
3.6: Distribution and Quantile Functions
- Page ID
- 10146

As usual, our starting point is a random experiment modeled by a with probability space \((\Omega, \mathscr F, \P)\). So to review, \(\Omega\) is the set of outcomes, \(\mathscr F\) is the collection of events, and \(\P\) is the probability measure on the sample space \((\Omega, \mathscr F)\). In this section, we will study two types of functions that can be used to specify the distribution of a real-valued random variable.
Distribution Functions
Definition
Suppose that \(X\) is a random variable with values in \(\R\). The (cumulative) distribution function of \(X\) is the function \(F: \R \to [0, 1]\) defined by \[ F(x) = \P(X \le x), \quad x \in \R\]
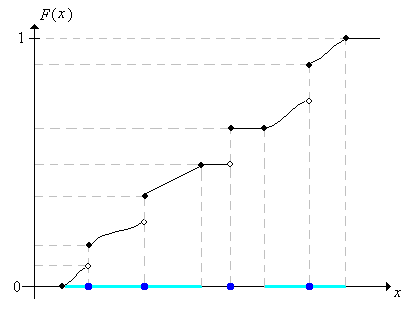
The distribution function is important because it makes sense for any type of random variable, regardless of whether the distribution is discrete, continuous, or even mixed, and because it completely determines the distribution of \(X\). In the picture below, the light shading is intended to represent a continuous distribution of probability, while the darker dots represents points of positive probability; \(F(x)\) is the total probability mass to the left of (and including) \(x\).

Basic Properties
A few basic properties completely characterize distribution functions. Notationally, it will be helpful to abbreviate the limits of \(F\) from the left and right at \(x \in \R\), and at \(\infty\) and \(-\infty\) as follows: \[F(x^+) = \lim_{t \downarrow x} F(t), \; F(x^-) = \lim_{t \uparrow x} F(t), \; F(\infty) = \lim_{t \to \infty} F(t), \; F(-\infty) = \lim_{t \to -\infty} F(t) \]
Suppose that \( F \) is the distribution function of a real-valued random variable \( X \).
- \(F\) is increasing: if \(x \le y\) then \(F(x) \le F(y)\).
- \(F(x^+) = F(x)\) for \(x \in \R\). Thus, \(F\) is continuous from the right.
- \(F(x^-) = \P(X \lt x)\) for \(x \in \R\). Thus, \(F\) has limits from the left.
- \(F(-\infty) = 0\).
- \(F(\infty) = 1\).
Proof
The following result shows how the distribution function can be used to compute the probability that \(X\) is in an interval. Recall that a probability distribution on \(\R\) is completely determined by the probabilities of intervals; thus, the distribution function determines the distribution of \(X\).
Suppose again that \( F \) is the distribution function of a real-valued random variable \( X \). If \(a, \, b \in \R\) with \(a \lt b\) then
- \(\P(X = a) = F(a) - F(a^-)\)
- \(\P(a \lt X \le b) = F(b) - F(a)\)
- \(\P(a \lt X \lt b) = F(b^-) - F(a)\)
- \(\P(a \le X \le b) = F(b) - F(a^-)\)
- \(\P(a \le X \lt b) = F(b^-) - F(a^-)\)
Proof
These results follow from the definition, the basic properties, and the difference rule: \(\P(B \setminus A) = \P(B) - \P(A) \) if \( A, \, B \) are events and \( A \subseteq B\).
- \(\{X = a\} = \{X \le a\} \setminus \{X \lt a\}\), so \(\P(X = a) = \P(X \le a) - \P(X \lt a) = F(a) - F(a^-)\).
- \(\{a \lt X \le b\} = \{X \le b\} \setminus \{X \le a\}\), so \(\P(a \lt X \le b) = \P(X \le b) - \P(X \le a) = F(b) - F(a)\).
- \(\{a \lt X \lt b\} = \{X \lt b\} \setminus \{X \le a\}\), so \(\P(a \lt X \lt b) = \P(X \lt b) - \P(X \le a) = F(b^-) - F(a)\).
- \(\{a \le X \le b\} = \{X \le b\} \setminus \{X \lt a\}\), so \(\P(a \le X \le b) = \P(X \le b) - \P(X \lt a) = F(b) - F(a^-)\).
- \(\{a \le X \lt b\} = \{X \lt b\} \setminus \{X \lt a\}\), so \(\P(a \le X \lt b) = \P(X \lt b) - \P(X \lt a) = F(b^-) - F(a^-)\).
Conversely, if a Function \(F: \R \to [0, 1]\) satisfies the basic properties, then the formulas above define a probability distribution on \(\R\), with \(F\) as the distribution function. For more on this point, read the section on Existence and Uniqueness.
If \(X\) has a continuous distribution, then the distribution function \(F\) is continuous.
Proof
If \( X \) has a continuous distribution, then by definition, \( \P(X = x) = 0 \) so \( \P(X \lt x) = \P(X \le x) \) for \( x \in \R \). Hence from part (a) of the previous theorem, \( F(x^-) = F(x^+) = F(x) \).
Thus, the two meanings of continuous come together: continuous distribution and continuous function in the calculus sense. Next recall that the distribution of a real-valued random variable \( X \) is symmetric about a point \( a \in \R \) if the distribution of \( X - a \) is the same as the distribution of \( a - X \).
Suppose that \(X\) has a continuous distribution on \(\R\) that is symmetric about a point \(a\). Then the distribution function \(F\) satisfies \(F(a - t) = 1 - F(a + t)\) for \(t \in \R\).
Proof
Since \( X - a \) and \( a - X \) have the same distribution, \[ F(a - t) = \P(X \le a - t) = \P(X - a \le -t) = \P(a - X \le -t) = \P(X \ge a + t) = 1 - F(a + t) \]
Relation to Density Functions
There are simple relationships between the distribution function and the probability density function. Recall that if \(X\) takes value in \(S \subseteq \R\) and has probability density function \(f\), we can extend \(f\) to all of \(\R\) by the convention that \(f(x) = 0\) for \(x \in S^c\). As in Definition (1), it's customary to define the distribution function \(F\) on all of \(\R\), even if the random variable takes values in a subset.
Suppose that \(X\) has discrete distribution on a countable subset \(S \subseteq \R\). Let \(f\) denote the probability density function and \(F\) the distribution function.
- \(F(x) = \sum_{t \in S, \, t \le x} f(t)\) for \(x \in \R\)
- \(f(x) = F(x) - F(x^-)\) for \(x \in S\)
Proof
- This follows from the definition of the PDF of \( X \), \( f(t) = \P(X = t) \) for \( t \in S \), and the additivity of probability.
- This is a restatement of part (a) of the theorem above.
Thus, \(F\) is a step function with jumps at the points in \(S\); the size of the jump at \(x\) is \(f(x)\).
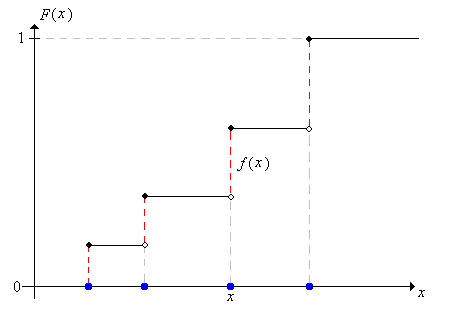
There is an analogous result for a continuous distribution with a probability density function.
Suppose that \(X\) has a continuous distribution on \(\R\) with probability density function \(f\) and distribution function \(F\).
- \(F(x) = \int_{-\infty}^x f(t) dt\) for \(x \in \R\).
- \(f(x) = F^\prime(x)\) if \(f\) is continuous at \(x\).
Proof
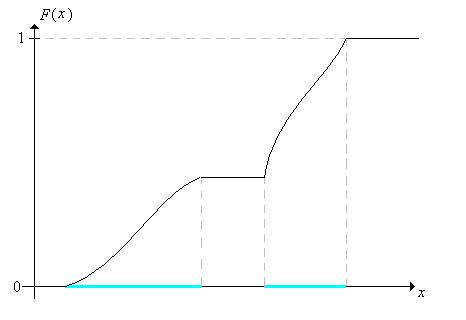
The last result is the basic probabilistic version of the fundamental theorem of calculus. For mixed distributions, we have a combination of the results in the last two theorems.
Suppose that \(X\) has a mixed distribution, with discrete part on a countable subset \(D \subseteq \R\), and continuous part on \(\R \setminus D\). Let \(g\) denote the partial probability density function of the discrete part and assume that the continuous part has partial probability density function \(h\). Let \(F\) denote the distribution function.
- \(F(x) = \sum_{t \in D, \, t \le x} g(t) + \int_{-\infty}^x h(t) dt\) for \(x \in \R\)
- \(g(x) = F(x) - F(x^-)\) for \(x \in D\)
- \(h(x) = F^\prime (x)\) if \(x \notin D\) and \(h\) is continuous at \(x\)
Go back to the graph of a general distribution function. At a point of positive probability, the probability is the size of the jump. At a smooth point of the graph, the continuous probability density is the slope.
Recall that the existence of a probability density function is not guaranteed for a continuous distribution, but of course the distribution function always makes perfect sense. The advanced section on absolute continuity and density functioons has an example of a continuous distribution on the interval \((0, 1)\) that has no probability density function. The distribution function is continuous and strictly increases from 0 to 1 on the interval, but has derivative 0 at almost every point!
Naturally, the distribution function can be defined relative to any of the conditional distributions we have discussed. No new concepts are involved, and all of the results above hold.
Reliability
Suppose again that \(X\) is a real-valued random variable with distribution function \(F\). The function in the following definition clearly gives the same information as \(F\).
The function \(F^c\) defined by \[ F^c(x) = 1 - F(x) = \P(X \gt x), \quad x \in \R\] is the right-tail distribution function of \(X\). Give the mathematical properties of \(F^c\) analogous to the properties of \(F\) in (2).
Answer
- \( F^c \) is decreasing.
- \( F^c(t) \to F^c(x) \) as \( t \downarrow x \) for \( x \in \R \), so \( F^c \) is continuous from the right.
- \( F^c(t) \to \P(X \ge x) \) as \( t \uparrow x \) for \( x \in \R \), so \( F^c \) has left limits.
- \( F^c(x) \to 0 \) as \( x \to \infty \).
- \( F^c(x) \to 1 \) as \( x \to -\infty \).
So \(F\) might be called the left-tail distribution function. But why have two distribution functions that give essentially the same information? The right-tail distribution function, and related functions, arise naturally in the context of reliability theory. For the remainder of this subsection, suppose that \(T\) is a random variable with values in \( [0, \infty) \) and that \( T \) has a continuous distribution with probability density function \( f \). Here are the important defintions:
Suppose that \( T \) represents the lifetime of a device.
- The right tail distribution function \( F^c \) is the reliability function of \( T \).
- The function \(h\) defined by \( h(t) = f(t) \big/ F^c(t)\) for \(t \ge 0 \) is the failure rate function of \( T \).
To interpret the reliability function, note that \(F^c(t) = \P(T \gt t)\) is the probability that the device lasts at least \(t\) time units. To interpret the failure rate function, note that if \( dt \) is small
then \[ \P(t \lt T \lt t + dt \mid T \gt t) = \frac{\P(t \lt T \lt t + dt)}{\P(T \gt t)} \approx \frac{f(t) \, dt}{F^c(t)} = h(t) \, dt \] So \(h(t) \, dt\) is the approximate probability that the device will fail in the interval \((t, t + dt)\), given survival up to time \(t\). Moreover, like the distribution function and the reliability function, the failure rate function also completely determines the distribution of \(T\).
The reliability function can be expressed in terms of the failure rate function by \[ F^c(t) = \exp\left(-\int_0^t h(s) \, ds\right), \quad t \ge 0 \]
Proof
At the points of continuity of \( f \) we have \( \frac{d}{dt}F^c(t) = - f(t) \). Hence
\[ \int_0^t h(s) \, ds = \int_0^t \frac{f(s)}{F^c(s)} \, ds = \int_0^t -\frac{\frac{d}{ds}F^c(s)}{F^c(s)} \, ds = -\ln\left[F^c(t)\right] \]The failure rate function \(h\) satisfies the following properties:
- \(h(t) \ge 0\) for \(t \ge 0\)
- \(\int_0^\infty h(t) \, dt = \infty\)
Proof
- This follows from the definition.
- This follows from the previous result and the fact that \( F^c(t) \to 0 \) as \( t \to \infty \).
Conversely, a function that satisfies these properties is the failure rate function for a continuous distribution on \( [0, \infty) \):
Suppose that \(h: [0, \infty) \to [0, \infty) \) is piecewise continuous and \(\int_0^\infty h(t) \, dt = \infty\). Then the function \( G \) defined by \[ F^c(t) = \exp\left(-\int_0^t h(s) \, ds\right), \quad t \ge 0 \] is a reliability function for a continuous distribution on \( [0, \infty) \)
Proof
The function \( F^c \) is continuous, decreasing, and satisfies \( F^c(0) = 1 \) and \( F^c(t) \to 0 \) as \( t \to \infty \). Hence \( F = 1 - F^c \) is the distribution function for a continuous distribution on \( [0, \infty) \).
Multivariate Distribution Functions
Suppose now that \(X\) and \(Y\) are real-valued random variables for an experiment (that is, defined on the same probability space), so that \((X, Y)\) is random vector taking values in a subset of \(\R^2\).
The distribution function of \((X, Y)\) is the function \(F\) defined by \[ F(x, y) = \P(X \le x, Y \le y), \quad (x, y) \in \R^2\]
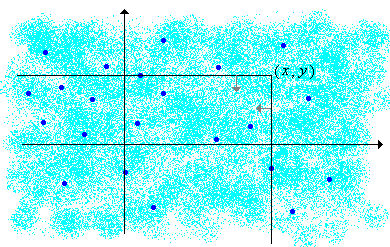
In the graph above, the light shading is intended to suggest a continuous distribution of probability, while the darker dots represent points of positive probability. Thus, \(F(x, y)\) is the total probability mass below and to the left (that is, southwest) of the point \((x, y)\). As in the single variable case, the distribution function of \((X, Y)\) completely determines the distribution of \((X, Y)\).
Suppose that \(a, \, b, \, c, \, d \in \R\) with \(a \lt b\) and \(c \lt d\). Then \[ \P(a \lt X \le b, c \lt Y \le d) = F(b, d) - F(a, d) - F(b, c) + F(a, c) \]
Proof
Note that \( \{X \le a, Y \le d\} \cup \{X \le b, Y \le c\} \cup \{a \lt X \le b, c \lt Y \le d\} = \{X \le b, Y \le d\} \). The intersection of the first two events is \( \{X \le a, Y \le c\} \) while the first and third events and the second and third events are disjoint. Thus, from the inclusion-exclusion rule we have \[ F(a, d) + F(b, c) + \P(a \lt X \le b, c \lt Y \le d) - F(a, c) = F(b, d) \]
A probability distribution on \( \R^2 \) is completely determined by its values on rectangles of the form \( (a, b] \times (c, d] \), so just as in the single variable case, it follows that the distribution function of \( (X, Y) \) completely determines the distribution of \( (X, Y) \). See the advanced section on existence and uniqueness of positive measures in the chapter on Probability Measures for more details.
In the setting of the previous result, give the appropriate formula on the right for all possible combinations of weak and strong inequalities on the left.
The joint distribution function determines the individual (marginal) distribution functions.
Let \(F\) denote the distribution function of \((X, Y)\), and let \(G\) and \(H\) denote the distribution functions of \(X\) and \(Y\), respectively. Then
- \(G(x) = F(x, \infty)\) for \( x \in \R \)
- \(H(y) = F(\infty, y)\) for \( y \in \R \)
Proof
These results follow from the continuity theorem for increasing events. For example, in (a) \[ \P(X \le x) = \P(X \le x, Y \lt \infty) = \lim_{y \to \infty} \P(X \le x, Y \le y) = \lim_{y \to \infty} F(x, y) \]
On the other hand, we cannot recover the distribution function of \( (X, Y) \) from the individual distribution functions, except when the variables are independent.
Random variables \(X\) and \(Y\) are independent if and only if \[ F(x, y) = G(x) H(y), \quad (x, y) \in \R^2\]
Proof
If \( X \) and \( Y \) are independent then \( F(x, y) = \P(X \le x, Y \le y) = \P(X \le x) \P(Y \le y) = G(x) H(y) \) for \( (x, y) \in \R^2 \). Conversely, suppose \( F(x, y) = G(x) H(y) \) for \( (x, y) \in \R^2 \). If \( a, \, b, \, c, \, d \in \R \) with \( a \lt b \) and \( c \lt d \) then from (15), \begin{align} \P(a \lt X \le b, c \lt Y \le d) & = G(b)H(d) - G(a)H(d) -G(b)H(c) + G(a)H(c) \\ & = [G(b) - G(a)][H(d) - H(c)] = \P(a \lt X \le b) \P(c \lt Y \le d) \end{align} so it follows that \( X \) and \( Y \) are independent. (Recall again that a probability distribution on \( \R^2 \) is completely determined by its values on rectangles.)
All of the results of this subsection generalize in a straightforward way to \(n\)-dimensional random vectors. Only the notation is more complicated.
The Empirical Distribution Function
Suppose now that \( X \) is a real-valued random variable for a basic random experiment and that we repeat the experiment \( n \) times independently. This generates (for the new compound experiment) a sequence of independent variables \( (X_1, X_2, \ldots, X_n) \) each with the same distribution as \( X \). In statistical terms, this sequence is a random sample of size \( n \) from the distribution of \( X \). In statistical inference, the observed values \((x_1, x_2, \ldots, x_n)\) of the random sample form our data.
The empirical distribution function, based on the data \( (x_1, x_2, \ldots, x_n) \), is defined by \[ F_n(x) = \frac{1}{n} \#\left\{i \in \{1, 2, \ldots, n\}: x_i \le x\right\} = \frac{1}{n} \sum_{i=1}^n \bs{1}(x_i \le x), \quad x \in \R\]
Thus, \(F_n(x)\) gives the proportion of values in the data set that are less than or equal to \(x\). The function \(F_n\) is a statistical estimator of \(F\), based on the given data set. This concept is explored in more detail in the section on the sample mean in the chapter on Random Samples. In addition, the empirical distribution function is related to the Brownian bridge stochastic process which is studied in the chapter on Brownian motion.
Quantile Functions
Definitions
Suppose again that \( X \) is a real-valued random variable with distribution function \( F \).
For \(p \in (0, 1)\), a value of \(x\) such that \( F(x^-) = \P(X \lt x) \le p\) and \(F(x) = \P(X \le x) \ge p\) is called a quantile of order \(p\) for the distribution.
Roughly speaking, a quantile of order \(p\) is a value where the graph of the distribution function crosses (or jumps over) \(p\). For example, in the picture below, \(a\) is the unique quantile of order \(p\) and \(b\) is the unique quantile of order \(q\). On the other hand, the quantiles of order \(r\) form the interval \([c, d]\), and moreover, \(d\) is a quantile for all orders in the interval \([r, s]\). Note also that if \( X \) has a continuous distribution (so that \( F \) is continuous) and \( x \) is a quantile of order \( p \in (0, 1) \), then \( F(x) = p \).
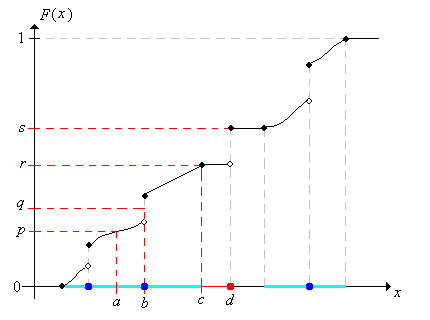
Note that there is an inverse relation of sorts between the quantiles and the cumulative distribution values, but the relation is more complicated than that of a function and its ordinary inverse function, because the distribution function is not one-to-one in general. For many purposes, it is helpful to select a specific quantile for each order; to do this requires defining a generalized inverse of the distribution function \( F \).
The quantile function \( F^{-1} \) of \( X \) is defined by \[ F^{-1}(p) = \min\{x \in \R: F(x) \ge p\}, \quad p \in (0, 1)\]
\( F^{-1} \) is well defined
Since \(F\) is right continuous and increasing, \( \{x \in \R: F(x) \ge p\} \) is an interval of the form \( [a, \infty) \). Thus, the minimum of the set is \( a \).
Note that if \(F\) strictly increases from 0 to 1 on an interval \(S\) (so that the underlying distribution is continuous and is supported on \(S\)), then \(F^{-1}\) is the ordinary inverse of \(F\). We do not usually define the quantile function at the endpoints 0 and 1. If we did, note that \(F^{-1}(0)\) would always be \(-\infty\).
Properties
The following exercise justifies the name: \(F^{-1}(p)\) is the minimum of the quantiles of order \(p\).
Let \(p \in (0, 1)\).
- \(F^{-1}(p)\) is a quantile of order \(p\).
- If \(x\) is a quantile of order \(p\) then \(F^{-1}(p) \le x\).
Proof
Let \( y = F^{-1}(p) \).
- Note that \( F(y) \ge p \) by definition, and if \( x \lt y \) then \( F(x) \lt p \). Hence \( F(y^-) \le p \). Therefore \( y \) is a quantile of order \( p \).
- Suppose that \( x \) is a quantile of order \( p \). Then \( F(x) \ge p \) so by definition, \( y \le x \).
Other basic properties of the quantile function are given in the following theorem.
\(F^{-1}\) satisfies the following properties:
- \(F^{-1}\) is increasing on \((0, 1)\).
- \(F^{-1}\left[F(x)\right] \le x\) for any \(x \in \R\) with \(F(x) \lt 1\).
- \(F\left[F^{-1}(p)\right] \ge p\) for any \(p \in (0, 1)\).
- \(F^{-1}\left(p^-\right) = F^{-1}(p)\) for \(p \in (0, 1)\). Thus \(F^{-1}\) is continuous from the left.
- \(F^{-1}\left(p^+\right) = \inf\{x \in \R: F(x) \gt p\}\) for \(p \in (0, 1)\). Thus \(F^{-1}\) has limits from the right.
Proof
- Note that if \( p, \; q \in (0, 1) \) with \( p \le q \), then \( \{x \in \R: F(x) \ge q\} \subseteq \{x \in \R: F(x) \ge p\} \).
- This follows from the definition: \( F^{-1}\left[F(x)\right] \) is the smallest \( y \in \R \) with \( F(y) \ge F(x) \).
- This also follows from the definition: \( F^{-1}(p) \) is a value \( y \in \R \) satisfying \( F(y) \ge p \).
- This follows from the fact that \( F \) is continuous from the right
- This follows from the fact that \( F \) has limits from the left.
As always, the inverse of a function is obtained essentially by reversing the roles of independent and dependent variables. In the graphs below, note that jumps of \(F\) become flat portions of \(F^{-1}\) while flat portions of \(F\) become jumps of \(F^{-1}\). For \( p \in (0, 1) \), the set of quantiles of order \( p \) is the closed, bounded interval \( \left[F^{-1}(p), F^{-1}(p^+)\right] \). Thus, \( F^{-1}(p) \) is the smallest quantile of order \( p \), as we noted earlier, while \( F^{-1}(p^+) \) is the largest quantile of order \( p \).
.png?revision=1)
Figure \(\PageIndex{7}\): Graph of the distribution function
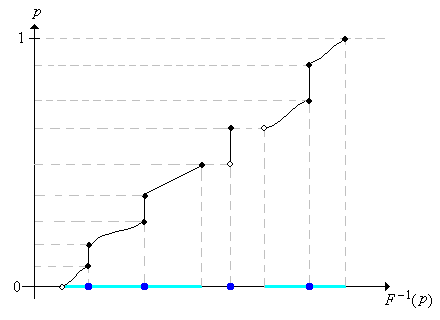
Figure \(\PageIndex{8}\): Graph of the quantile function
The following basic property will be useful in simulating random variables, a topic explored in the section on transformations of random variables.
For \(x \in \R\) and \(p \in (0, 1)\), \(F^{-1}(p) \le x\) if and only if \(p \le F(x)\).
Proof
Suppose that \( F^{-1}(p) \le x \). Then, since \( F \) is increasing, \( F\left[F^{-1}(p)\right] \le F(x) \). But \( p \le F\left[F^{-1}(p)\right] \) by part (c) of the previous result, so \( p \le F(x) \). Conversely, suppose that \( p \le F(x) \). Then, since \( F^{-1} \) is increasing, \( F^{-1}(p) \le F^{-1}[F(x)] \). But \( F^{-1}[F(x)] \le x \) by part (b) of the previous result, so \( F^{-1}(p) \le x \).
Special Quantiles
Certain quantiles are important enough to deserve special names.
Suppose that \( X \) is a real-valued random variable.
- A quantile of order \(\frac{1}{4}\) is a first quartile of the distribution.
- A quantile of order \(\frac{1}{2}\) is a median or second quartile of the distribution.
- A quantile of order \(\frac{3}{4}\) is a third quartile of the distribution.
When there is only one median, it is frequently used as a measure of the center of the distribution, since it divides the set of values of \( X \) in half, by probability. More generally, the quartiles can be used to divide the set of values into fourths, by probability.
Assuming uniqueness, let \(q_1\), \(q_2\), and \(q_3\) denote the first, second, and third quartiles of \(X\), respectively, and let \(a = F^{-1}\left(0^+\right)\) and \(b = F^{-1}(1)\).
- The interquartile range is defined to be \( q_3 - q_1 \).
- The five parameters \( (a, q_1, q_2, q_3, b) \) are referred to as the five number summary of the distribution.
Note that the interval \( [q_1, q_3] \) roughly gives the middle half of the distribution, so the interquartile range, the length of the interval, is a natural measure of the dispersion of the distribution about the median. Note also that \(a\) and \(b\) are essentially the minimum and maximum values of \(X\), respectively, although of course, it's possible that \( a = -\infty \) or \( b = \infty \) (or both). Collectively, the five parameters give a great deal of information about the distribution in terms of the center, spread, and skewness. Graphically, the five numbers are often displayed as a boxplot or box and whisker plot, which consists of a line extending from the minimum value \(a\) to the maximum value \(b\), with a rectangular box from \(q_1\) to \(q_3\), and whiskers
at \(a\), the median \(q_2\), and \(b\). Roughly speaking, the five numbers separate the set of values of \(X\) into 4 intervals of approximate probability \(\frac{1}{4}\) each.
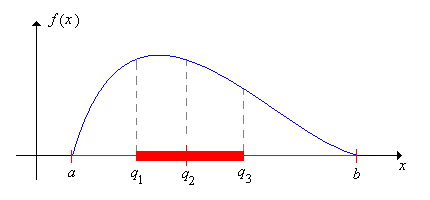
Suppose that \( X \) has a continuous distribution that is symmetric about a point \(a \in \R\). If \(a + t\) is a quantile of order \(p \in (0, 1) \) then \(a - t\) is a quantile of order \(1 - p\).
Proof
Note that this is the quantile function version of symmetry result for the distribution function. If \( a + t \) is a qantile of order \( p \) then (since \( X \) has a continuous distribution) \( F(a + t) = p \). But then \( F(a - t) = 1 - F(a + t) = 1 - p \) so \( a - t \) is a quantile of order \( 1 - p \).
Examples and Applications
Distributions of Different Types
Let \(F\) be the function defined by \[ F(x) = \begin{cases} 0, & x \lt 1\\ \frac{1}{10}, & 1 \le x \lt \frac{3}{2}\\ \frac{3}{10}, & \frac{3}{2} \le x \lt 2\\ \frac{6}{10}, & 2 \le x \lt \frac{5}{2}\\ \frac{9}{10}, & \frac{5}{2} \le x \lt 3\\ 1, & x \ge 3; \end{cases}\]
- Sketch the graph of \(F\) and show that \(F\) is the distribution function for a discrete distribution.
- Find the corresponding probability density function \(f\) and sketch the graph.
- Find \(\P(2 \le X \lt 3)\) where \(X\) has this distribution.
- Find the quantile function and sketch the graph.
- Find the five number summary and sketch the boxplot.
Answer
- Note that \( F \) increases from 0 to 1, is a step function, and is right continuous.
- \(f(x) = \begin{cases} \frac{1}{10}, & x = 1 \\ \frac{1}{5}, & x = \frac{3}{2} \\ \frac{3}{10}, & x = 2 \\ \frac{3}{10}, & x = \frac{5}{2} \\ \frac{1}{10}, & x = 3 \end{cases}\)
- \(\P(2 \le X \lt 3) = \frac{3}{5}\)
- \(F^{-1}(p) = \begin{cases} 1, & 0 \lt p \le \frac{1}{10} \\ \frac{3}{2}, & \frac{1}{10} \lt p \le \frac{3}{10} \\ 2, & \frac{3}{10} \lt p \le \frac{6}{10} \\ \frac{5}{2}, & \frac{6}{10} \lt p \le \frac{9}{10} \\ 3, & \frac{9}{10} \lt p \le 1 \end{cases}\)
- \(\left(1, \frac{3}{2}, 2, \frac{5}{2}, 3\right)\)
Let \(F\) be the function defined by
\[F(x) = \begin{cases} 0, & x \lt 0\\ \frac{x}{x + 1}, & x \ge 0 \end{cases}\]- Sketch the graph of \(F\) and show that \(F\) is the distribution function for a continuous distribution.
- Find the corresponding probability density function \(f\) and sketch the graph.
- Find \(\P(2 \le X \lt 3)\) where \(X\) has this distribution.
- Find the quantile function and sketch the graph.
- Find the five number summary and sketch the boxplot.
Answer
- Note that \( F \) is continuous and increases from 0 to 1.
- \(f(x) = \frac{1}{(x + 1)^2}, \quad x \gt 0\)
- \(\P(2 \le X \lt 3) = \frac{1}{12}\)
- \(F^{-1}(p) = \frac{p}{1 - p}, \quad 0 \lt p \lt 1\)
- \(\left(0, \frac{1}{3}, 1, 3, \infty\right)\)
The expression \( \frac{p}{1 - p} \) that occurs in the quantile function in the last exercise is known as the odds ratio associated with \( p \), particularly in the context of gambling.
Let \(F\) be the function defined by
\[ F(x) = \begin{cases} 0, & x \lt 0\\ \frac{1}{4} x, & 0 \le x \lt 1\\ \frac{1}{3} + \frac{1}{4} (x - 1)^2, & 1 \le x \lt 2\\ \frac{2}{3} + \frac{1}{4} (x - 2)^3, & 2 \le x \lt 3\\ 1, & x \ge 3 \end{cases}\]- Sketch the graph of \(F\) and show that \(F\) is the distribution function of a mixed distribution.
- Find the partial probability density function of the discrete part and sketch the graph.
- Find the partial probability density function of the continuous part and sketch the graph.
- Find \(\P(2 \le X \lt 3)\) where \(X\) has this distribution.
- Find the quantile function and sketch the graph.
- Find the five number summary and sketch the boxplot.
Answer
- Note that \( F \) is piece-wise continuous, increases from 0 to 1, and is right continuous.
- \(g(1) = g(2) = g(3) = \frac{1}{12}\)
- \(h(x) = \begin{cases} \frac{1}{4}, & 0 \lt x \lt 1 \\ \frac{1}{2}(x - 1), & 1 \lt x \lt 2 \\ \frac{3}{4}(x - 2)^2, & 2 \lt x \lt 3 \end{cases}\)
- \(\P(2 \le X \lt 3) = \frac{1}{3}\)
- \(F^{-1}(p) = \begin{cases} 4 p, & 0 \lt p \le \frac{1}{4} \\ 1, & \frac{1}{4} \lt p \le \frac{1}{3} \\ 1 + \sqrt{4(p - \frac{1}{3})}, & \frac{1}{3} \lt p \le \frac{7}{12} \\ 2, & \frac{7}{12} \lt p \le \frac{2}{3} \\ 2 + \sqrt[3]{4 (p - \frac{2}{3})}, & \frac{2}{3} \lt p \le \frac{11}{12} \\ 3, & \frac{11}{12} \lt p \le 1 \end{cases}\)
- \(\left(0, 1, 1 + \sqrt{\frac{2}{3}}, 2 + \sqrt[3]{\frac{1}{3}}, 3\right)\)
The Uniform Distribution
Suppose that \(X\) has probability density function \(f(x) = \frac{1}{b - a}\) for \(x \in [a, b]\), where \(a, \, b \in \R\) and \(a \lt b\).
- Find the distribution function and sketch the graph.
- Find the quantile function and sketch the graph.
- Compute the five-number summary.
- Sketch the graph of the probability density function with the boxplot on the horizontal axis.
Answer
- \(F(x) = \frac{x - a}{b - a}, \quad a \le x \lt b\)
- \(F^{-1}(p) = a + (b - a) p, \quad 0 \le p \le 1\)
- \(\left(a, \frac{3 a + b}{4}, \frac{a + b}{2}, \frac{a + 3 b}{4}, b\right)\)
The distribution in the last exercise is the uniform distribution on the interval \( [a, b] \). The left endpoint \( a \) is the location parameter and the length of the interval \( w = b - a \) is the scale parameter. The uniform distribution models a point chose at random
from the interval, and is studied in more detail in the chapter on Special Distributions.
In the special distribution calculator, select the continuous uniform distribution. Vary the location and scale parameters and note the shape of the probability density function and the distribution function.
The Exponential Distribution
Suppose that \(T\) has probability density function \(f(t) = r e^{-r t}\) for \(0 \le t \lt \infty\), where \(r \gt 0\) is a parameter.
- Find the distribution function and sketch the graph.
- Find the reliability function and sketch the graph.
- Find the failure rate function and sketch the graph.
- Find the quantile function and sketch the graph.
- Compute the five-number summary.
- Sketch the graph of the probability density function with the boxplot on the horizontal axis.
Answer
- \(F(t) = 1 - e^{-r t}, \quad 0 \le t \lt \infty\)
- \(F^c(t) = e^{-r t}, \quad 0 \le t \lt \infty\)
- \(h(t) = r, \quad 0 \le t \lt \infty\)
- \(F^{-1}(p) = -\frac{1}{r} \ln(1 - p), \quad 0 \le p \lt 1\)
- \(\left(0, \frac{1}{r}[\ln 4 - \ln 3], \frac{1}{r} \ln 2, \frac{1}{r} \ln 4 , \infty\right)\)
The distribution in the last exercise is the exponential distribution with rate parameter \(r\). Note that this distribution is characterized by the fact that it has constant failure rate (and this is the reason for referring to \( r \) as the rate parameter). The reciprocal of the rate parameter is the scale parameter. The exponential distribution is used to model failure times and other random times under certain conditions, and is studied in detail in the chapter on The Poisson Process.
In the special distribution calculator, select the exponential distribution. Vary the scale parameter \(b\) and note the shape of the probability density function and the distribution function.
The Pareto Distribution
Suppose that \(X\) has probability density function \(f(x) = \frac{a}{x^{a+1}}\) for \(1 \le x \lt \infty\) where \(a \gt 0\) is a parameter.
- Find the distribution function.
- Find the reliability function.
- Find the failure rate function.
- Find the quantile function.
- Compute the five-number summary.
- In the case \(a = 2\), sketch the graph of the probability density function with the boxplot on the horizontal axis.
Answer
- \(F(x) = 1 - \frac{1}{x^a}, \quad 1 \le x \lt \infty\)
- \(F^c(x) = \frac{1}{x^a}, \quad 1 \le x \lt \infty\)
- \(h(x) = \frac{a}{x}, \quad 1 \le x \lt \infty\)
- \(F^{-1}(p) = (1 - p)^{-1/a}, \quad 0 \le p \lt 1\)
- \(\left(1, \left(\frac{3}{4}\right)^{-1 / a}, \left(\frac{1}{2}\right)^{-1/a}, \left(\frac{1}{4}\right)^{-1/a}, \infty \right)\)
The distribution in the last exercise is the Pareto distribution with shape parameter \(a\), named after Vilfredo Pareto. The Pareto distribution is a heavy-tailed distribution that is sometimes used to model income and certain other economic variables. It is studied in detail in the chapter on Special Distributions.
In the special distribution calculator, select the Pareto distribution. Keep the default value for the scale parameter, but vary the shape parameter and note the shape of the density function and the distribution function.
The Cauchy Distribution
Suppose that \(X\) has probability density function \( f(x) = \frac{1}{\pi (1 + x^2)} \) for \(x \in \R\).
- Find the distribution function and sketch the graph.
- Find the quantile function and sketch the graph.
- Compute the five-number summary and the interquartile range.
- Sketch the graph of the probability density function with the boxplot on the horizontal axis.
Answer
- \(F(x) = \frac{1}{2} + \frac{1}{\pi} \arctan x, \quad x \in \R\)
- \(F^{-1}(p) = \tan\left[\pi\left(p - \frac{1}{2}\right)\right], \quad 0 \lt p \lt 1\)
- \((-\infty, -1, 0, 1, \infty)\), \(\text{IQR} = 2\)
The distribution in the last exercise is the Cauchy distribution, named after Augustin Cauchy. The Cauchy distribution is studied in more generality in the chapter on Special Distributions.
In the special distribution calculator, select the Cauchy distribution and keep the default parameter values. Note the shape of the density function and the distribution function.
The Weibull Distribution
Let \(h(t) = k t^{k - 1}\) for \(0 \lt t \lt \infty\) where \(k \gt 0\) is a parameter.
- Sketch the graph of \(h\) in the cases \(0 \lt k \lt 1\), \(k = 1\), \(1 \lt k \lt 2\), \( k = 2 \), and \( k \gt 2 \).
- Show that \(h\) is a failure rate function.
- Find the reliability function and sketch the graph.
- Find the distribution function and sketch the graph.
- Find the probability density function and sketch the graph.
- Find the quantile function and sketch the graph.
- Compute the five-number summary.
Answer
- \( h \) is decreasing and concave upward if \( 0 \lt k \lt 1 \); \( h = 1 \) (constant) if \( k = 1 \); \( h \) is increasing and concave downward if \( 1 \lt k \lt 2 \); \( h(t) = t \) (linear) if \( k = 2 \); \( h \) is increasing and concave upward if \( k \gt 2 \);
- \( h(t) \gt 0 \) for \( 0 \lt t \lt \infty \) and \( \int_0^\infty h(t) \, dt = \infty \)
- \(F^c(t) = \exp\left(-t^k\right), \quad 0 \le t \lt \infty\)
- \(F(t) = 1 - \exp\left(-t^k\right), \quad 0 \le t \lt \infty\)
- \(f(t) = k t^{k-1} \exp\left(-t^k\right), \quad 0 \le t \lt \infty\)
- \(F^{-1}(p) = [-\ln(1 - p)]^{1/k}, \quad 0 \le p \lt 1\)
- \(\left(0, [\ln 4 - \ln 3]^{1/k}, [\ln 2]^{1/k}, [\ln 4]^{1/k}, \infty\right)\)
The distribution in the previous exercise is the Weibull distributions with shape parameter \(k\), named after Walodi Weibull. The Weibull distribution is studied in detail in the chapter on Special Distributions. Since this family includes increasing, decreasing, and constant failure rates, it is widely used to model the lifetimes of various types of devices.
In the special distribution calculator, select the Weibull distribution. Keep the default scale parameter, but vary the shape parameter and note the shape of the density function and the distribution function.
Beta Distributions
Suppose that \(X\) has probability density function \(f(x) = 12 x^2 (1 - x)\) for \(0 \le x \le 1\).
- Find the distribution function of \(X\) and sketch the graph.
- Find \( \P\left(\frac{1}{4} \le X \le \frac{1}{2}\right) \).
- Compute the five number summary and the interquartile range. You will have to approximate the quantiles.
- Sketch the graph of the density function with the boxplot on the horizontal axis.
Answer
- \(F(x) = 4 x^3 - 3 x^4, \quad 0 \le x \le 1\)
- \(\P\left(\frac{1}{4} \le X \le \frac{1}{2}\right) = \frac{67}{256}\)
- \((0, 0.4563, 0.6413, 0.7570, 1)\), \(\text{IQR} = 0.3007\)
Suppose that \(X\) has probability density function \(f(x) = \frac{1}{\pi \sqrt{x (1 - x)}}\) for \(0 \lt x \lt 1\).
- Find the distribution function of \(X\) and sketch the graph.
- Compute \( \P\left(\frac{1}{3} \le X \le \frac{2}{3}\right) \).
- Find the quantile function and sketch the graph.
- Compute the five number summary and the interquartile range.
- Sketch the graph of the probability density function with the boxplot on the horizontal axis.
Answer
- \(F(x) = \frac{2}{\pi} \arcsin\left(\sqrt{x}\right), \quad 0 \le x \le 1\)
- \(\P\left(\frac{1}{3} \le X \le \frac{2}{3}\right) = 0.2163\)
- \(F^{-1}(p) = \sin^2\left(\frac{\pi}{2} p\right), \quad 0 \lt p \lt 1\)
- \(\left(0, \frac{1}{2} - \frac{\sqrt{2}}{4}, \frac{1}{2}, \frac{1}{2} + \frac{\sqrt{2}}{4}, 1\right)\), \(\text{IQR} = \frac{\sqrt{2}}{2}\)
The distributions in the last two exercises are examples of beta distributions. The particular beta distribution in the last exercise is also known as the arcsine distribution; the distribution function explains the name. Beta distributions are used to model random proportions and probabilities, and certain other types of random variables, and are studied in detail in the chapter on Special Distributions.
In the special distribution calculator, select the beta distribution. For each of the following parameter values, note the location and shape of the density function and the distribution function.
- \(a = 3\), \(b = 2\). This gives the first beta distribution above.
- \(a = b = \frac{1}{2}\). This gives the arcsine distribution above
Logistic Distribution
Let \(F(x) = \frac{e^x}{1 + e^x}\) for \(x \in \R\).
- Show that \(F\) is a distribution function for a continuous distribution, and sketch the graph.
- Compute \( \P(-1 \le X \le 1) \) where \(X\) is a random variable with distribution function \(F\).
- Find the quantile function and sketch the graph.
- Compute the five-number summary and the interquartile range.
- Find the probability density function and sketch the graph with the boxplot on the horizontal axis.
Answer
- Note that \( F \) is continuous, and increases from 0 to 1.
- \(\P(-1 \le X \le 1) = 0.4621\)
- \(F^{-1}(p) = \ln \left(\frac{p}{1 - p}\right), \quad 0 \lt p \lt 1\)
- \((-\infty, -\ln 3, 0, \ln 3, \infty)\)
- \(f(x) = \frac{e^x}{(1 + e^x)^2}, \quad x \in \R\)
The distribution in the last exercise is an logistic distribution and the quantile function is known as the logit function. The logistic distribution is studied in detail in the chapter on Special Distributions.
In the special distribution calculator, select the logistic distribution and keep the default parameter values. Note the shape of the probability density function and the distribution function.
Extreme Value Distribution
Let \(F(x) = e^{-e^{-x}}\) for \(x \in \R\).
- Show that \(F\) is a distribution function for a continuous distribution, and sketch the graph.
- Compute \(\P(-1 \le X \le 1)\) where \(X\) is a random variable with distribution function \(F\).
- Find the quantile function and sketch the graph.
- Compute the five-number summary.
- Find the probability density function and sketch the graph with the boxplot on the horizontal axis.
Answer
- Note that \( F \) is continuous, and increases from 0 to 1.
- \(\P(-1 \le X \le 1) = 0.6262\)
- \(F^{-1}(p) = -\ln(-\ln p), \quad 0 \lt p \lt 1\)
- \(\left(-\infty, -\ln(\ln 4), -\ln(\ln 2), -\ln(\ln 4 - \ln 3), \infty\right)\)
- \(f(x) = e^{-e^{-x}} e^{-x}, \quad x \in \R\)
The distribution in the last exercise is the type 1 extreme value distribution, also known as the Gumbel distribution in honor of Emil Gumbel. Extreme value distributions are studied in detail in the chapter on Special Distributions.
In the special distribution calculator, select the extreme value distribution and keep the default parameter values. Note the shape and location of the probability density function and the distribution function.
The Standard Normal Distribution
Recall that the standard normal distribution has probability density function \( \phi \) given by \[ \phi(z) = \frac{1}{\sqrt{2 \pi}} e^{-\frac{1}{2} z^2}, \quad z \in \R\] This distribution models physical measurements of all sorts subject to small, random errors, and is one of the most important distributions in probability. The normal distribution is studied in more detail in the chapter on Special Distributions. The distribution function \( \Phi \), of course, can be expressed as \[ \Phi(z) = \int_{-\infty}^z \phi(x) \, dx, \quad z \in \R \] but \( \Phi \) and the quantile function \( \Phi^{-1} \) cannot be expressed, in closed from, in terms of elementary functions. Because of the importance of the normal distribution \( \Phi \) and \( \Phi^{-1} \) are themselves considered special functions, like \( \sin \), \( \ln \), and many others. Approximate values of these functions can be computed using most mathematical and statistical software packages. Because the distribution is symmetric about 0, \( \Phi(-z) = 1 - \Phi(z) \) for \( z \in \R \), and equivalently, \( \Phi^{-1}(1 - p) = -\Phi^{-1}(p)\). In particular, the median is 0.
Open the sepcial distribution calculator and choose the normal distribution. Keep the default parameter values and select CDF view. Note the shape and location of the distribution/quantile function. Compute each of the following:
- The first and third quartiles
- The quantiles of order 0.9 and 0.1
- The quantiles of order 0.95 and 0.05
Miscellaneous Exercises
Suppose that \(X\) has probability density function \(f(x) = -\ln x\) for \(0 \lt x \le 1\).
- Sketch the graph of \(f\).
- Find the distribution function \(F\) and sketch the graph.
- Find \( \P\left(\frac{1}{3} \le X \le \frac{1}{2}\right) \).
Answer
- \(F(x) = x - x \ln x, \quad 0 \lt x \lt 1\)
- \(\P(\frac{1}{3} \le X \le \frac{1}{2}) = \frac{1}{6} + \frac{1}{2} \ln 2 - \frac{1}{3} \ln 3\)
Suppose that a pair of fair dice are rolled and the sequence of scores \((X_1, X_2)\) is recorded.
- Find the distribution function of \(Y = X_1 + X_2\), the sum of the scores.
- Find the distribution function of \( V = \max \{X_1, X_2\} \), the maximum score.
- Find the conditional distribution function of \(Y\) given \(V = 5\).
Answer
The random variables are discrete, so the CDFs are step functions, with jumps at the values of the variables. The following tables give the values of the CDFs at the values of the random variables.
-
\(y\) 2 3 4 5 6 7 8 9 10 11 12 \(\P(Y \le y)\) \(\frac{1}{36}\) \(\frac{3}{36}\) \(\frac{6}{36}\) \(\frac{10}{36}\) \(\frac{15}{36}\) \(\frac{21}{36}\) \(\frac{26}{36}\) \(\frac{30}{36}\) \(\frac{33}{36}\) \(\frac{35}{36}\) 1 -
\(v\) 1 2 3 4 5 6 \(\P(V \le v)\) \(\frac{1}{36}\) \(\frac{4}{36}\) \(\frac{9}{36}\) \(\frac{16}{36}\) \(\frac{25}{36}\) 1 -
\(y\) 6 7 8 9 10 \(\P(Y \le y \mid V = 5)\) \(\frac{2}{9}\) \(\frac{4}{9}\) \(\frac{6}{9}\) \(\frac{8}{9}\) 1
Suppose that \((X, Y)\) has probability density function \(f(x, y) = x + y\) for \(0 \le x \le 1\), \(0 \le y \le 1\).
- Find the distribution function of \(X, Y)\).
- Compute \(\P\left(\frac{1}{4} \le X \le \frac{1}{2}, \frac{1}{3} \le Y \le \frac{2}{3}\right)\).
- Find the distribution function of \(X\).
- Find the distribution function of \(Y\).
- Find the conditional distribution function of \(X\) given \(Y = y\) for \(0 \lt y \lt 1 \).
- Find the conditional distribution function of \(Y\) given \(X = x\) for \(0 \lt x \lt 1\).
- Are \(X\) and \(Y\) independent?
Answer
- \(F(x, y) = \frac{1}{2}\left(x y^2 + y x^2\right); \quad 0 \lt x \lt 1, \; 0 \lt y \lt 1\)
- \(\P\left(\frac{1}{4} \le X \le \frac{1}{2}, \frac{1}{3} \le Y \le \frac{2}{3}\right) = \frac{7}{96}\)
- \(G(x) = \frac{1}{2}\left(x + x^2\right), \quad 0 \lt x \lt 1\)
- \(H(y) = \frac{1}{2}\left(y + y^2\right), \quad 0 \lt y \lt 1\)
- \(G(x \mid y) = \frac{x^2 / 2 + x y}{y + 1/2}; \quad 0 \lt x \lt 1, \; 0 \lt y \lt 1\)
- \(H(y \mid x) = \frac{y^2 / 2 + x y}{x + 1/2}; \quad 0 \lt x \lt 1, \; 0 \lt y \lt 1\)
Statistical Exercises
For the M&M data, compute the empirical distribution function of the total number of candies.
Answer
Let \(N\) denote the total number of candies. The empirical distribution function of \(N\) is a step function; the following table gives the values of the function at the jump points.
| \(n\) | 50 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 |
|---|---|---|---|---|---|---|---|---|---|---|
| \(\P(N \le n)\) | \(\frac{1}{30}\) | \(\frac{2}{30}\) | \(\frac{3}{30}\) | \(\frac{7}{30}\) | \(\frac{11}{30}\) | \(\frac{14}{30}\) | \(\frac{23}{30}\) | \(\frac{26}{30}\) | \(\frac{28}{30}\) | 1 |
For the cicada data, let \(BL\) denotes body length and let \(G\) denote gender. Compute the empirical distribution function of the following variables:
- \(BL\)
- \(BL\) given \(G = 1\) (male)
- \(BL\) given \(G = 0\) (female).
- Do you believe that \(BL\) and \(G\) are independent?
For statistical versions of some of the topics in this section, see the chapter on Random Samples, and in particular, the sections on empirical distributions and order statistics.