
9.4: A Single Population Mean using the Student t-Distribution
- Page ID
- 27261

All hypotheses tests have the same basic steps:
- Determine the hypothesis: What are we trying to figure out? This is formally written as the null and alternative hypotheses.
- The alternative hypothesis, \(H_{a}\), never has a symbol that contains an equal sign.
- The alternative hypothesis, \(H_{a}\), tells you if the test is left, right, or two-tailed. It is the key to conducting the appropriate test.
- Calculate the evidence: This will be a test statistics and either a critical value or a p-value.
- In a hypothesis test problem, you may see words such as "the level of significance is 1%." The "1%" is the preconceived or preset \(\alpha\). The statistician setting up the hypothesis test selects the value of α to use before collecting the sample data. If no level of significance is given, a common standard to use is \(\alpha = 0.05\).
- When you calculate the \(p\)-value and draw the picture, the \(p\)-value is the area in the left tail, the right tail, or split evenly between the two tails. For this reason, we call the hypothesis test left, right, or two tailed.
- Make a decision: The options will be Reject the Null Hypothesis or Do not Reject the Null Hypothesis.
- Never, ever, Accept the Null Hypothesis.
- Thinking about the meaning of the \(p\)-value: A data analyst (and anyone else) should have more confidence that he made the correct decision to reject the null hypothesis with a smaller \(p\)-value (for example, 0.001 as opposed to 0.04) even if using the 0.05 level for alpha. Similarly, for a large p-value such as 0.4, as opposed to a \(p\)-value of 0.056 (\(\alpha = 0.05\) is less than either number), a data analyst should have more confidence that she made the correct decision in not rejecting the null hypothesis. This makes the data analyst use judgment rather than mindlessly applying rules.
- Determine the conclusion: What does the decision mean in terms of the problem given?
Using the t-Distribution
Just like with confidence intervals, for some hypothesis tests of a mean, we need to use \(z\), the Standard Normal Distribution and for other tests of a mean, we need to the use \(t\)-distribution instead.
Similarly to confidence intervals, use the Student's t distribution if the population standard deviation is not known.
Full Hypothesis Test Examples
Statistics students believe that the mean score on the first statistics test is 65. A statistics instructor thinks the mean score is higher than 65. He samples ten statistics students and obtains the scores 65 65 70 67 66 63 63 68 72 71. He performs a hypothesis test using a 5% level of significance. The data are assumed to be from a normal distribution.
\(P\)-value Solution
Determine the hypothesis:
A 5% level of significance means that \(\alpha = 0.05\). This is a test of a single population mean.
\(H_{0}: \mu = 65\)
\(H_{a}: \mu > 65\) (claim)
Since the instructor thinks the average score is higher, use a "\(>\)" in the alternative hypothesis. The "\(>\)" means the test is right-tailed.
Calculate the evidence:
There is no population standard deviation given in the problem statement. You are only given \(n = 10\) sample data values. Notice also that the data come from a normal distribution. This means that the distribution for the test is a student's \(t\).
Calculate the test statistic using the formula for a \(t\) test.
\[t=\frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}}\nonumber\]
\(\mu=65\) comes from \(H_{0}\) and not the data. Enter the data into Excel, and use the Excel formula \(=\text{AVERAGE}()\) to find \(\bar{x}=67\) and the formula \(=\text{STDEV.S}()\) to find \(s=3.197\).
\[t=\frac{67-65}{\frac{3.197}{\sqrt{10}}}=\frac{2}{\frac{3.197}{3.162}}=\frac{2}{1.011}=1.979\nonumber\]
Now calculate the \(p\)-value based on the test statistic found.
This is a right-tailed test, using the \(t\)-distribution, so use the Excel formula \(=\text{T.DIST.RT}(t,df)\).
In this problem, \(df = n-1 = 10 - 1 = 9\), and we found \(t\), which is the test statistic, to be \(t=1.979\).
Use the Excel formula \(=\text{T.DIST.RT}(1.979,9)=0.0396\).
Interpretation of the p-value: If the null hypothesis is true, then there is a 0.0396 probability (3.96%) that the sample mean is 65 or more.
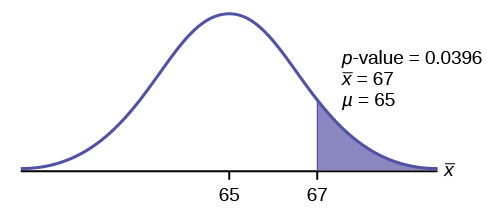
Make a decision:
\(\alpha\) is the minimum area that could be considered to make our result significant.
Compare \(\alpha\) and the \(p-\text{value}\)
- If \(p\)-value is less than the \(\alpha\) then we will Reject \(H_{0}\).
- If \(\alpha\) is less than the \(p\)-value then we will Fail to Reject \(H_{0}\).
Compare \(\alpha = 0.05\) and \(p\text{-value} = 0.0396\).
Since \(p\)-value \(<\alpha\), reject \(H_{0}\)
This means you reject \(\mu = 65\). In other words, you believe the average test score is more than 65.
Conclusion: At a 5% level of significance, the sample data show sufficient evidence that the mean (average) test score is more than 65, just as the math instructor thinks.
Critical Value Solution
Determine the hypothesis (Same as the \(P\)-value solution):
A 5% level of significance means that \(\alpha = 0.05\). This is a test of a single population mean.
\(H_{0}: \mu = 65\)
\(H_{a}: \mu > 65\) (claim)
Since the instructor thinks the average score is higher, use a "\(>\)" in the alternative hypothesis. The "\(>\)" means the test is right-tailed.
Calculate the evidence:
There is no population standard deviation given in the problem statement. You are only given \(n = 10\) sample data values. Notice also that the data come from a normal distribution. This means that the distribution for the test is a student's \(t\).
Calculate the critical value. Since this is right-tailed, using the \(t\)-distribution, use the Excel formula \(=\text{T.INV}(1-\alpha,df)\).
In this problem, \(df = n-1 = 10 - 1 = 9\), and \(\alpha=0.05\).
Use Excel formula \(=\text{T.INV}(1-0.05,9)=1.8331\).
Now calculate the test statistic using the formula for a \(t\) test.
\[t=\frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}}\nonumber\]
\(\mu=65\) comes from \(H_{0}\) and not the data. Enter the data into Excel, and use the Excel formula \(=\text{AVERAGE}()\) to find \(\bar{x}=67\) and the formula \(=\text{STDEV.S}()\) to find \(s=3.197\).
\[t=\frac{67-65}{\frac{3.197}{\sqrt{10}}}=\frac{2}{\frac{3.197}{3.162}}=\frac{2}{1.011}=1.979\nonumber\]
Make a decision:
Graph the critical value and the test statistic along the number line of the Standard Normal Distribution graph.
Since this is right-tailed, everything greater than the critical value, \(\text{CV}=1.8331\) will be the rejection region.
Since the test statistic, \(t=1.979\) is greater than the critical value, \(\text{CV}=1.8331\), the decision will be to Reject the Null Hypothesis.
Conclusion (Same as the \(P\)-value solution): At a 5% level of significance, the sample data show sufficient evidence that the mean (average) test score is more than 65, just as the math instructor thinks.
It is believed that a stock price for a particular company will grow at a rate of $5 per week with a standard deviation of $1. An investor believes the stock won’t grow at that rate. The changes in stock price is recorded for ten weeks and are as follows: $4, $3, $2, $3, $1, $7, $2, $1, $1, $2. Perform a critical value hypothesis test using an 8% level of significance. Identify the Type I and Type II errors.
Answer
Determine the hypothesis:
An 8% level of significance means that \(\alpha = 0.08\). This is a test of a single population mean.
\(H_{0}: \mu = 5\)
\(H_{a}: \mu \neq 5\) (claim)
The "\(\neq\)" in the alternative hypothesis means the test is two-tailed.
Calculate the evidence:
There is no population standard deviation given in the problem statement. You are only given \(n = 10\) sample data values. This means that the distribution for the test is a student's \(t\).
Calculate the critical value. Since this is two-tailed, using the \(t\)-distribution, use the Excel formula \(=\text{T.INV.2T}(\alpha,df)\).
In this problem, \(df = n-1 = 10 - 1 = 9\), and \(\alpha=0.08\).
Use Excel formula \(=\text{T.INV.2T}(0.08,9)=1.9726\).
Since this is a two-tailed test, we will have two critical values, at \(1.9726\) and at \(-1.9726\).
Now calculate the test statistic using the formula for a \(t\) test.
\[t=\frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}}\nonumber\]
\(\mu=5\) comes from \(H_{0}\) and not the data. Enter the data into Excel, and use the Excel formula \(=\text{AVERAGE}()\) to find \(\bar{x}=2.6\) and the formula \(=\text{STDEV.S}()\) to find \(s=1.838\).
\[t=\frac{2.6-5}{\frac{1.838}{\sqrt{10}}}=\frac{-2.4}{\frac{1.838}{3.162}}=\frac{-2.4}{0.581}=-4.129\nonumber\]
Make a decision:
Graph the critical value and the test statistic along the number line of the Standard Normal Distribution graph.
Since this is two-tailed, everything less than the negative critical value, \(\text{CV}=-1.9726\), and everything greater than the positive critical value, \(\text{CV}=1.9726\) will be the rejection region.
Since the test statistic, \(t=-4.129\) is less than the negative critical value, \(\text{CV}=-1.9726\), the decision will be to Reject the Null Hypothesis.
Conclusion:
At an 8% level of significance, the sample data show sufficient evidence that the mean (average) stock growth will not be $5 per week.
Type I and Type II Errors:
Type I Error: To conclude that the stock price is growing slower than $5 a week when, in fact, the stock price is growing at $5 a week (reject the null hypothesis when the null hypothesis is true).
Type II Error: To conclude that the stock price is growing at a rate of $5 a week when, in fact, the stock price is growing slower than $5 a week (do not reject the null hypothesis when the null hypothesis is false).
The National Institute of Standards and Technology provides exact data on conductivity properties of materials. Following are conductivity measurements for 11 randomly selected pieces of a particular type of glass.
1.11; 1.07; 1.11; 1.07; 1.12; 1.08; 0.98; 0.98 1.02; 0.95; 0.95
Is there convincing evidence that the average conductivity of this type of glass is less than one? Use the \(p\)-value method at a significance level of 0.02. Assume the population is normal.
Answer
Determine the hypothesis:
A 0.02 level of significance means that \(\alpha = 0.02\). This is a test of a single population mean.
\(H_{0}: \mu \geq 1\)
\(H_{a}: \mu <1\) (claim)
The "\(<\)" in the alternative hypothesis means the test is left-tailed.
Calculate the evidence:
There is no population standard deviation given in the problem statement. You are only given \(n = 11\) sample data values. Notice also that the data come from a normal distribution. This means that the distribution for the test is a student's \(t\).
Calculate the test statistic using the formula for a \(t\) test.
\[t=\frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}}\nonumber\]
\(\mu=1\) comes from \(H_{0}\) and not the data. Enter the data into Excel, and use the Excel formula \(=\text{AVERAGE}()\) to find \(\bar{x}=1.04\) and the formula \(=\text{STDEV.S}()\) to find \(s=0.0669\).
\[t=\frac{1.04-1}{\frac{0.0669}{\sqrt{11}}}=\frac{0.04}{\frac{0.0669}{3.317}}=\frac{0.04}{0.0199}=2.014\nonumber\]
Now calculate the \(p\)-value based on the test statistic found.
This is a right-tailed test, using the \(t\)-distribution, so use the Excel formula \(=\text{T.DIST}(t,df,\text{true})\).
In this problem, \(df = n-1 = 11 - 1 = 10\), and we found \(t\), which is the test statistic, to be \(t=2.014\).
Use the Excel formula \(=\text{T.DIST}(2.014,10,\text{true})=0.9642\).
Interpretation of the p-value: If the null hypothesis is true, then there is a 0.9642 probability that the sample mean is 1 or more.
Make a decision:
\(\alpha\) is the minimum area that could be considered to make our result significant.
Compare \(\alpha\) and the \(p-\text{value}\)
- If \(p\)-value is less than the \(\alpha\) then we will Reject \(H_{0}\).
- If \(\alpha\) is less than the \(p\)-value then we will Fail to Reject \(H_{0}\).
Compare \(\alpha = 0.02\) and \(p\text{-value} = 0.9642\).
Since \(p\)-value \(>\alpha\), do not reject \(H_{0}\)
This means you reject \(\mu \geq 1\).
Conclusion:
At a 2% level of significance, the sample data do not show sufficient evidence that the mean (average) conductivity of this type of glass is less than 1.
Review
The hypothesis test itself has an established process. This can be summarized as follows:
- Determine \(H_{0}\) and \(H_{a}\). Remember, they are contradictory.
- Determine the random variable.
- Determine the distribution for the test.
- Draw a graph, calculate the test statistic, and use the test statistic to calculate the \(p\text{-value}\). (A z-score and a t-score are examples of test statistics.)
- Compare the preconceived α with the p-value, make a decision (reject or do not reject H0), and write a clear conclusion using English sentences.
Notice that in performing the hypothesis test, you use \(\alpha\) and not \(\beta\). \(\beta\) is needed to help determine the sample size of the data that is used in calculating the \(p\text{-value}\). Remember that the quantity \(1 – \beta\) is called the Power of the Test. A high power is desirable. If the power is too low, statisticians typically increase the sample size while keeping α the same.If the power is low, the null hypothesis might not be rejected when it should be.
References
- Data from Amit Schitai. Director of Instructional Technology and Distance Learning. LBCC.
- Data from Bloomberg Businessweek. Available online at www.businessweek.com/news/2011- 09-15/nyc-smoking-rate-falls-to-record-low-of-14-bloomberg-says.html.
- Data from energy.gov. Available online at http://energy.gov (accessed June 27. 2013).
- Data from Gallup®. Available online at www.gallup.com (accessed June 27, 2013).
- Data from Growing by Degrees by Allen and Seaman.
- Data from La Leche League International. Available online at www.lalecheleague.org/Law/BAFeb01.html.
- Data from the American Automobile Association. Available online at www.aaa.com (accessed June 27, 2013).
- Data from the American Library Association. Available online at www.ala.org (accessed June 27, 2013).
- Data from the Bureau of Labor Statistics. Available online at http://www.bls.gov/oes/current/oes291111.htm.
- Data from the Centers for Disease Control and Prevention. Available online at www.cdc.gov (accessed June 27, 2013)
- Data from the U.S. Census Bureau, available online at quickfacts.census.gov/qfd/states/00000.html (accessed June 27, 2013).
- Data from the United States Census Bureau. Available online at www.census.gov/hhes/socdemo/language/.
- Data from Toastmasters International. Available online at http://toastmasters.org/artisan/deta...eID=429&Page=1.
- Data from Weather Underground. Available online at www.wunderground.com (accessed June 27, 2013).
- Federal Bureau of Investigations. “Uniform Crime Reports and Index of Crime in Daviess in the State of Kentucky enforced by Daviess County from 1985 to 2005.” Available online at http://www.disastercenter.com/kentucky/crime/3868.htm (accessed June 27, 2013).
- “Foothill-De Anza Community College District.” De Anza College, Winter 2006. Available online at research.fhda.edu/factbook/DA...t_da_2006w.pdf.
- Johansen, C., J. Boice, Jr., J. McLaughlin, J. Olsen. “Cellular Telephones and Cancer—a Nationwide Cohort Study in Denmark.” Institute of Cancer Epidemiology and the Danish Cancer Society, 93(3):203-7. Available online at http://www.ncbi.nlm.nih.gov/pubmed/11158188 (accessed June 27, 2013).
- Rape, Abuse & Incest National Network. “How often does sexual assault occur?” RAINN, 2009. Available online at www.rainn.org/get-information...sexual-assault (accessed June 27, 2013).
Glossary
- Central Limit Theorem
- Given a random variable (RV) with known mean \(\mu\) and known standard deviation \(\sigma\). We are sampling with size \(n\) and we are interested in two new RVs - the sample mean, \(\bar{X}\), and the sample sum, \(\sum X\). If the size \(n\) of the sample is sufficiently large, then \(\bar{X} - N\left(\mu, \frac{\sigma}{\sqrt{n}}\right)\) and \(\sum X - N \left(n\mu, \sqrt{n}\sigma\right)\). If the size n of the sample is sufficiently large, then the distribution of the sample means and the distribution of the sample sums will approximate a normal distribution regardless of the shape of the population. The mean of the sample means will equal the population mean and the mean of the sample sums will equal \(n\) times the population mean. The standard deviation of the distribution of the sample means, \(\frac{\sigma}{\sqrt{n}}\), is called the standard error of the mean.
Contributors and Attributions
Barbara Illowsky and Susan Dean (De Anza College) with many other contributing authors. Content produced by OpenStax College is licensed under a Creative Commons Attribution License 4.0 license. Download for free at http://cnx.org/contents/30189442-699...b91b9de@18.114.