3.3.3: Estimating the Regression Model with the Least‐Square Line
- Page ID
- 28707
We now return to the case where we know the data and can see the linear correlation in a scatterplot, but we do not know the values of the parameters of the underlying model. The three parameters that are unknown to us are the \(y\)‐intercept \(\beta_{0}\), the slope (\(\beta_{1}\)) and the standard deviation of the residual error (\(\sigma\)):
Slope parameter: \(b_1\) will be an estimator for \(\beta_{1}\)
Y‐intercept parameter: \(b_0\) will be an estimator for \(\beta_{0}\)
Standard deviation: \(s_e\) will be an estimator for \(\sigma\)
Regression line: \(\hat{Y}=b_{0}+b_{1} X\)
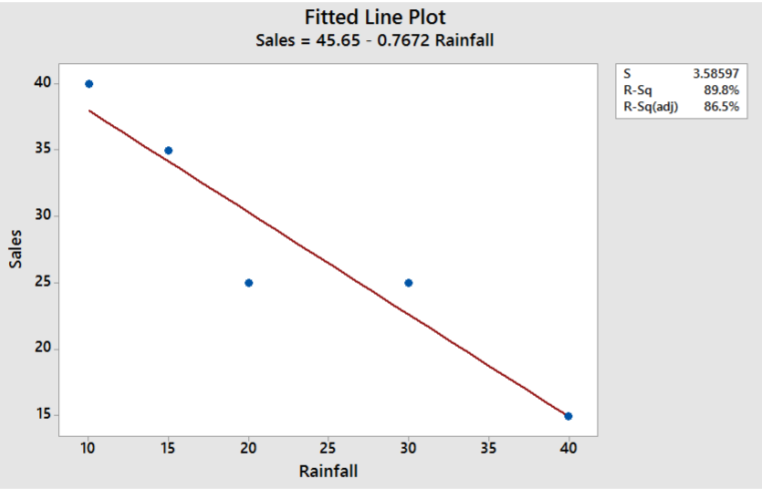
Take the example comparing rainfall to sales of sunglasses in which the scatterplot shows a negative correlation. However, there are many lines we could draw. How do we find the line of best fit?
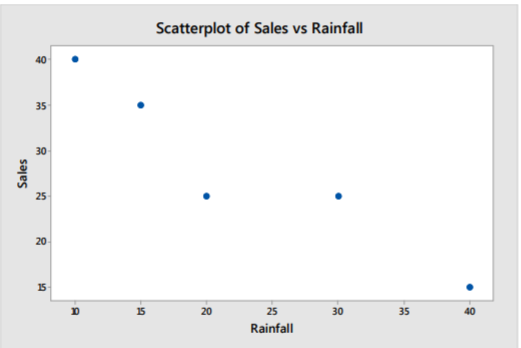
Solution
Minimizing Sum of Squared Residual Errors (SSE)
We are going to define the “best line” as the line that minimizes the Sum of Squared Residual Errors (SSE).
Suppose we try to fit this data with a line that goes through the first and last point. We can then calculate the equation of this line using algebra:
\[\hat{Y}=\dfrac{145}{3}-\dfrac{5}{6} X \approx 48.3-0.833 X \nonumber \]
The SSE for this line is 47.917:
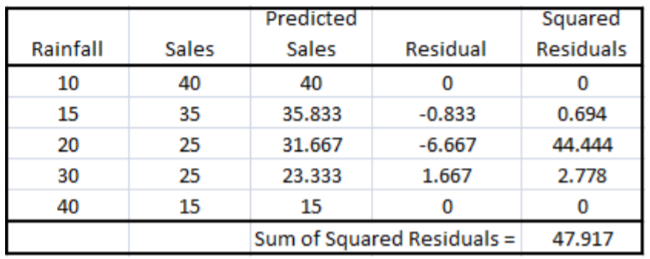
Although this line is a good fit, it is not the best line. The slope(\(b_1\)) and intercept(\(b_o\)) for the line that minimizes SSE is be calculated using the least squares principle formulas:
\(S S X=\Sigma X^{2}-\dfrac{1}{n}(\Sigma X)^{2}\)
\(S S Y=\Sigma Y^{2}-\dfrac{1}{n}(\Sigma Y)^{2}\)
\(S S X Y=\Sigma X Y-\dfrac{1}{n}(\Sigma X \cdot \Sigma y)\)
\(b_{1}=\dfrac{S S X Y}{S S X}\)
\(b_{0}=\bar{Y}-b_{1} \bar{X}\)
In the Rainfall example where \(X\)=Rainfall and \(Y\)=Sales of Sunglasses:
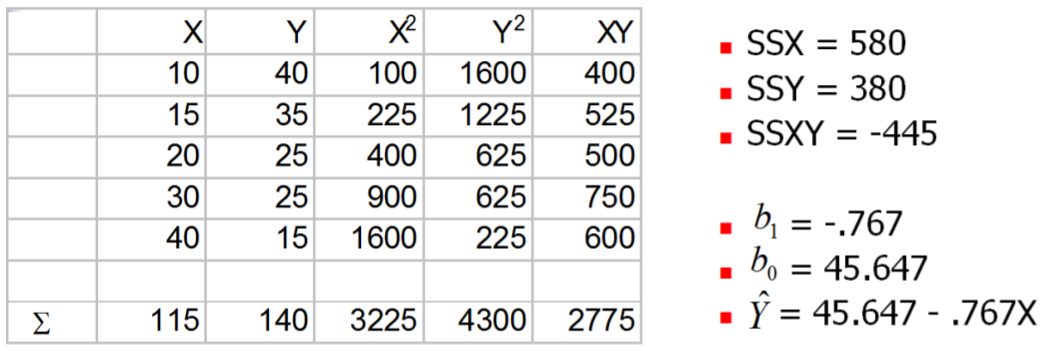
The Sum of Squared Residual Errors (SSE) for this line is 38.578, making it the “best line”. (Compare to the value above, in which we picked the line that perfectly fit the two most extreme points).
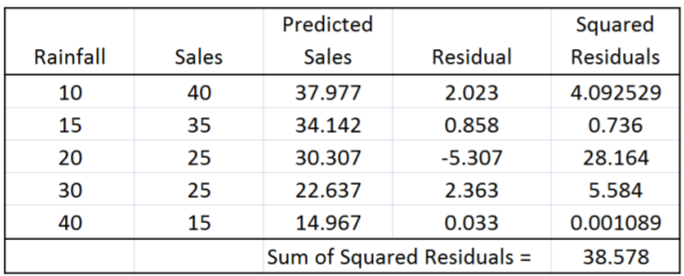
In practice, we will use technology such as Minitab to calculate this line. Here is the example using the Regression Fitted Line Plot option in Minitab, which determines and graphs the regression equation. The point (20,25) has the highest residual error, but the overall Sum of Squared Residual Errors (SSE) is minimized.