
5.E: Exercises
- Page ID
- 15491

5.1: Introduction
5.2: Continuous Probability Functions
Which type of distribution does the graph illustrate?
Which type of distribution does the graph illustrate?
Which type of distribution does the graph illustrate?
What does the shaded area represent? P(___< x < ___)
What does the shaded area represent? P(___< x < ___)
For a continuous probability distribution, 0 ≤ x ≤ 15. What is P(x > 15)?
What is the area under f(x) if the function is a continuous probability density function?
For a continuous probability distribution, 0 ≤ x ≤ 10. What is P(x = 7)?
A continuous probability function is restricted to the portion between x = 0 and 7. What is P(x = 10)?
f(x) for a continuous probability function is 15
, and the function is restricted to 0 ≤ x ≤ 5. What is P(x < 0)?
f(x), a continuous probability function, is equal to 112
, and the function is restricted to 0 ≤ x ≤ 12. What is P (0 < x < 12)?
one
Find the probability that x falls in the shaded area.

Find the probability that x falls in the shaded area.
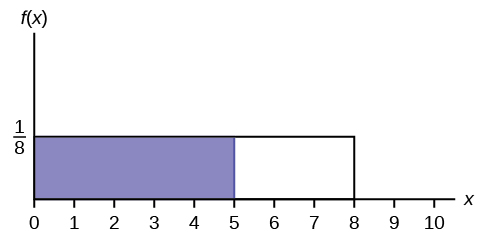
Find the probability that x falls in the shaded area.

f(x), a continuous probability function, is equal to 13
and the function is restricted to 1 ≤ x ≤ 4. Describe P(x>32).
The probability is equal to the area from x = 32to x = 4 above the x-axis and up to f(x) = 13
Homework
For each probability and percentile problem, draw the picture.
Consider the following experiment. You are one of 100 people enlisted to take part in a study to determine the percent of nurses in America with an R.N. (registered nurse) degree. You ask nurses if they have an R.N. degree. The nurses answer “yes” or “no.” You then calculate the percentage of nurses with an R.N. degree. You give that percentage to your supervisor.
- What part of the experiment will yield discrete data?
- What part of the experiment will yield continuous data?
When age is rounded to the nearest year, do the data stay continuous, or do they become discrete? Why?
Age is a measurement, regardless of the accuracy used.