
5.2: The Standard Normal Distribution
- Page ID
- 525
- To learn what a standard normal random variable is.
- To learn how to compute probabilities related to a standard normal random variable.
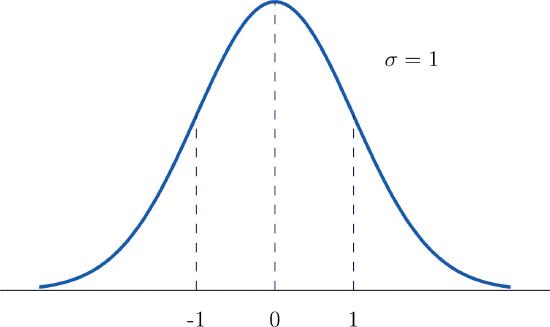
A standard normal random variable is a normally distributed random variable with mean \(\mu =0\) and standard deviation \(\sigma =1\). It will always be denoted by the letter \(Z\).
The density function for a standard normal random variable is shown in Figure \(\PageIndex{1}\).
To compute probabilities for \(Z\) we will not work with its density function directly but instead read probabilities out of Figure \(\PageIndex{2}\). The tables are tables of cumulative probabilities; their entries are probabilities of the form \(P(Z< z)\). The use of the tables will be explained by the following series of examples.
Find the probabilities indicated, where as always \(Z\) denotes a standard normal random variable.
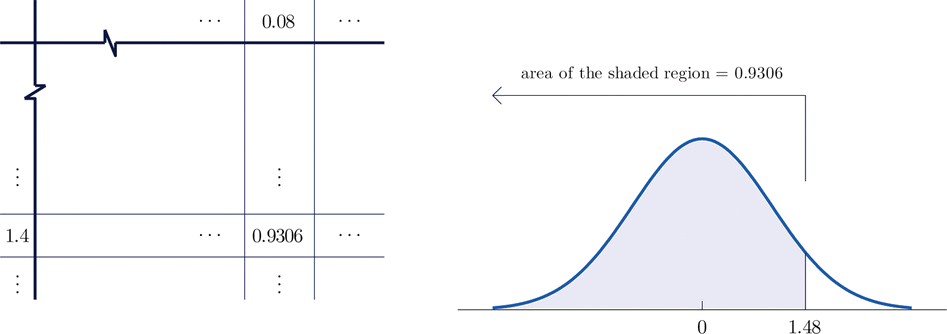
- \(P(Z< 1.48)\).
- \(P(Z< -0.25)\).
Solution
- Figure \(\PageIndex{3}\) shows how this probability is read directly from the table without any computation required. The digits in the ones and tenths places of \(1.48\), namely \(1.4\), are used to select the appropriate row of the table; the hundredths part of \(1.48\), namely \(0.08\), is used to select the appropriate column of the table. The four decimal place number in the interior of the table that lies in the intersection of the row and column selected, \(0.9306\), is the probability sought:
\[P(Z< 1.48)=0.9306 \nonumber \]
- The minus sign in \(-0.25\) makes no difference in the procedure; the table is used in exactly the same way as in part (a): the probability sought is the number that is in the intersection of the row with heading \(-0.2\) and the column with heading \(0.05\), the number \(0.4013\). Thus \(P(Z< -0.25)=0.4013\).
Find the probabilities indicated.
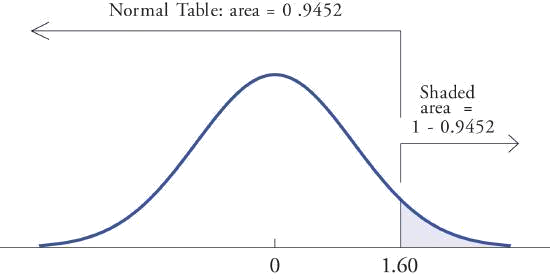
- \(P(Z> 1.60)\).
- \(P(Z> -1.02)\).
Solution
- Because the events \(Z> 1.60\) and \(Z\leq 1.60\) are complements, the Probability Rule for Complements implies that \[P(Z> 1.60)=1-P(Z\leq 1.60) \nonumber \] Since inclusion of the endpoint makes no difference for the continuous random variable \(Z\), \(P(Z\leq 1.60)=P(Z< 1.60)\), which we know how to find from the table in Figure \(\PageIndex{2}\). The number in the row with heading \(1.6\) and in the column with heading \(0.00\) is \(0.9452\). Thus \(P(Z< 1.60)=0.9452\) so \[P(Z> 1.60)=1-P(Z\leq 1.60)=1-0.9452=0.0548 \nonumber \] Figure \(\PageIndex{4}\) illustrates the ideas geometrically. Since the total area under the curve is \(1\) and the area of the region to the left of \(1.60\) is (from the table) \(0.9452\), the area of the region to the right of \(1.60\) must be \(1-0.9452=0.0548\).
- The minus sign in \(-1.02\) makes no difference in the procedure; the table is used in exactly the same way as in part (a). The number in the intersection of the row with heading \(-1.0\) and the column with heading \(0.02\) is \(0.1539\). This means that \(P(Z<-1.02)=P(Z\leq -1.02)=0.1539\). Hence \[P(Z>-1.02)=P(Z\leq -1.02)=1-0.1539=0.8461 \nonumber \]
Find the probabilities indicated.
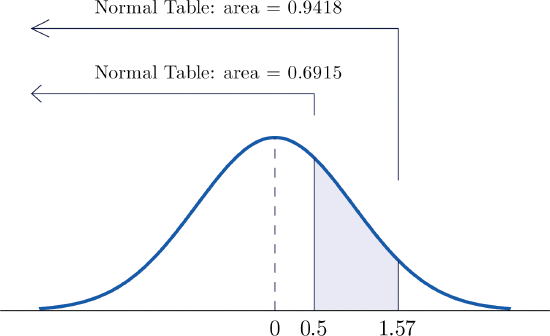
- \(P(0.5<Z<1.57)\).
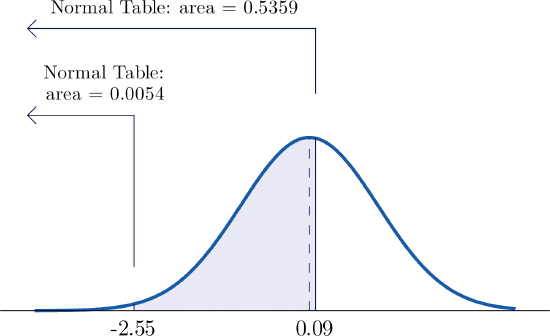
- \(P(-2.55<Z<0.09)\).
Solution
- Figure \(\PageIndex{5}\) illustrates the ideas involved for intervals of this type. First look up the areas in the table that correspond to the numbers \(0.5\) (which we think of as \(0.50\) to use the table) and \(1.57\). We obtain \(0.6915\) and \(0.9418\), respectively. From the figure it is apparent that we must take the difference of these two numbers to obtain the probability desired. In symbols, \[P(0.5<Z<1.57)=P(Z<1.57)-P(Z<0.50)=0.9418-0.6915=0.2503 \nonumber \]
- The procedure for finding the probability that \(Z\) takes a value in a finite interval whose endpoints have opposite signs is exactly the same procedure used in part (a), and is illustrated in Figure \(\PageIndex{6}\) "Computing a Probability for an Interval of Finite Length". In symbols the computation is \[P(-2.55<Z<0.09)=P(Z<0.09)-P(Z<-2.55)=0.5359-0.0054=0.5305 \nonumber \]
The next example shows what to do if the value of \(Z\) that we want to look up in the table is not present there.
Find the probabilities indicated.
- \(P(1.13<Z<4.16)\).
- \(P(-5.22<Z<2.15)\).
Solution
- We attempt to compute the probability exactly as in Example \(\PageIndex{3}\) by looking up the numbers \(1.13\) and \(4.16\) in the table. We obtain the value \(0.8708\) for the area of the region under the density curve to left of \(1.13\) without any problem, but when we go to look up the number \(4.16\) in the table, it is not there. We can see from the last row of numbers in the table that the area to the left of \(4.16\) must be so close to 1 that to four decimal places it rounds to \(1.0000\). Therefore \[P(1.13<Z<4.16)=1.0000-0.8708=0.1292 \nonumber \]
- Similarly, here we can read directly from the table that the area under the density curve and to the left of \(2.15\) is \(0.9842\), but \(-5.22\) is too far to the left on the number line to be in the table. We can see from the first line of the table that the area to the left of \(-5.22\) must be so close to \(0\) that to four decimal places it rounds to \(0.0000\). Therefore \[P(-5.22<Z<2.15)=0.9842-0.0000=0.9842 \nonumber \]
The final example of this section explains the origin of the proportions given in the Empirical Rule.
Find the probabilities indicated.
- \(P(-1<Z<1)\).
- \(P(-2<Z<2)\).
- \(P(-3<Z<3)\).
Solution
- Using the table as was done in Example \(\PageIndex{3}\) we obtain \[P(-1<Z<1)=0.8413-0.1587=0.6826 \nonumber \] Since \(Z\) has mean \(0\) and standard deviation \(1\), for \(Z\) to take a value between \(-1\) and \(1\) means that \(Z\) takes a value that is within one standard deviation of the mean. Our computation shows that the probability that this happens is about \(0.68\), the proportion given by the Empirical Rule for histograms that are mound shaped and symmetrical, like the bell curve.
- Using the table in the same way, \[P(-2<Z<2)=0.9772-0.0228=0.9544 \nonumber \] This corresponds to the proportion 0.95 for data within two standard deviations of the mean.
- Similarly, \[P(-3<Z<3)=0.9987-0.0013=0.9974 \nonumber \] which corresponds to the proportion 0.997 for data within three standard deviations of the mean.
Key takeaway
- A standard normal random variable \(Z\) is a normally distributed random variable with mean \(\mu =0\) and standard deviation \(\sigma =1\).
- Probabilities for a standard normal random variable are computed using Figure \(\PageIndex{2}\).