter \(\lambda = 1/2\). What is the probability that the repair time exceeds 4 hours? If it exceeds 4 hours what is the probability that it exceeds 8 hours?
Exercise \(\PageIndex{30}\)
Suppose that the number of years a car will run is exponentially distributed with parameter \(\mu = 1/4\). If Prosser buys a used car today, what is the probability that it will still run after 4 years?
Exercise \(\PageIndex{31}\)
Let \(U\) be a uniformly distributed random variable on \([0,1]\). What is the probability that the equation \[x^2 + 4Ux + 1 = 0\] has two distinct real roots \(x_1\) and \(x_2\)?
Exercise \(\PageIndex{32}\)
Write a program to simulate the random variables whose densities are given by the following, making a suitable bar graph of each and comparing the exact density with the bar graph.
- \(f_X(x) = e^{-x}\ \ \mbox{on}\,\, [0,\infty)\,\, (\mbox{but\,\,just\,\,do\,\,it\,\,on\,\,} [0,10]).\)
- \(f_X(x) = 2x\ \ \mbox{on}\,\, [0,1].\)
- \(f_X(x) = 3x^2\ \ \mbox{on}\,\, [0,1].\)
- \(f_X(x) = 4|x - 1/2|\ \ \mbox{on}\,\, [0,1].\)
Exercise \(\PageIndex{33}\)
Suppose we are observing a process such that the time between occurrences is exponentially distributed with \(\lambda = 1/30\) (i.e., the average time between occurrences is 30 minutes). Suppose that the process starts at a certain time and we start observing the process 3 hours later. Write a program to simulate this process. Let \(T\) denote the length of time that we have to wait, after we start our observation, for an occurrence. Have your program keep track of \(T\). What is an estimate for the average value of \(T\)?
Exercise \(\PageIndex{34}\)
Jones puts in two new lightbulbs: a 60 watt bulb and a 100 watt bulb. It is claimed that the lifetime of the 60 watt bulb has an exponential density with average lifetime 200 hours (\(\lambda = 1/200\)). The 100 watt bulb also has an exponential density but with average lifetime of only 100 hours (\(\lambda = 1/100\)). Jones wonders what is the probability that the 100 watt bulb will outlast the 60 watt bulb.
If \(X\) and \(Y\) are two independent random variables with exponential densities \(f(x) = \lambda e^{-\lambda x}\) and \(g(x) = \mu e^{-\mu x}\), respectively, then the probability that \(X\) is less than \(Y\) is given by \[P(X < Y) = \int_0^\infty f(x)(1 - G(x))\,dx,\] where \(G(x)\) is the cumulative distribution function for \(g(x)\). Explain why this is the case. Use this to show that \[P(X < Y) = \frac \lambda{\lambda + \mu}\] and to answer Jones’s question.
Exercise \(\PageIndex{35}\)
Consider the simple queueing process of Example \(\PageIndex{1}\). Suppose that you watch the size of the queue. If there are \(j\) people in the queue the next time the queue size changes it will either decrease to \(j - 1\) or increase to \(j + 1\). Use the result of Exercise \(\PageIndex{34}\) to show that the probability that the queue size decreases to \(j - 1\) is \(\mu/(\mu + \lambda)\) and the probability that it increases to \(j + 1\) is \(\lambda/(\mu + \lambda)\). When the queue size is 0 it can only increase to 1. Write a program to simulate the queue size. Use this simulation to help formulate a conjecture containing conditions on \(\mu\) and \(\lambda\) that will ensure that the queue will have times when it is empty.
Exercise \(\PageIndex{36}\)
Let \(X\) be a random variable having an exponential density with parameter \(\lambda\). Find the density for the random variable \(Y = rX\), where \(r\) is a positive real number.
Exercise \(\PageIndex{37}\)
Let \(X\) be a random variable having a normal density and consider the random variable \(Y = e^X\). Then \(Y\) has a log normal density. Find this density of \(Y\).
Exercise \(\PageIndex{38}\)
Let \(X_1\) and \(X_2\) be independent random variables and for \(i = 1, 2\), let \(Y_i = \phi_i(X_i)\), where \(\phi_i\) is strictly increasing on the range of \(X_i\). Show that \(Y_1\) and \(Y_2\) are independent. Note that the same result is true without the assumption that the \(\phi_i\)’s are strictly increasing, but the proof is more difficult.