
1.9: Case Study- Gender Discrimination (Special Topic)
- Page ID
- 303

Exercise \(\PageIndex{1}\)
Suppose your professor splits the students in class into two groups: students on the left and students on the right. If \(\hat {p}_L\)and \(\hat {p}_R\) represent the proportion of students who own an Apple product on the left and right, respectively, would you be surprised if \(\hat {p}_L\) did not exactly equal \(\hat {p}_R\)?
While the proportions would probably be close to each other, it would be unusual for them to be exactly the same. We would probably observe a small difference due to chance.
Solution
Answers will vary. The side-by-side box plots are especially useful for comparing centers and spreads, while the hollow histograms are more useful for seeing distribution shape, skew, and groups of anomalies.
Exercise \(\PageIndex{2}\)
If we don't think the side of the room a person sits on in class is related to whether the person owns an Apple product, what assumption are we making about the relationship between these two variables?
Solution
We would be assuming that these two variables are independent.
Variability Within Data
We consider a study investigating gender discrimination in the 1970s, which is set in the context of personnel decisions within a bank (Rosen B and Jerdee T. 1974. Inuence of sex role stereotypes on personnel decisions. Journal of Applied Psychology 59(1):9-14). The research question we hope to answer is, "Are females unfairly discriminated against in promotion decisions made by male managers?"
The participants in this study are 48 male bank supervisors attending a management institute at the University of North Carolina in 1972. They were asked to assume the role of the personnel director of a bank and were given a personnel le to judge whether the person should be promoted to a branch manager position. The les given to the participants were identical, except that half of them indicated the candidate was male and the other half indicated the candidate was female. These les were randomly assigned to the subjects.
Exercise \(\PageIndex{3}\)
Is this an observational study or an experiment? What implications does the study type have on what can be inferred from the results?
Solution
The study is an experiment, as subjects were randomly assigned a male le or a female le. Since this is an experiment, the results can be used to evaluate a causal relationship between gender of a candidate and the promotion decision.
For each supervisor we record the gender associated with the assigned file and the promotion decision. Using the results of the study summarized in Table 1.44, we would like to evaluate if females are unfairly discriminated against in promotion decisions. In this study, a smaller proportion of females are promoted than males (0.583 versus 0.875), but it is unclear whether the difference provides convincing evidence that females are unfairly discriminated against.
|
decision |
|||
|---|---|---|---|
| promoted | not promoted |
Total |
|
| male | 21 | 3 |
24 |
| female | 14 | 10 | 24 |
| Total | 35 | 13 |
48 |
Example \(\PageIndex{1}\)
Statisticians are sometimes called upon to evaluate the strength of evidence. When looking at the rates of promotion for males and females in this study, what comes to mind as we try to determine whether the data show convincing evidence of a real difference?
Solution
The observed promotion rates (58.3% for females versus 87.5% for males) suggest there might be discrimination against women in promotion decisions. However, we cannot be sure if the observed difference represents discrimination or is just from random chance. Generally there is a little bit of fluctuation in sample data, and we wouldn't expect the sample proportions to be exactly equal, even if the truth was that the promotion decisions were independent of gender.
Example 1.49 is a reminder that the observed outcomes in the sample may not perfectly reflect the true relationships between variables in the underlying population. Table 1.44 shows there were 7 fewer promotions in the female group than in the male group, a difference in promotion rates of 29.2% \( ( \frac {21}{24} - \frac {14}{24} = 0.292 )\). This difference is large, but the sample size for the study is small, making it unclear if this observed difference represents discrimination or whether it is simply due to chance. We label these two competing claims, H0 and HA:
- H0: Independence model. The variables gender and decision are independent. They have no relationship, and the observed difference between the proportion of males and females who were promoted, 29.2%, was due to chance.
- HA: Alternative model. The variables gender and decision are not independent. The difference in promotion rates of 29.2% was not due to chance, and equally qualified females are less likely to be promoted than males.
What would it mean if the independence model, which says the variables gender and decision are unrelated, is true? It would mean each banker was going to decide whether to promote the candidate without regard to the gender indicated on the le. That is, the difference in the promotion percentages was due to the way the les were randomly divided to the bankers, and the randomization just happened to give rise to a relatively large difference of 29.2%.
Consider the alternative model: bankers were influenced by which gender was listed on the personnel le. If this was true, and especially if this inuence was substantial, we would expect to see some difference in the promotion rates of male and female candidates. If this gender bias was against females, we would expect a smaller fraction of promotion decisions for female personnel les relative to the male files.
We choose between these two competing claims by assessing if the data conflict so much with H0 that the independence model cannot be deemed reasonable. If this is the case, and the data support HA, then we will reject the notion of independence and conclude there was discrimination.
Simulating the Study
Table 1.44 shows that 35 bank supervisors recommended promotion and 13 did not. Now, suppose the banker's decisions were independent of gender. Then, if we conducted the experiment again with a different random arrangement of les, differences in promotion rates would be based only on random uctuation. We can actually perform this randomization, which simulates what would have happened if the bankers decisions had been independent of gender but we had distributed the les differently.
In this simulation, we thoroughly shuffle 48 personnel files, 24 labeled male sim and 24 labeled female sim, and deal these les into two stacks. We will deal 35 les into the first stack, which will represent the 35 supervisors who recommended promotion. The second stack will have 13 les, and it will represent the 13 supervisors who recommended against promotion. Then, as we did with the original data, we tabulate the results and determine the fraction of male sim and female sim who were promoted. The randomization of files in this simulation is independent of the promotion decisions, which means any difference in the two fractions is entirely due to chance. Table 1.45 show the results of such a simulation.
|
decision |
|||
|---|---|---|---|
| promoted | not promoted |
Total |
|
| male_sim | 18 | 6 | 24 |
| female_sim | 17 | 7 | 24 |
| Total | 35 | 13 | 48 |
Exercise \(\PageIndex{1}\)
Exercise 1.50 What is the difference in promotion rates between the two simulated groups in Table 1.45? How does this compare to the observed 29.2% in the actual groups?50
Checking for Independence
We computed one possible difference under the independence model in Exercise 1.50, which represents one difference due to chance. While in this first simulation, we physically dealt out les, it is more efficient to perform this simulation using a computer. Repeating the simulation on a computer, we get another difference due to chance: -0.042. And another: 0.208. And so on until we repeat the simulation enough times that we have a good idea of what represents the distribution of differences from chance alone. Figure 1.46 shows a plot of the differences found from 100 simulations, where each dot represents a simulated difference between the proportions of male and female les that were recommended for promotion.
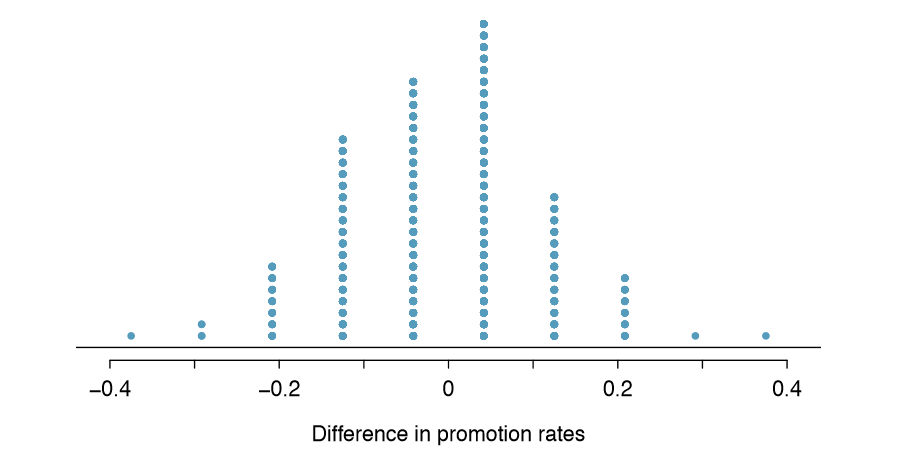
Note that the distribution of these simulated differences is centered around 0. We simulated these differences assuming that the independence model was true, and under this condition, we expect the difference to be zero with some random uctation. We would generally be surprised to see a difference of exactly 0: sometimes, just by chance, the difference is higher than 0, and other times it is lower than zero.
Example \(\PageIndex{1}\)
How often would you observe a difference of at least 29.2% (0.292) according to Figure 1.46? Often, sometimes, rarely, or never?
Solution
It appears that a difference of at least 29.2% due to chance alone would only happen about 2% of the time according to Figure 1.46. Such a low probability indicates a rare event.
The difference of 29.2% being a rare event suggests two possible interpretations of the results of the study:
- H0 Independence model. Gender has no effect on promotion decision, and we observed a difference that would only happen rarely.
- HA Alternative model. Gender has an effect on promotion decision, and what we observed was actually due to equally quali ed women being discriminated against in promotion decisions, which explains the large difference of 29.2%.
Based on the simulations, we have two options. (1) We conclude that the study results do not provide strong evidence against the independence model. That is, we do not have sufficiently strong evidence to conclude there was gender discrimination. (2) We conclude the evidence is sufficiently strong to reject H0 and assert that there was gender discrimination. When we conduct formal studies, usually we reject the notion that we just happened to observe a rare event.51 So in this case, we reject the independence model in favor of the alternative. That is, we are concluding the data provide strong evidence of gender discrimination against women by the supervisors.
One field of statistics, statistical inference, is built on evaluating whether such differences are due to chance. In statistical inference, statisticians evaluate which model is most reasonable given the data. Errors do occur, just like rare events, and we might choose the wrong model. While we do not always choose correctly, statistical inference gives us tools to control and evaluate how often these errors occur. In Chapter 4, we give a formal introduction to the problem of model selection. We spend the next two chapters building a foundation of probability and theory necessary to make that discussion rigorous.
51This reasoning does not generally extend to anecdotal observations. Each of us observes incredibly rare events every day, events we could not possibly hope to predict. However, in the non-rigorous setting of anecdotal evidence, almost anything may appear to be a rare event, so the idea of looking for rare events in day-to-day activities is treacherous. For example, we might look at the lottery: there was only a 1 in 176 million chance that the Mega Millions numbers for the largest jackpot in history (March 30, 2012) would be (2, 4, 23, 38, 46) with a Mega ball of (23), but nonetheless those numbers came up! However, no matter what numbers had turned up, they would have had the same incredibly rare odds. That is, any set of numbers we could have observed would ultimately be incredibly rare. This type of situation is typical of our daily lives: each possible event in itself seems incredibly rare, but if we consider every alternative, those outcomes are also incredibly rare. We should be cautious not to misinterpret such anecdotal evidence.