
4.1: Discrete Conditional Probability
- Page ID
- 3135

Conditional Probability
In this section we ask and answer the following question. Suppose we assign a distribution function to a sample space and then learn that an event \(E\) has occurred. How should we change the probabilities of the remaining events? We shall call the new probability for an event \(F\) the and denote it by \(P(F|E)\).
An experiment consists of rolling a die once. Let \(X\) be the outcome. Let \(F\) be the event \(\{X = 6\}\), and let \(E\) be the event \(\{X > 4\}\). We assign the distribution function \(m(\omega) = 1/6\) for \(\omega = 1, 2, \ldots , 6\). Thus, \(P(F) = 1/6\). Now suppose that the die is rolled and we are told that the event \(E\) has occurred. This leaves only two possible outcomes: 5 and 6. In the absence of any other information, we would still regard these outcomes to be equally likely, so the probability of \(F\) becomes 1/2, making \(P(F|E) = 1/2\).
In the Life Table (see Appendix C), one finds that in a population of 100,000 females, 89.835% can expect to live to age 60, while 57.062% can expect to live to age 80. Given that a woman is 60, what is the probability that she lives to age 80?
Solution
This is an example of a conditional probability. In this case, the original sample space can be thought of as a set of 100,000 females. The events \(E\) and \(F\) are the subsets of the sample space consisting of all women who live at least 60 years, and at least 80 years, respectively. We consider \(E\) to be the new sample space, and note that \(F\) is a subset of \(E\). Thus, the size of \(E\) is 89,835, and the size of \(F\) is 57,062. So, the probability in question equals \(57{,}062/89{,}835 = .6352\). Thus, a woman who is 60 has a 63.52% chance of living to age 80.
Consider our voting example from Section 1.2: three candidates A, B, and C are running for office. We decided that A and B have an equal chance of winning and C is only 1/2 as likely to win as A. Let \(A\) be the event “A wins," \(B\) that “B wins," and \(C\) that “C wins." Hence, we assigned probabilities \(P(A) = 2/5\), \(P(B) = 2/5\), and \(P(C) = 1/5\).
Suppose that before the election is held, \(A\) drops out of the race. As in Example , it would be natural to assign new probabilities to the events \(B\) and \(C\) which are proportional to the original probabilities. Thus, we would have \(P(B|~A) = 2/3\), and \(P(C|~A) = 1/3\). It is important to note that any time we assign probabilities to real-life events, the resulting distribution is only useful if we take into account all relevant information. In this example, we may have knowledge that most voters who favor \(A\) will vote for \(C\) if \(A\) is no longer in the race. This will clearly make the probability that \(C\) wins greater than the value of 1/3 that was assigned above.
In these examples we assigned a distribution function and then were given new information that determined a new sample space, consisting of the outcomes that are still possible, and caused us to assign a new distribution function to this space.
We want to make formal the procedure carried out in these examples. Let \(\Omega = \{\omega_1,\omega_2,\dots,\omega_r\}\) be the original sample space with distribution function \(m(\omega_j)\) assigned. Suppose we learn that the event \(E\) has occurred. We want to assign a new distribution function \(m(\omega_j|E)\) to \(\Omega\) to reflect this fact. Clearly, if a sample point \(\omega_j\) is not in \(E\), we want \(m(\omega_j|E) = 0\). Moreover, in the absence of information to the contrary, it is reasonable to assume that the probabilities for \(\omega_k\) in \(E\) should have the same relative magnitudes that they had before we learned that \(E\) had occurred. For this we require that \[m(\omega_k|E) = cm(\omega_k)\] for all \(\omega_k\) in \(E\), with \(c\) some positive constant. But we must also have \[\sum_E m(\omega_k|E) = c\sum_E m(\omega_k) = 1\ .\] Thus, \[c = \frac 1{\sum_E m(\omega_k)} = \frac 1{P(E)}\ .\] (Note that this requires us to assume that \(P(E) > 0\).) Thus, we will define \[m(\omega_k|E) = \frac {m(\omega_k)}{P(E)}\] for \(\omega_k\) in \(E\). We will call this new distribution the given \(E\). For a general event \(F\), this gives \[P(F|E) = \sum_{F \cap E} m(\omega_k|E) = \sum_{F \cap E}\frac {m(\omega_k)}{P(E)} = \frac {P(F \cap E)}{P(E)}\ .\]
We call \(P(F|E)\) the and compute it using the formula \[P(F|E) = \frac {P(F \cap E)}{P(E)}\ .\]
Let us return to the example of rolling a die. Recall that \(F\) is the event \(X = 6\), and \(E\) is the event \(X > 4\). Note that \(E \cap F\) is the event \(F\). So, the above formula gives \[\begin{aligned} P(F|E) & = & \frac {P(F \cap E)}{P(E)} \\ & = & \frac {1/6}{1/3} \\ & = & \frac 12\ ,\\\end{aligned}\] in agreement with the calculations performed earlier.
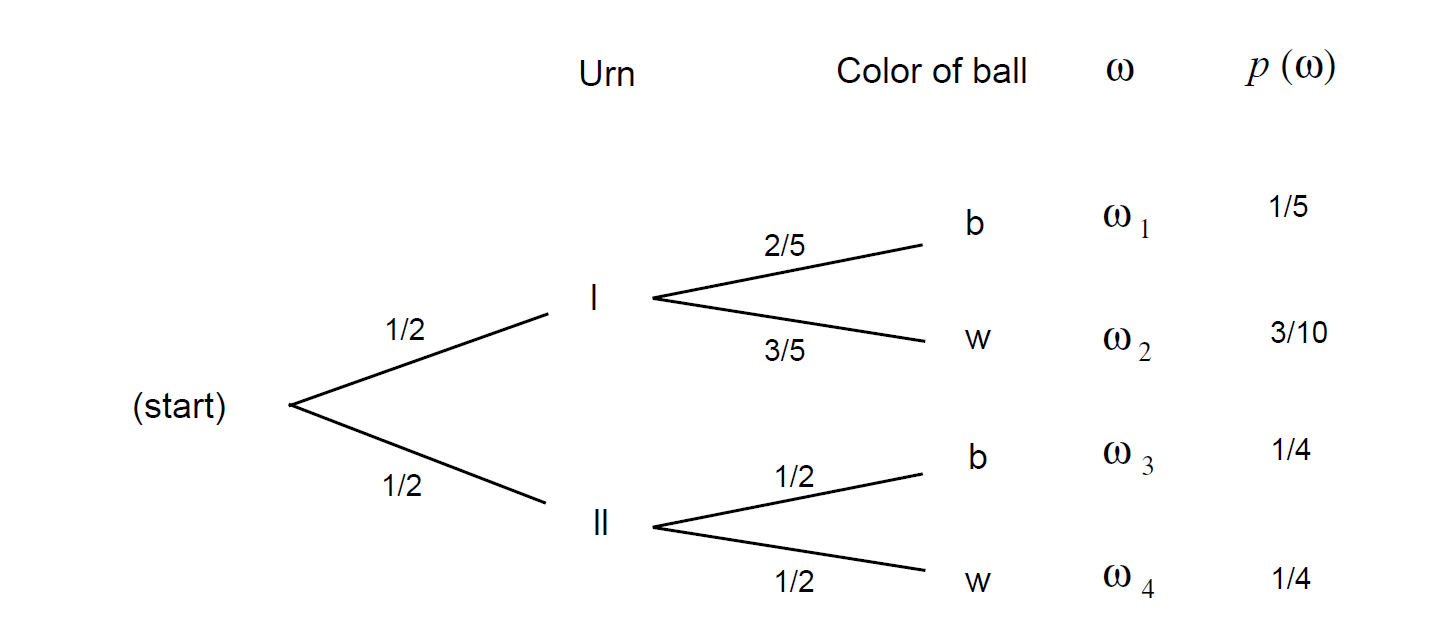
We have two urns, I and II. Urn I contains 2 black balls and 3 white balls. Urn II contains 1 black ball and 1 white ball. An urn is drawn at random and a ball is chosen at random from it. We can represent the sample space of this experiment as the paths through a tree as shown in Figure [fig 4.1]. The probabilities assigned to the paths are also shown.
Let \(B\) be the event “a black ball is drawn," and \(I\) the event “urn I is chosen." Then the branch weight 2/5, which is shown on one branch in the figure, can now be interpreted as the conditional probability \(P(B|I)\).
Suppose we wish to calculate \(P(I|B)\). Using the formula, we obtain
\[\begin{array}{rcl} P(I|B) & = & \frac {P(I \cap B)}{P(B)} \\ & = & \frac {P(I \cap B)}{P(B \cap I) + P(B \cap II)} \\ & = & \frac {1/5}{1/5 + 1/4} = \frac 49\ .\end{array}\]
Bayes Probabilities
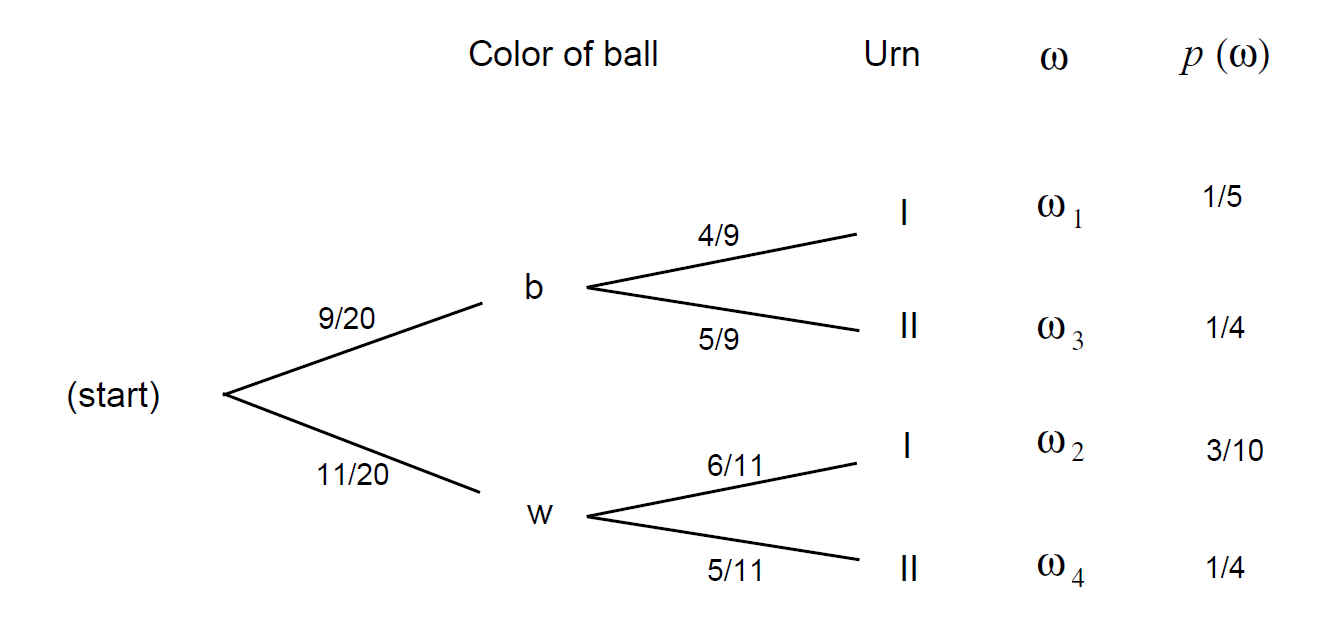
Our original tree measure gave us the probabilities for drawing a ball of a given color, given the urn chosen. We have just calculated the that a particular urn was chosen, given the color of the ball. Such an inverse probability is called a Bayes probability and may be obtained by a formula that we shall develop later. Bayes probabilities can also be obtained by simply constructing the tree measure for the two-stage experiment carried out in reverse order. We show this tree in Figure .
The paths through the reverse tree are in one-to-one correspondence with those in the forward tree, since they correspond to individual outcomes of the experiment, and so they are assigned the same probabilities. From the forward tree, we find that the probability of a black ball is \[\frac 12 \cdot \frac 25 + \frac 12 \cdot \frac 12 = \frac 9{20}\ .\]
The probabilities for the branches at the second level are found by simple division. For example, if \(x\) is the probability to be assigned to the top branch at the second level, we must have \[\frac 9{20} \cdot x = \frac 15\] or \(x = 4/9\). Thus, \(P(I|B) = 4/9\), in agreement with our previous calculations. The reverse tree then displays all of the inverse, or Bayes, probabilities.
We consider now a problem called the Monty Hall problem. This has long been a favorite problem but was revived by a letter from Craig Whitaker to Marilyn vos Savant for consideration in her column in Parade Magazine.1 Craig wrote:
Suppose you’re on Monty Hall’s You are given the choice of three doors, behind one door is a car, the others, goats. You pick a door, say 1, Monty opens another door, say 3, which has a goat. Monty says to you “Do you want to pick door 2?" Is it to your advantage to switch your choice of doors?
Solution
Marilyn gave a solution concluding that you should switch, and if you do, your probability of winning is 2/3. Several irate readers, some of whom identified themselves as having a PhD in mathematics, said that this is absurd since after Monty has ruled out one door there are only two possible doors and they should still each have the same probability 1/2 so there is no advantage to switching. Marilyn stuck to her solution and encouraged her readers to simulate the game and draw their own conclusions from this. We also encourage the reader to do this (see Exercise )).Other readers complained that Marilyn had not described the problem completely. In particular, the way in which certain decisions were made during a play of the game were not specified. This aspect of the problem will be discussed in Section 4.3. We will assume that the car was put behind a door by rolling a three-sided die which made all three choices equally likely. Monty knows where the car is, and always opens a door with a goat behind it. Finally, we assume that if Monty has a choice of doors (i.e., the contestant has picked the door with the car behind it), he chooses each door with probability 1/2. Marilyn clearly expected her readers to assume that the game was played in this manner.
As is the case with most apparent paradoxes, this one can be resolved through careful analysis. We begin by describing a simpler, related question. We say that a contestant is using the “stay" strategy if he picks a door, and, if offered a chance to switch to another door, declines to do so (i.e., he stays with his original choice). Similarly, we say that the contestant is using the “switch" strategy if he picks a door, and, if offered a chance to switch to another door, takes the offer. Now suppose that a contestant decides in advance to play the “stay" strategy. His only action in this case is to pick a door (and decline an invitation to switch, if one is offered). What is the probability that he wins a car? The same question can be asked about the “switch" strategy.
Using the “stay" strategy, a contestant will win the car with probability 1/3, since 1/3 of the time the door he picks will have the car behind it. On the other hand, if a contestant plays the “switch" strategy, then he will win whenever the door he originally picked does not have the car behind it, which happens 2/3 of the time.
This very simple analysis, though correct, does not quite solve the problem that Craig posed. Craig asked for the conditional probability that you win if you switch, given that you have chosen door 1 and that Monty has chosen door 3. To solve this problem, we set up the problem before getting this information and then compute the conditional probability given this information. This is a process that takes place in several stages; the car is put behind a door, the contestant picks a door, and finally Monty opens a door. Thus it is natural to analyze this using a tree measure. Here we make an additional assumption that if Monty has a choice of doors (i.e., the contestant has picked the door with the car behind it) then he picks each door with probability 1/2. The assumptions we have made determine the branch probabilities and these in turn determine the tree measure. The resulting tree and tree measure are shown in Figure ). It is tempting to reduce the tree’s size by making certain assumptions such as: “Without loss of generality, we will assume that the contestant always picks door 1." We have chosen not to make any such assumptions, in the interest of clarity.

Now the given information, namely that the contestant chose door 1 and Monty chose door 3, means only two paths through the tree are possible (see Figure )). For one of these paths, the car is behind door 1 and for the other it is behind door 2. The path with the car behind door 2 is twice as likely as the one with the car behind door 1. Thus the conditional probability is 2/3 that the car is behind door 2 and 1/3 that it is behind door 1, so if you switch you have a 2/3 chance of winning the car, as Marilyn claimed.

At this point, the reader may think that the two problems above are the same, since they have the same answers. Recall that we assumed in the original problem if the contestant chooses the door with the car, so that Monty has a choice of two doors, he chooses each of them with probability 1/2. Now suppose instead that in the case that he has a choice, he chooses the door with the larger number with probability 3/4. In the “switch" vs. “stay" problem, the probability of winning with the “switch" strategy is still 2/3. However, in the original problem, if the contestant switches, he wins with probability 4/7. The reader can check this by noting that the same two paths as before are the only two possible paths in the tree. The path leading to a win, if the contestant switches, has probability 1/3, while the path which leads to a loss, if the contestant switches, has probability 1/4.
Independent Events
It often happens that the knowledge that a certain event \(E\) has occurred has no effect on the probability that some other event \(F\) has occurred, that is, that \(P(F|E) = P(F)\). One would expect that in this case, the equation \(P(E|F) = P(E)\) would also be true. In fact (see Exercise [exer 4.1.1]), each equation implies the other. If these equations are true, we might say the \(F\) is of \(E\). For example, you would not expect the knowledge of the outcome of the first toss of a coin to change the probability that you would assign to the possible outcomes of the second toss, that is, you would not expect that the second toss depends on the first. This idea is formalized in the following definition of independent events.
Let \(E\) and \(F\) be two events. We say that they are if either 1) both events have positive probability and \[P(E|F) = P(E)\ {\rm and}\ P(F|E) = P(F)\ ,\] or 2) at least one of the events has probability 0.
As noted above, if both \(P(E)\) and \(P(F)\) are positive, then each of the above equations imply the other, so that to see whether two events are independent, only one of these equations must be checked (see Exercise 1).
The following theorem provides another way to check for independence.
Two events \(E\) and \(F\) are independent if and only if \[P(E\cap F) = P(E)P(F)\ .\]
- Proof
-
If either event has probability 0, then the two events are independent and the above equation is true, so the theorem is true in this case. Thus, we may assume that both events have positive probability in what follows. Assume that \(E\) and \(F\) are independent. Then \(P(E|F) = P(E)\), and so \[\begin{aligned} P(E\cap F) & = & P(E|F)P(F) \\ & = & P(E)P(F)\ .\end{aligned}\]
Assume next that \(P(E\cap F) = P(E)P(F)\). Then \[P(E|F) = \frac {P(E \cap F)}{P(F)} = P(E)\ .\] Also, \[P(F|E) = \frac {P(F \cap E)}{P(E)} = P(F)\ .\] Therefore, \(E\) and \(F\) are independent.
Suppose that we have a coin which comes up heads with probability \(p\), and tails with probability \(q\). Now suppose that this coin is tossed twice. Using a frequency interpretation of probability, it is reasonable to assign to the outcome \((H,H)\) the probability \(p^2\), to the outcome \((H, T)\) the probability \(pq\), and so on. Let \(E\) be the event that heads turns up on the first toss and \(F\) the event that tails turns up on the second toss. We will now check that with the above probability assignments, these two events are independent, as expected. We have
\[\begin{align}P(E) = p^2 + pq = p \\ P(F) = pq + q^2 = q \end{align}\] Finally \(P(E\cap F) = pq\), so \[P(E\cap F) = P(E)P(F)\].
It is often, but not always, intuitively clear when two events are independent. In Example , let \(A\) be the event “the first toss is a head" and \(B\) the event “the two outcomes are the same." Then \[P(B|A) = \frac {P(B \cap A)}{P(A)} = \frac {P\{\mbox {HH}\}}{P\{\mbox {HH,HT}\}} = \frac {1/4}{1/2} = \frac 12 = P(B).\] Therefore, \(A\) and \(B\) are independent, but the result was not so obvious.
Finally, let us give an example of two events that are not independent. In Example , let \(I\) be the event “heads on the first toss" and \(J\) the event “two heads turn up." Then \(P(I) = 1/2\) and \(P(J) = 1/4\). The event \(I \cap J\) is the event “heads on both tosses" and has probability \(1/4\). Thus, \(I\) and \(J\) are not independent since \(P(I)P(J) = 1/8 \ne P(I \cap J)\).
We can extend the concept of independence to any finite set of events \(A_1\), \(A_2\), …, \(A_n\).
A set of events \(\{A_1,\ A_2,\ \ldots,\ A_n\}\) is said to be mutually independent if for any subset \(\{A_i,\ A_j,\ldots,\ A_m\}\) of these events we have
\[P(A_i \cap A_j \cap\cdots\cap A_m) = P(A_i)P(A_j)\cdots P(A_m),\]
or equivalently, if for any sequence \(\bar A_1\), \(\bar A_2\), …, \(\bar A_n\) with \(\bar A_j = A_j\) or \(\tilde A_j\), \[P(\bar A_1 \cap \bar A_2 \cap\cdots\cap \bar A_n) = P(\bar A_1)P(\bar A_2)\cdots P(\bar A_n).\] (For a proof of the equivalence in the case \(n = 3\), see Exercise 33
Using this terminology, it is a fact that any sequence \((\mbox S,\mbox S,\mbox F,\mbox F, \mbox S, \dots,\mbox S)\) of possible outcomes of a Bernoulli trials process forms a sequence of mutually independent events.
It is natural to ask: If all pairs of a set of events are independent, is the whole set mutually independent? The answer is not necessarily and an example is given in Exercise 7
It is important to note that the statement \[P(A_1 \cap A_2 \cap \cdots \cap A_n) = P(A_1)P(A_2) \cdots P(A_n)\] does not imply that the events \(A_1\), \(A_2\), …, \(A_n\) are mutually independent (see Exercise 8).
Joint Distribution Functions and Independence of Random Variables
It is frequently the case that when an experiment is performed, several different quantities concerning the outcomes are investigated.
Suppose we toss a coin three times. The basic random variable \({\bar X}\) corresponding to this experiment has eight possible outcomes, which are the ordered triples consisting of H’s and T’s. We can also define the random variable \(X_i\), for \(i = 1, 2, 3\), to be the outcome of the \(i\)th toss. If the coin is fair, then we should assign the probability 1/8 to each of the eight possible outcomes. Thus, the distribution functions of \(X_1\), \(X_2\), and \(X_3\) are identical; in each case they are defined by \(m(H) = m(T) = 1/2\).
If we have several random variables \(X_1, X_2, \ldots, X_n\) which correspond to a given experiment, then we can consider the joint random variable \({\bar X} = (X_1, X_2, \ldots, X_n)\) defined by taking an outcome \(\omega\) of the experiment, and writing, as an \(n\)-tuple, the corresponding \(n\) outcomes for the random variables \(X_1, X_2, \ldots, X_n\). Thus, if the random variable \(X_i\) has, as its set of possible outcomes the set \(R_i\), then the set of possible outcomes of the joint random variable \({\bar X}\) is the Cartesian product of the \(R_i\)’s, i.e., the set of all \(n\)-tuples of possible outcomes of the \(X_i\)’s.
In the coin-tossing example above, let \(X_i\) denote the outcome of the \(i\)th toss. Then the joint random variable \({\bar X} = (X_1, X_2, X_3)\) has eight possible outcomes.
Suppose that we now define \(Y_i\), for \(i = 1, 2, 3\), as the number of heads which occur in the first \(i\) tosses. Then \(Y_i\) has \(\{0, 1, \ldots, i\}\) as possible outcomes, so at first glance, the set of possible outcomes of the joint random variable \({\bar Y} = (Y_1, Y_2, Y_3)\) should be the set \[\{(a_1, a_2, a_3)\ :\ 0 \le a_1 \le 1, 0 \le a_2 \le 2, 0 \le a_3 \le 3\}\ .\] However, the outcome \((1, 0, 1)\) cannot occur, since we must have \(a_1 \le a_2 \le a_3\). The solution to this problem is to define the probability of the outcome \((1, 0, 1)\) to be 0. In addition, we must have \(a_{i+1} - a_i \le 1\) for \(i = 1, 2\).
We now illustrate the assignment of probabilities to the various outcomes for the joint random variables \({\bar X}\) and \({\bar Y}\). In the first case, each of the eight outcomes should be assigned the probability 1/8, since we are assuming that we have a fair coin. In the second case, since \(Y_i\) has \(i+1\) possible outcomes, the set of possible outcomes has size 24. Only eight of these 24 outcomes can actually occur, namely the ones satisfying \(a_1 \le a_2 \le a_3\). Each of these outcomes corresponds to exactly one of the outcomes of the random variable \({\bar X}\), so it is natural to assign probability 1/8 to each of these. We assign probability 0 to the other 16 outcomes. In each case, the probability function is called a joint distribution function.
We collect the above ideas in a definition.
Let \(X_1, X_2, \ldots, X_n\) be random variables associated with an experiment. Suppose that the sample space (i.e., the set of possible outcomes) of \(X_i\) is the set \(R_i\). Then the joint random variable \({\bar X} = (X_1, X_2, \ldots, X_n)\) is defined to be the random variable whose outcomes consist of ordered \(n\)-tuples of outcomes, with the \(i\)th coordinate lying in the set \(R_i\). The sample space \(\Omega\) of \({\bar X}\) is the Cartesian product of the \(R_i\)’s: \[\Omega = R_1 \times R_2 \times \cdots \times R_n\ .\] The joint distribution function of \({\bar X}\) is the function which gives the probability of each of the outcomes of \({\bar X}\).
We now consider the assignment of probabilities in the above example. In the case of the random variable \({\bar X}\), the probability of any outcome \((a_1, a_2, a_3)\) is just the product of the probabilities \(P(X_i = a_i)\), for \(i = 1, 2, 3\). However, in the case of \({\bar Y}\), the probability assigned to the outcome \((1, 1, 0)\) is not the product of the probabilities \(P(Y_1 = 1)\), \(P(Y_2 = 1)\), and \(P(Y_3 = 0)\). The difference between these two situations is that the value of \(X_i\) does not affect the value of \(X_j\), if \(i \ne j\), while the values of \(Y_i\) and \(Y_j\) affect one another. For example, if \(Y_1 = 1\), then \(Y_2\) cannot equal 0. This prompts the next definition.
The random variables \(X_1\), \(X_2\), …, \(X_n\) are if \[\begin{aligned} &&P(X_1 = r_1, X_2 = r_2, \ldots, X_n = r_n) \\ && \;\;\;\;\;\;\;\;\;\;\;\;\;\;\; = P(X_1 = r_1) P(X_2 = r_2) \cdots P(X_n = r_n)\end{aligned}\] for any choice of \(r_1, r_2, \ldots, r_n\). Thus, if \(X_1,~X_2, \ldots,~X_n\) are mutually independent, then the joint distribution function of the random variable \[{\bar X} = (X_1, X_2, \ldots, X_n)\] is just the product of the individual distribution functions. When two randomvariables are mutually independent, we shall say more briefly that they are independent.
In a group of 60 people, the numbers who do or do not smoke and do or do not have cancer are reported as shown in Table .
|
Not smoke |
Smoke |
Total |
|
|---|---|---|---|
| Not cancer | 40 | 10 | 50 |
| Cancer |
7 |
3 |
10 |
| Totals | 47 | 13 | 60 |
Let \(\Omega\) be the sample space consisting of these 60 people. A person is chosen at random from the group. Let \(C(\omega) = 1\) if this person has cancer and 0 if not, and \(S(\omega) = 1\) if this person smokes and 0 if not. Then the joint distribution of \(\{C,S\}\) is given in Table .
| S | ||||
|
0 |
1 | |||
| 0 | 40/60 | 10/60 | ||
| C | ||||
| 1 |
7/60 |
3/60 |
For example \(P(C = 0, S = 0) = 40/60\), \(P(C = 0, S = 1) = 10/60\), and so forth. The distributions of the individual random variables are called The marginal distributions of \(C\) and \(S\) are: \[p_C = \pmatrix{ 0 & 1 \cr 50/60 & 10/60 \cr},\]
\[p_S = \pmatrix{ 0 & 1 \cr 47/60 & 13/60 \cr}.\] The random variables \(S\) and \(C\) are not independent, since \[\begin{aligned} P(C = 1,S = 1) &=& \frac 3{60} = .05\ , \\ P(C = 1)P(S = 1) &=& \frac {10}{60} \cdot \frac {13}{60} = .036\ .\end{aligned}\] Note that we would also see this from the fact that \[\begin{aligned} P(C = 1|S = 1) &=& \frac 3{13} = .23\ , \\ P(C = 1) &=& \frac 16 = .167\ .\end{aligned}\]
Independent Trials Processes
The study of random variables proceeds by considering special classes of random variables. One such class that we shall study is the class of[def 5.5]
A sequence of random variables \(X_1\), \(X_2\), …, \(X_n\) that are mutually independent and that have the same distribution is called a sequence of independent trials or an
Independent trials processes arise naturally in the following way. We have a single experiment with sample space \(R = \{r_1,r_2,\dots,r_s\}\) and a distribution function \[m_X = \pmatrix{ r_1 & r_2 & \cdots & r_s \cr p_1 & p_2 & \cdots & p_s\cr}\ .\]
We repeat this experiment \(n\) times. To describe this total experiment, we choose as sample space the space \[\Omega = R \times R \times\cdots\times R,\] consisting of all possible sequences \(\omega = (\omega_1,\omega_2,\dots,\omega_n)\) where the value of each \(\omega_j\) is chosen from \(R\). We assign a distribution function to be the \[m(\omega) = m(\omega_1)\cdot\ \ldots\ \cdot m(\omega_n)\ ,\] with \(m(\omega_j) = p_k\) when \(\omega_j = r_k\). Then we let \(X_j\) denote the \(j\)th coordinate of the outcome \((r_1, r_2, \ldots, r_n)\). The random variables \(X_1\), …, \(X_n\) form an independent trials process.
An experiment consists of rolling a die three times. Let \(X_i\) represent the outcome of the \(i\)th roll, for \(i = 1, 2, 3\). The common distribution function is \[m_i = \pmatrix{ 1 & 2 & 3 & 4 & 5 & 6 \cr 1/6 & 1/6 & 1/6 & 1/6 & 1/6 & 1/6 \cr}.\]
The sample space is \(R^3 = R \times R \times R\) with \(R = \{1,2,3,4,5,6\}\). If \(\omega = (1,3,6)\), then \(X_1(\omega) = 1\), \(X_2(\omega) = 3\), and \(X_3(\omega) = 6\) indicating that the first roll was a 1, the second was a 3, and the third was a 6. The probability assigned to any sample point is \[m(\omega) = \frac16 \cdot \frac16 \cdot \frac16 = \frac1{216}\ .\]
Consider next a Bernoulli trials process with probability \(p\) for success on each experiment. Let \(X_j(\omega) = 1\) if the \(j\)th outcome is success and \(X_j(\omega) = 0\) if it is a failure. Then \(X_1\), \(X_2\), …, \(X_n\) is an independent trials process. Each \(X_j\) has the same distribution function \[m_j = \pmatrix{ 0 & 1 \cr q & p \cr},\] where \(q = 1 - p\).
If \(S_n = X_1 + X_2 +\cdots + X_n\), then \[P(S_n = j) = {n \choose j} p^{j} q^{n - j}\ ,\] and \(S_n\) has, as distribution, the binomial distribution \(b(n,p,j)\).
Bayes’ Formula
In our examples, we have considered conditional probabilities of the following form: Given the outcome of the second stage of a two-stage experiment, find the probability for an outcome at the first stage. We have remarked that these probabilities are called
We return now to the calculation of more general Bayes probabilities. Suppose we have a set of events \(H_1,\) \(H_2\), …, \(H_m\) that are pairwise disjoint and such that the sample space \(\Omega\) satisfies the equation \[\Omega = H_1 \cup H_2 \cup\cdots\cup H_m\ .\] We call these events We also have an event \(E\) that gives us some information about which hypothesis is correct. We call this event
Before we receive the evidence, then, we have a set of \(P(H_1)\), \(P(H_2)\), …, \(P(H_m)\) for the hypotheses. If we know the correct hypothesis, we know the probability for the evidence. That is, we know \(P(E|H_i)\) for all \(i\). We want to find the probabilities for the hypotheses given the evidence. That is, we want to find the conditional probabilities \(P(H_i|E)\). These probabilities are called the
To find these probabilities, we write them in the form
\[P(H_i|E) = \frac{P(H_i \cap E)}{P(E)}\ . \label{eq 4.1}\]
We can calculate the numerator from our given information by \[P(H_i \cap E) = P(H_i)P(E|H_i)\ . \label{eq 4.2}\]
Since one and only one of the events \(H_1\), \(H_2\), …, \(H_m\) can occur, we can write the probability of \(E\) as
\[P(E) = P(H_1 \cap E) + P(H_2 \cap E) + \cdots + P(H_m \cap E)\ .\] Using Equation , the above expression can be seen to equal
\[P(H_1)P(E|H_1) + P(H_2)P(E|H_2) + \cdots + P(H_m)P(E|H_m) \ . \label{eq 4.3}\] Using ([eq 4.1]), ([eq 4.2]), and ([eq 4.3]) yields : \[P(H_i|E) = \frac{P(H_i)P(E|H_i)}{\sum_{k = 1}^m P(H_k)P(E|H_k)}\ .\]
Although this is a very famous formula, we will rarely use it. If the number of hypotheses is small, a simple tree measure calculation is easily carried out, as we have done in our examples. If the number of hypotheses is large, then we should use a computer.
Bayes probabilities are particularly appropriate for medical diagnosis. A doctor is anxious to know which of several diseases a patient might have. She collects evidence in the form of the outcomes of certain tests. From statistical studies the doctor can find the prior probabilities of the various diseases before the tests, and the probabilities for specific test outcomes, given a particular disease. What the doctor wants to know is the posterior probability for the particular disease, given the outcomes of the tests.
A doctor is trying to decide if a patient has one of three diseases \(d_1\), \(d_2\), or \(d_3\). Two tests are to be carried out, each of which results in a positive \((+)\) or a negative \((-)\) outcome. There are four possible test patterns \(+{}+\), \(+{}-\), \(-{}+\), and \(-{}-\). National records have indicated that, for 10,000 people having one of these three diseases, the distribution of diseases and test results are as in Table .
| Number having | |||||
| Disease | this disease |
++ |
+– |
–+ |
–– |
| \(d_{1}\) |
3215 |
2110 |
301 |
704 |
100 |
| \(d_{2}\) |
2125 |
396 |
132 |
1187 |
410 |
| \(d_{3}\) |
4660 |
510 |
3568 |
73 |
509 |
| Total | 10000 |
From this data, we can estimate the prior probabilities for each of the diseases and, given a particular disease, the probability of a particular test outcome. For example, the prior probability of disease \(d_1\) may be estimated to be \(3215/10{,}000 = .3215\). The probability of the test result \(+{}-\), given disease \(d_1\), may be estimated to be \(301/3215 = .094\).
We can now use Bayes’ formula to compute various posterior probabilities. The computer program Bayes computes these posterior probabilities. The results for this example are shown in Table .
| \(d_1\) | \(d_2\) | \(d_3\) | |
| ++ | .700 | .131 | .169 |
| +– | .075 | .033 | .892 |
|
–+ |
.358 | .604 | .038 |
|
–– |
.098 | .403 | .499 |
We note from the outcomes that, when the test result is \(++\), the disease \(d_1\) has a significantly higher probability than the other two. When the outcome is \(+-\), this is true for disease \(d_3\). When the outcome is \(-+\), this is true for disease \(d_2\). Note that these statements might have been guessed by looking at the data. If the outcome is \(--\), the most probable cause is \(d_3\), but the probability that a patient has \(d_2\) is only slightly smaller. If one looks at the data in this case, one can see that it might be hard to guess which of the two diseases \(d_2\) and \(d_3\) is more likely.
Our final example shows that one has to be careful when the prior probabilities are small.
A doctor gives a patient a test for a particular cancer. Before the results of the test, the only evidence the doctor has to go on is that 1 woman in 1000 has this cancer. Experience has shown that, in 99 percent of the cases in which cancer is present, the test is positive; and in 95 percent of the cases in which it is not present, it is negative. If the test turns out to be positive, what probability should the doctor assign to the event that cancer is present? An alternative form of this question is to ask for the relative frequencies of false positives and cancers.
We are given that \(\mbox{prior(cancer)} = .001\) and \(\mbox{prior(not\ cancer)} = .999\). We know also that \(P(+| \mbox{cancer}) = .99\), \(P(-|\mbox{cancer}) = .01\), \(P(+|\mbox{not\ cancer}) = .05\), and \(P(-|\mbox{not\ cancer}) = .95\). Using this data gives the result shown in Figure [fig 4.5].
We see now that the probability of cancer given a positive test has only increased from .001 to .019. While this is nearly a twenty-fold increase, the probability that the patient has the cancer is still small. Stated in another way, among the positive results, 98.1 percent are false positives, and 1.9 percent are cancers. When a group of second-year medical students was asked this question, over half of the students incorrectly guessed the probability to be greater than .5.
Historical Remarks
Conditional probability was used long before it was formally defined. Pascal and Fermat considered the problem of points: given that team A has won \(m\) games and team B has won \(n\) games, what is the probability that A will win the series? (See Exercises 40-42.) This is clearly a conditional probability problem.

In his book, Huygens gave a number of problems, one of which was:
Three gamblers, A, B and C, take 12 balls of which 4 are white and 8 black. They play with the rules that the drawer is blindfolded, A is to draw first, then B and then C, the winner to be the one who first draws a white ball. What is the ratio of their chances?2
From his answer it is clear that Huygens meant that each ball is replaced after drawing. However, John Hudde, the mayor of Amsterdam, assumed that he meant to sample without replacement and corresponded with Huygens about the difference in their answers. Hacking remarks that “Neither party can understand what the other is doing."3
By the time of de Moivre’s book, The Doctrine of Chances these distinctions were well understood. De Moivre defined independence and dependence as follows:
Two Events are independent, when they have no connexion one with the other, and that the happening of one neither forwards nor obstructs the happening of the other.
Two Events are dependent, when they are so connected together as that the Probability of either’s happening is altered by the happening of the other.4
De Moivre used sampling with and without replacement to illustrate that the probability that two independent events both happen is the product of their probabilities, and for dependent events that:
The Probability of the happening of two Events dependent, is the product of the Probability of the happening of one of them, by the Probability which the other will have of happening, when the first is considered as having happened; and the same Rule will extend to the happening of as many Events as may be assigned.5
The formula that we call Bayes’ formula, and the idea of computing the probability of a hypothesis given evidence, originated in a famous essay of Thomas Bayes. Bayes was an ordained minister in Tunbridge Wells near London. His mathematical interests led him to be elected to the Royal Society in 1742, but none of his results were published within his lifetime. The work upon which his fame rests, “An Essay Toward Solving a Problem in the Doctrine of Chances," was published in 1763, three years after his death.6 Bayes reviewed some of the basic concepts of probability and then considered a new kind of inverse probability problem requiring the use of conditional probability.
Bernoulli, in his study of processes that we now call Bernoulli trials, had proven his famous law of large numbers which we will study in Chapter 8. This theorem assured the experimenter that if he knew the probability \(p\) for success, he could predict that the proportion of successes would approach this value as he increased the number of experiments. Bernoulli himself realized that in most interesting cases you do not know the value of \(p\) and saw his theorem as an important step in showing that you could determine \(p\) by experimentation.
To study this problem further, Bayes started by assuming that the probability \(p\) for success is itself determined by a random experiment. He assumed in fact that this experiment was such that this value for \(p\) is equally likely to be any value between 0 and 1. Without knowing this value we carry out \(n\) experiments and observe \(m\) successes. Bayes proposed the problem of finding the conditional probability that the unknown probability \(p\) lies between \(a\) and \(b\). He obtained the answer: \[P(a \leq p < b | m {\mbox{\,\,successes\,\, in}}\,\,n \,\,{\mbox{trials}}) = \frac {\int_a^b x^m(1 - x)^{n - m}\,dx}{\int_0^1 x^m(1 - x)^{n - m}\,dx}\ .\]
Bayes clearly wanted to show that the conditional distribution function, given the outcomes of more and more experiments, becomes concentrated around the true value of \(p\). Thus, Bayes was trying to solve an The computation of the integrals was too difficult for exact solution except for small values of \(j\) and \(n\), and so Bayes tried approximate methods. His methods were not very satisfactory and it has been suggested that this discouraged him from publishing his results.
However, his paper was the first in a series of important studies carried out by Laplace, Gauss, and other great mathematicians to solve inverse problems. They studied this problem in terms of errors in measurements in astronomy. If an astronomer were to know the true value of a distance and the nature of the random errors caused by his measuring device he could predict the probabilistic nature of his measurements. In fact, however, he is presented with the inverse problem of knowing the nature of the random errors, and the values of the measurements, and wanting to make inferences about the unknown true value.
As Maistrov remarks, the formula that we have called Bayes’ formula does not appear in his essay. Laplace gave it this name when he studied these inverse problems.7 The computation of inverse probabilities is fundamental to statistics and has led to an important branch of statistics called Bayesian analysis, assuring Bayes eternal fame for his brief essay.
Exercises
Exercise \(\PageIndex{1}\)
Assume that \(E\) and \(F\) are two events with positive probabilities. Show that if \(P(E|F) = P(E)\), then \(P(F|E) = P(F)\).
Exercise \(\PageIndex{2}\)
A coin is tossed three times. What is the probability that exactly two heads occur, given that
- the first outcome was a head?
- the first outcome was a tail?
- the first two outcomes were heads?
- the first two outcomes were tails?
- the first outcome was a head and the third outcome was a head?
Exercise \(\PageIndex{3}\)
A die is rolled twice. What is the probability that the sum of the faces is greater than 7, given that
- the first outcome was a 4?
- the first outcome was greater than 3?
- the first outcome was a 1?
- the first outcome was less than 5?
Exercise \(\PageIndex{4}\)
A card is drawn at random from a deck of cards. What is the probability that
- it is a heart, given that it is red?
- it is higher than a 10, given that it is a heart? (Interpret J, Q, K, A as 11, 12, 13, 14.)
- it is a jack, given that it is red?
Exercise \(\PageIndex{5}\)
A coin is tossed three times. Consider the following events \(A\): Heads on the first toss. \(B\): Tails on the second. \(C\): Heads on the third toss. \(D\): All three outcomes the same (HHH or TTT). \(E\): Exactly one head turns up.
- Which of the following pairs of these events are independent? (1) \(A\), \(B\) (2) \(A\), \(D\) (3) \(A\), \(E\) (4) \(D\), \(E\)
- Which of the following triples of these events are independent? (1) \(A\), \(B\), \(C\) (2) \(A\), \(B\), \(D\) (3) \(C\), \(D\), \(E\)
Exercise \(\PageIndex{6}\)
From a deck of five cards numbered 2, 4, 6, 8, and 10, respectively, a card is drawn at random and replaced. This is done three times. What is the probability that the card numbered 2 was drawn exactly two times, given that the sum of the numbers on the three draws is 12?
Exercise \(\PageIndex{7}\)
A coin is tossed twice. Consider the following events. \(A\): Heads on the first toss. \(B\): Heads on the second toss. \(C\): The two tosses come out the same.
- Show that \(A\), \(B\), \(C\) are pairwise independent but not independent.
- Show that \(C\) is independent of \(A\) and \(B\) but not of \(A \cap B\).
Exercise \(\PageIndex{8}\)
Let \(\Omega = \{a,b,c,d,e,f\}\). Assume that \(m(a) = m(b) = 1/8\) and \(m(c) = m(d) = m(e) = m(f) = 3/16\). Let \(A\), \(B\), and \(C\) be the events \(A = \{d,e,a\}\), \(B = \{c,e,a\}\), \(C = \{c,d,a\}\). Show that \(P(A \cap B \cap C) = P(A)P(B)P(C)\) but no two of these events are independent.
Exercise \(\PageIndex{9}\)
What is the probability that a family of two children has
- two boys given that it has at least one boy?
- two boys given that the first child is a boy?
Exercise \(\PageIndex{10}\)
In Example 4.2, we used the Life Table (see Appendix C) to compute a conditional probability. The number 93,753 in the table, corresponding to 40-year-old males, means that of all the males born in the United States in 1950, 93.753% were alive in 1990. Is it reasonable to use this as an estimate for the probability of a male, born this year, surviving to age 40?
Exercise \(\PageIndex{11}\)
Simulate the Monty Hall problem. Carefully state any assumptions that you have made when writing the program. Which version of the problem do you think that you are simulating?
Exercise \(\PageIndex{12}\)
In Example 4.17, how large must the prior probability of cancer be to give a posterior probability of .5 for cancer given a positive test?
Exercise \(\PageIndex{13}\)
Two cards are drawn from a bridge deck. What is the probability that the second card drawn is red?
Exercise \(\PageIndex{14}\)
If \(P(\tilde B) = 1/4\) and \(P(A|B) = 1/2\), what is \(P(A \cap B)\)?
Exercise \(\PageIndex{15}\)
- What is the probability that your bridge partner has exactly two aces, given that she has at least one ace?
- What is the probability that your bridge partner has exactly two aces, given that she has the ace of spades?
Exercise \(\PageIndex{16}\)
Prove that for any three events \(A\), \(B\), \(C\), each having positive probability, and with the property that \(P(A \cap B) > 0\), \[P(A \cap B \cap C) = P(A)P(B|A)P(C|A \cap B)\ .\]
Exercise \(\PageIndex{17}\)
Prove that if \(A\) and \(B\) are independent so are
- \(A\) and \(\tilde B\).
- \(\tilde A\) and \(\tilde B\).
Exercise \(\PageIndex{18}\)
A doctor assumes that a patient has one of three diseases \(d_1\), \(d_2\), or \(d_3\). Before any test, he assumes an equal probability for each disease. He carries out a test that will be positive with probability .8 if the patient has \(d_1\), .6 if he has disease \(d_2\), and .4 if he has disease \(d_3\). Given that the outcome of the test was positive, what probabilities should the doctor now assign to the three possible diseases?
Exercise \(\PageIndex{19}\)
In a poker hand, John has a very strong hand and bets 5 dollars. The probability that Mary has a better hand is .04. If Mary had a better hand she would raise with probability .9, but with a poorer hand she would only raise with probability .1. If Mary raises, what is the probability that she has a better hand than John does?
Exercise \(\PageIndex{20}\)
The Polya urn model for contagion is as follows: We start with an urn which contains one white ball and one black ball. At each second we choose a ball at random from the urn and replace this ball and add one more of the color chosen. Write a program to simulate this model, and see if you can make any predictions about the proportion of white balls in the urn after a large number of draws. Is there a tendency to have a large fraction of balls of the same color in the long run?
Exercise \(\PageIndex{21}\)
It is desired to find the probability that in a bridge deal each player receives an ace. A student argues as follows. It does not matter where the first ace goes. The second ace must go to one of the other three players and this occurs with probability 3/4. Then the next must go to one of two, an event of probability 1/2, and finally the last ace must go to the player who does not have an ace. This occurs with probability 1/4. The probability that all these events occur is the product \((3/4)(1/2)(1/4) = 3/32\). Is this argument correct?
Exercise \(\PageIndex{22}\)
One coin in a collection of 65 has two heads. The rest are fair. If a coin, chosen at random from the lot and then tossed, turns up heads 6 times in a row, what is the probability that it is the two-headed coin?
Exercise \(\PageIndex{23}\)
You are given two urns and fifty balls. Half of the balls are white and half are black. You are asked to distribute the balls in the urns with no restriction placed on the number of either type in an urn. How should you distribute the balls in the urns to maximize the probability of obtaining a white ball if an urn is chosen at random and a ball drawn out at random? Justify your answer.
Exercise \(\PageIndex{24}\)
A fair coin is thrown \(n\) times. Show that the conditional probability of a head on any specified trial, given a total of \(k\) heads over the \(n\) trials, is \(k/n\) \((k > 0)\).
Exercise \(\PageIndex{25}\)
(Johnsonbough8) A coin with probability \(p\) for heads is tossed \(n\) times. Let \(E\) be the event “a head is obtained on the first toss’ and \(F_k\) the event ‘exactly \(k\) heads are obtained." For which pairs \((n,k)\) are \(E\) and \(F_k\) independent?
Exercise \(\PageIndex{26}\)
Suppose that \(A\) and \(B\) are events such that \(P(A|B) = P(B|A)\) and \(P(A \cup B) = 1\) and \(P(A \cap B) > 0\). Prove that \(P(A) > 1/2\).
Exercise \(\PageIndex{27}\)
(Chung9) In London, half of the days have some rain. The weather forecaster is correct 2/3 of the time, i.e., the probability that it rains, given that she has predicted rain, and the probability that it does not rain, given that she has predicted that it won’t rain, are both equal to 2/3. When rain is forecast, Mr. Pickwick takes his umbrella. When rain is not forecast, he takes it with probability 1/3. Find
- the probability that Pickwick has no umbrella, given that it rains.
- the probability that he brings his umbrella, given that it doesn’t rain.
Exercise \(\PageIndex{28}\)
Probability theory was used in a famous court case: 10 In this case a purse was snatched from an elderly person in a Los Angeles suburb. A couple seen running from the scene were described as a black man with a beard and a mustache and a blond girl with hair in a ponytail. Witnesses said they drove off in a partly yellow car. Malcolm and Janet Collins were arrested. He was black and though clean shaven when arrested had evidence of recently having had a beard and a mustache. She was blond and usually wore her hair in a ponytail. They drove a partly yellow Lincoln. The prosecution called a professor of mathematics as a witness who suggested that a conservative set of probabilities for the characteristics noted by the witnesses would be as shown in Table
Table : Collins case probabilities
| man with mustache | 1/4 |
| girl with blond hair | 1/3 |
| girl with ponytail | 1/10 |
| black man with beard | 1/10 |
| interracial couple in a car | 1/1000 |
| partly yellow car | 1/10 |
The prosecution then argued that the probability that all of these characteristics are met by a randomly chosen couple is the product of the probabilities or 1/12,000,000, which is very small. He claimed this was proof beyond a reasonable doubt that the defendants were guilty. The jury agreed and handed down a verdict of guilty of second-degree robbery.
If you were the lawyer for the Collins couple how would you have countered the above argument? (The appeal of this case is discussed in Exercise [sec 5.1].[exer 9.2.23].)
Exercise \(\PageIndex{29}\)
A student is applying to Harvard and Dartmouth. He estimates that he has a probability of .5 of being accepted at Dartmouth and .3 of being accepted at Harvard. He further estimates the probability that he will be accepted by both is .2. What is the probability that he is accepted by Dartmouth if he is accepted by Harvard? Is the event “accepted at Harvard" independent of the event “accepted at Dartmouth"?
Exercise \(\PageIndex{30}\)
Luxco, a wholesale lightbulb manufacturer, has two factories. Factory A sells bulbs in lots that consists of 1000 regular and 2000 bulbs each. Random sampling has shown that on the average there tend to be about 2 bad regular bulbs and 11 bad softglow bulbs per lot. At factory B the lot size is reversed—there are 2000 regular and 1000 softglow per lot—and there tend to be 5 bad regular and 6 bad softglow bulbs per lot.
The manager of factory A asserts, “We’re obviously the better producer; our bad bulb rates are .2 percent and .55 percent compared to B’s .25 percent and .6 percent. We’re better at both regular and softglow bulbs by half of a tenth of a percent each."
“Au contraire," counters the manager of B, “each of our 3000 bulb lots contains only 11 bad bulbs, while A’s 3000 bulb lots contain 13. So our .37 percent bad bulb rate beats their .43 percent."
Who is right?
Exercise \(\PageIndex{31}\)
Using the Life Table for 1981 given in Appendix C, find the probability that a male of age 60 in 1981 lives to age 80. Find the same probability for a female.
Exercise \(\PageIndex{32}\)
- There has been a blizzard and Helen is trying to drive from Woodstock to Tunbridge, which are connected like the top graph in Figure [fig 4.51]. Here \(p\) and \(q\) are the probabilities that the two roads are passable. What is the probability that Helen can get from Woodstock to Tunbridge?
- Now suppose that Woodstock and Tunbridge are connected like the middle graph in Figure [fig 4.51]. What now is the probability that she can get from \(W\) to \(T\)? Note that if we think of the roads as being components of a system, then in (a) and (b) we have computed the of a system whose components are (a) and (b)
- Now suppose \(W\) and \(T\) are connected like the bottom graph in Figure [fig 4.51]. Find the probability of Helen’s getting from \(W\) to \(T\). : If the road from \(C\) to \(D\) is impassable, it might as well not be there at all; if it is passable, then figure out how to use part (b) twice.

Exercise \(\PageIndex{33}\)
Let \(A_1\), \(A_2\), and \(A_3\) be events, and let \(B_i\) represent either \(A_i\) or its complement \(\tilde A_i\). Then there are eight possible choices for the triple \((B_1, B_2, B_3)\). Prove that the events \(A_1\), \(A_2\), \(A_3\) are independent if and only if \[P(B_1 \cap B_2 \cap B_3) = P(B_1)P(B_2)P(B_3)\ ,\] for all eight of the possible choices for the triple \((B_1, B_2, B_3)\).
Exercise \(\PageIndex{34}\)
Four women, A, B, C, and D, check their hats, and the hats are returned in a random manner. Let \(\Omega\) be the set of all possible permutations of A, B, C, D. Let \(X_j = 1\) if the \(j\)th woman gets her own hat back and 0 otherwise. What is the distribution of \(X_j\)? Are the \(X_i\)’s mutually independent?
Exercise \(\PageIndex{35}\)
A box has numbers from 1 to 10. A number is drawn at random. Let \(X_1\) be the number drawn. This number is replaced, and the ten numbers mixed. A second number \(X_2\) is drawn. Find the distributions of \(X_1\) and \(X_2\). Are \(X_1\) and \(X_2\) independent? Answer the same questions if the first number is not replaced before the second is drawn.
Exercise \(\PageIndex{36}\)
A die is thrown twice. Let \(X_1\) and \(X_2\) denote the outcomes. Define \(X = \min(X_1, X_2)\). Find the distribution of \(X\).
Exercise \(\PageIndex{37}\)
Given that \(P(X = a) = r\), \(P(\max(X,Y) = a) = s\), and \(P(\min(X,Y) = a) = t\), show that you can determine \(u = P(Y = a)\) in terms of \(r\), \(s\), and \(t\).
Exercise \(\PageIndex{38}\)
A fair coin is tossed three times. Let \(X\) be the number of heads that turn up on the first two tosses and \(Y\) the number of heads that turn up on the third toss. Give the distribution of
- the random variables \(X\) and \(Y\).
- the random variable \(Z = X + Y\).
- the random variable \(W = X - Y\).
Exercise \(\PageIndex{39}\)
Assume that the random variables \(X\) and \(Y\) have the joint distribution given in Table .
| \(Y\) | ||||||
| -1 | 0 | 1 | 2 | |||
| \(X\) | -1 | 0 | 1/36 | 1/6 | 1/12 | |
| 0 | 1/18 | 0 | 1/18 | 0 | ||
| 1 | 0 | 1/36 | 1/6 | 1/12 | ||
| 2 | 1/12 | 0 | 1/12 | 1/6 |
- What is \(P(X \geq 1\ \mbox {and\ } Y \leq 0)\)?
- What is the conditional probability that \(Y \leq 0\) given that \(X = 2\)?
- Are \(X\) and \(Y\) independent?
- What is the distribution of \(Z = XY\)?
Exercise \(\PageIndex{40}\)
In the , discussed in the historical remarks in Section 3.2, two players, A and B, play a series of points in a game with player A winning each point with probability \(p\) and player B winning each point with probability \(q = 1 - p\). The first player to win \(N\) points wins the game. Assume that \(N = 3\). Let \(X\) be a random variable that has the value 1 if player A wins the series and 0 otherwise. Let \(Y\) be a random variable with value the number of points played in a game. Find the distribution of \(X\) and \(Y\) when \(p = 1/2\). Are \(X\) and \(Y\) independent in this case? Answer the same questions for the case \(p = 2/3\).
Exercise \(\PageIndex{41}\)
The letters between Pascal and Fermat, which are often credited with having started probability theory, dealt mostly with the described in Exercise [exer 5.1.11]. Pascal and Fermat considered the problem of finding a fair division of stakes if the game must be called off when the first player has won \(r\) games and the second player has won \(s\) games, with \(r < N\) and \(s < N\). Let \(P(r,s)\) be the probability that player A wins the game if he has already won \(r\) points and player B has won \(s\) points. Then
- \(P(r,N) = 0\) if \(r < N\),
- \(P(N,s) = 1\) if \(s < N\),
- \(P(r,s) = pP(r + 1,s) + qP(r,s + 1)\) if \(r < N\) and \(s < N\);
and (1), (2), and (3) determine \(P(r,s)\) for \(r \leq N\) and \(s \leq N\). Pascal used these facts to find \(P(r,s)\) by working backward: He first obtained \(P(N - 1,j)\) for \(j = N - 1\), \(N - 2\), …, 0; then, from these values, he obtained \(P(N - 2,j)\) for \(j = N - 1\), \(N - 2\), …, 0 and, continuing backward, obtained all the values \(P(r,s)\). Write a program to compute \(P(r,s)\) for given \(N\), \(a\), \(b\), and \(p\). : Follow Pascal and you will be able to run \(N = 100\); use recursion and you will not be able to run \(N = 20\).
Exercise \(\PageIndex{42}\)
Fermat solved the problem of points (see Exercise 5.11) as follows: He realized that the problem was difficult because the possible ways the play might go are not equally likely. For example, when the first player needs two more games and the second needs three to win, two possible ways the series might go for the first player are WLW and LWLW. These sequences are not equally likely. To avoid this difficulty, Fermat extended the play, adding fictitious plays so that the series went the maximum number of games needed (four in this case). He obtained equally likely outcomes and used, in effect, the Pascal triangle to calculate \(P(r,s)\). Show that this leads to a for \(P(r,s)\) even for the case \(p \ne 1/2\).
Exercise \(\PageIndex{43}\)
The Yankees are playing the Dodgers in a world series. The Yankees win each game with probability .6. What is the probability that the Yankees win the series? (The series is won by the first team to win four games.)
Exercise \(\PageIndex{44}\)
C. L. Anderson11 has used Fermat’s argument for the problem of points to prove the following result due to J. G. Kingston. You are playing the game of points (see Exercise 40) but, at each point, when you serve you win with probability \(p\), and when your opponent serves you win with probability \(\bar{p}\). You will serve first, but you can choose one of the following two conventions for serving: for the first convention you alternate service (tennis), and for the second the person serving continues to serve until he loses a point and then the other player serves (racquetball). The first player to win \(N\) points wins the game. The problem is to show that the probability of winning the game is the same under either convention.
- Show that, under either convention, you will serve at most \(N\) points and your opponent at most \(N - 1\) points.
- Extend the number of points to \(2N - 1\) so that you serve \(N\) points and your opponent serves \(N - 1\). For example, you serve any additional points necessary to make \(N\) serves and then your opponent serves any additional points necessary to make him serve \(N - 1\) points. The winner is now the person, in the extended game, who wins the most points. Show that playing these additional points has not changed the winner.
- Show that (a) and (b) prove that you have the same probability of winning the game under either convention.
Exercise \(\PageIndex{45}\)
In the previous problem, assume that \(p = 1 - \bar{p}\).
- Show that under either service convention, the first player will win more often than the second player if and only if \(p > .5\).
- In volleyball, a team can only win a point while it is serving. Thus, any individual “play" either ends with a point being awarded to the serving team or with the service changing to the other team. The first team to win \(N\) points wins the game. (We ignore here the additional restriction that the winning team must be ahead by at least two points at the end of the game.) Assume that each team has the same probability of winning the play when it is serving, i.e., that \(p = 1 - \bar{p}\). Show that in this case, the team that serves first will win more than half the time, as long as \(p > 0\). (If \(p = 0\), then the game never ends.) : Define \(p'\) to be the probability that a team wins the next point, given that it is serving. If we write \(q = 1 - p\), then one can show that \[p' = \frac p{1-q^2}\ .\] If one now considers this game in a slightly different way, one can see that the second service convention in the preceding problem can be used, with \(p\) replaced by \(p'\).
Exercise \(\PageIndex{46}\)
A poker hand consists of 5 cards dealt from a deck of 52 cards. Let \(X\) and \(Y\) be, respectively, the number of aces and kings in a poker hand. Find the joint distribution of \(X\) and \(Y\).
Exercise \(\PageIndex{47}\)
Let \(X_1\) and \(X_2\) be independent random variables and let \(Y_1 = \phi_1(X_1)\) and \(Y_2 = \phi_2(X_2)\).
- Show that \[P(Y_1 = r, Y_2 = s) = \sum_{\phi_1(a) = r \atop \phi_2(b) = s} P(X_1 = a, X_2 = b)\ .\]
- Using (a), show that \(P(Y_1 = r, Y_2 = s) = P(Y_1 = r)P(Y_2 = s)\) so that \(Y_1\) and \(Y_2\) are independent.
Exercise \(\PageIndex{48}\)
Let \(\Omega\) be the sample space of an experiment. Let \(E\) be an event with \(P(E) > 0\) and define \(m_E(\omega)\) by \(m_E(\omega) = m(\omega|E)\). Prove that \(m_E(\omega)\) is a distribution function on \(E\), that is, that \(m_E(\omega) \geq 0\) and that \(\sum_{\omega\in\Omega} m_E(\omega) = 1\). The function \(m_E\) is called the
Exercise \(\PageIndex{49}\)
You are given two urns each containing two biased coins. The coins in urn I come up heads with probability \(p_1\), and the coins in urn II come up heads with probability \(p_2 \ne p_1\). You are given a choice of (a) choosing an urn at random and tossing the two coins in this urn or (b) choosing one coin from each urn and tossing these two coins. You win a prize if both coins turn up heads. Show that you are better off selecting choice (a).
Exercise \(\PageIndex{50}\)
Prove that, if \(A_1\), \(A_2\), …, \(A_n\) are independent events defined on a sample space \(\Omega\) and if \(0 < P(A_j) < 1\) for all \(j\), then \(\Omega\) must have at least \(2^n\) points.
Exercise \(\PageIndex{51}\)
Prove that if \[P(A|C) \geq P(B|C) \mbox{\,\,and\,\,} P(A|\tilde C) \geq P(B|\tilde C)\ ,\] then \(P(A) \geq P(B)\).
Exercise \(\PageIndex{52}\)
A coin is in one of \(n\) boxes. The probability that it is in the \(i\)th box is \(p_i\). If you search in the \(i\)th box and it is there, you find it with probability \(a_i\). Show that the probability \(p\) that the coin is in the \(j\)th box, given that you have looked in the \(i\)th box and not found it, is \[p = \left \{ \matrix{ p_j/(1-a_ip_i),&\,\,\, \mbox{if} \,\,\, j \ne i,\cr (1 - a_i)p_i/(1 - a_ip_i),&\,\,\,\mbox{if} \,\, j = i.\cr}\right.\]
Exercise \(\PageIndex{53}\)
George Wolford has suggested the following variation on the Linda problem (see Exercise 1.2.25). The registrar is carrying John and Mary’s registration cards and drops them in a puddle. When he pickes them up he cannot read the names but on the first card he picked up he can make out Mathematics 23 and Government 35, and on the second card he can make out only Mathematics 23. He asks you if you can help him decide which card belongs to Mary. You know that Mary likes government but does not like mathematics. You know nothing about John and assume that he is just a typical Dartmouth student. From this you estimate: .1in \[\begin{array}{ll} P(\mbox {Mary\ takes\ Government\ 35}) &= .5\ , \\ P(\mbox {Mary\ takes\ Mathematics\ 23}) &= .1\ , \\ P(\mbox {John\ takes\ Government\ 35}) &= .3\ , \\ P(\mbox {John\ takes\ Mathematics\ 23}) &= .2\ . \end{array}\] .1in Assume that their choices for courses are independent events. Show that the card with Mathematics 23 and Government 35 showing is more likely to be Mary’s than John’s. The conjunction fallacy referred to in the Linda problem would be to assume that the event “Mary takes Mathematics 23 and Government 35" is more likely than the event “Mary takes Mathematics 23." Why are we not making this fallacy here?
Exercise \(\PageIndex{54}\)
(Suggested by Eisenberg and Ghosh12) A deck of playing cards can be described as a Cartesian product \[\mbox{Deck} = \mbox{Suit} \times \mbox{Rank}\ ,\] where \(\mbox{Suit} = \{\clubsuit,\diamondsuit,\heartsuit,\spadesuit\}\) and \(\mbox{Rank} = \{2,3,\dots,10,{\mbox J},{\mbox Q},{\mbox K},{\mbox A}\}\). This just means that every card may be thought of as an ordered pair like \((\diamondsuit,2)\). By a we mean any event \(A\) contained in Deck which is described in terms of Suit alone. For instance, if \(A\) is “the suit is red," then \[A = \{\diamondsuit,\heartsuit\} \times \mbox{Rank}\ ,\] so that \(A\) consists of all cards of the form \((\diamondsuit,r)\) or \((\heartsuit,r)\) where \(r\) is any rank. Similarly, a is any event described in terms of rank alone.
- Show that if \(A\) is any suit event and \(B\) any rank event, then \(A\) and \(B\) are (We can express this briefly by saying that suit and rank are independent.)
- Throw away the ace of spades. Show that now no nontrivial (i.e., neither empty nor the whole space) suit event \(A\) is independent of any nontrivial rank event \(B\). : Here independence comes down to \[c/51 = (a/51) \cdot (b/51)\ ,\] where \(a\), \(b\), \(c\) are the respective sizes of \(A\), \(B\) and \(A \cap B\). It follows that 51 must divide \(ab\), hence that 3 must divide one of \(a\) and \(b\), and 17 the other. But the possible sizes for suit and rank events preclude this.
- Show that the deck in (b) nevertheless does have pairs \(A\), \(B\) of nontrivial independent events. : Find 2 events \(A\) and \(B\) of sizes 3 and 17, respectively, which intersect in a single point.
- Add a joker to a full deck. Show that now there is no pair \(A\), \(B\) of nontrivial independent events. : See the hint in (b); 53 is prime.
The following problems are suggested by Stanley Gudder in his article “Do Good Hands Attract?"13 He says that event \(A\) event \(B\) if \(P(B|A) > P(B)\) and \(B\) if \(P(B|A) < P(B)\).
Exercise \(\PageIndex{55}\)
Let \(R_i\) be the event that the \(i\)th player in a poker game has a royal flush. Show that a royal flush (A,K,Q,J,10 of one suit) attracts another royal flush, that is \(P(R_2|R_1) > P(R_2)\). Show that a royal flush repels full houses.
Exercise \(\PageIndex{56}\)
Prove that \(A\) attracts \(B\) if and only if \(B\) attracts \(A\). Hence we can say that \(A\) and \(B\) are if \(A\) attracts \(B\).
Exercise \(\PageIndex{57}\)
Prove that \(A\) neither attracts nor repels \(B\) if and only if \(A\) and \(B\) are independent.
Exercise \(\PageIndex{58}\)
Prove that \(A\) and \(B\) are mutually attractive if and only if \(P(B|A) > P(B|\tilde A)\).
Exercise \(\PageIndex{59}\)
Prove that if \(A\) attracts \(B\), then \(A\) repels \(\tilde B\).
Exercise \(\PageIndex{60}\)
Prove that if \(A\) attracts both \(B\) and \(C\), and \(A\) repels \(B \cap C\), then \(A\) attracts \(B \cup C\). Is there any example in which \(A\) attracts both \(B\) and \(C\) and repels \(B \cup C\)?
Exercise \(\PageIndex{61}\)
Prove that if \(B_1\), \(B_2\), …, \(B_n\) are mutually disjoint and collectively exhaustive, and if \(A\) attracts some \(B_i\), then \(A\) must repel some \(B_j\).
Exercise \(\PageIndex{62}\)
- Suppose that you are looking in your desk for a letter from some time ago. Your desk has eight drawers, and you assess the probability that it is in any particular drawer is 10% (so there is a 20% chance that it is not in the desk at all). Suppose now that you start searching systematically through your desk, one drawer at a time. In addition, suppose that you have not found the letter in the first \(i\) drawers, where \(0 \le i \le 7\). Let \(p_i\) denote the probability that the letter will be found in the next drawer, and let \(q_i\) denote the probability that the letter will be found in some subsequent drawer (both \(p_i\) and \(q_i\) are conditional probabilities, since they are based upon the assumption that the letter is not in the first \(i\) drawers). Show that the \(p_i\)’s increase and the \(q_i\)’s decrease. (This problem is from Falk et al.14)
- The following data appeared in an article in the Wall Street Journal.15 For the ages 20, 30, 40, 50, and 60, the probability of a woman in the U.S. developing cancer in the next ten years is 0.5%, 1.2%, 3.2%, 6.4%, and 10.8%, respectively. At the same set of ages, the probability of a woman in the U.S. eventually developing cancer is 39.6%, 39.5%, 39.1%, 37.5%, and 34.2%, respectively. Do you think that the problem in part (a) gives an explanation for these data?
Exercise \(\PageIndex{63}\)
Here are two variations of the Monty Hall problem that are discussed by Granberg.16
- Suppose that everything is the same except that Monty forgot to find out in advance which door has the car behind it. In the spirit of “the show must go on," he makes a guess at which of the two doors to open and gets lucky, opening a door behind which stands a goat. Now should the contestant switch?
- You have observed the show for a long time and found that the car is put behind door A 45% of the time, behind door B 40% of the time and behind door C 15% of the time. Assume that everything else about the show is the same. Again you pick door A. Monty opens a door with a goat and offers to let you switch. Should you? Suppose you knew in advance that Monty was going to give you a chance to switch. Should you have initially chosen door A?