
3.1: Permutations
- Page ID
- 3130

Many problems in probability theory require that we count the number of ways that a particular event can occur. For this, we study the topics of permutations and combinations. We consider permutations in this section and combinations in the next section. Before discussing permutations, it is useful to introduce a general counting technique that will enable us to solve a variety of counting problems, including the problem of counting the number of possible permutations of \(n\) objects.
Counting Problems
Consider an experiment that takes place in several stages and is such that the number of outcomes \(m\) at the \(n\)th stage is independent of the outcomes of the previous stages. The number \(m\) may be different for different stages. We want to count the number of ways that the entire experiment can be carried out.
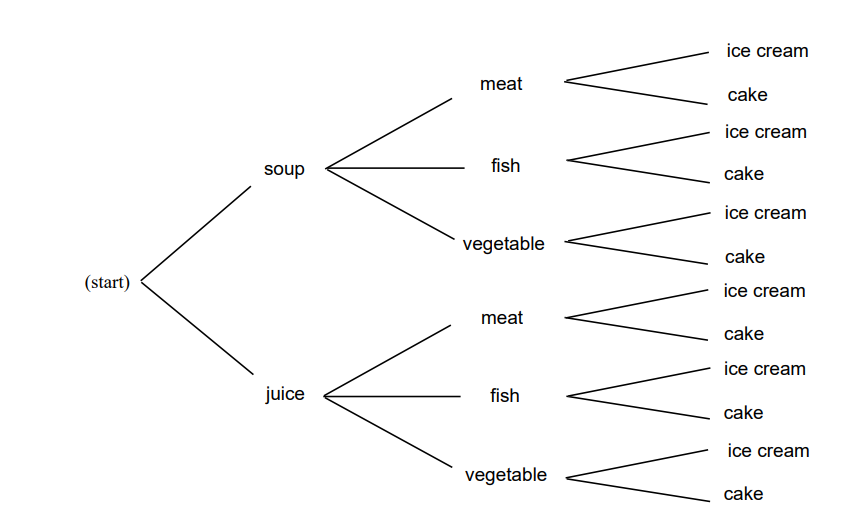
You are eating at Émile’s restaurant and the waiter informs you that you have (a) two choices for appetizers: soup or juice; (b) three for the main course: a meat, fish, or vegetable dish; and (c) two for dessert: ice cream or cake. How many possible choices do you have for your complete meal? We illustrate the possible meals by a tree diagram shown in Figure \(\PageIndex{1}\) Your menu is decided in three stages—at each stage the number of possible choices does not depend on what is chosen in the previous stages: two choices at the first stage, three at the second, and two at the third. From the tree diagram we see that the total number of choices is the product of the number of choices at each stage. In this examples we have \(2 \cdot 3 \cdot 2 = 12\) possible menus. Our menu example is an example of the following general counting technique.
A Counting Technique
A task is to be carried out in a sequence of \(r\) stages. There are \(n_1\) ways to carry out the first stage; for each of these \(n_1\) ways, there are \(n_2\) ways to carry out the second stage; for each of these \(n_2\) ways, there are \(n_3\) ways to carry out the third stage, and so forth. Then the total number of ways in which the entire task can be accomplished is given by the product \(N = n_1 \cdot n_2 \cdot \dots \cdot n_r\).
Tree Diagrams
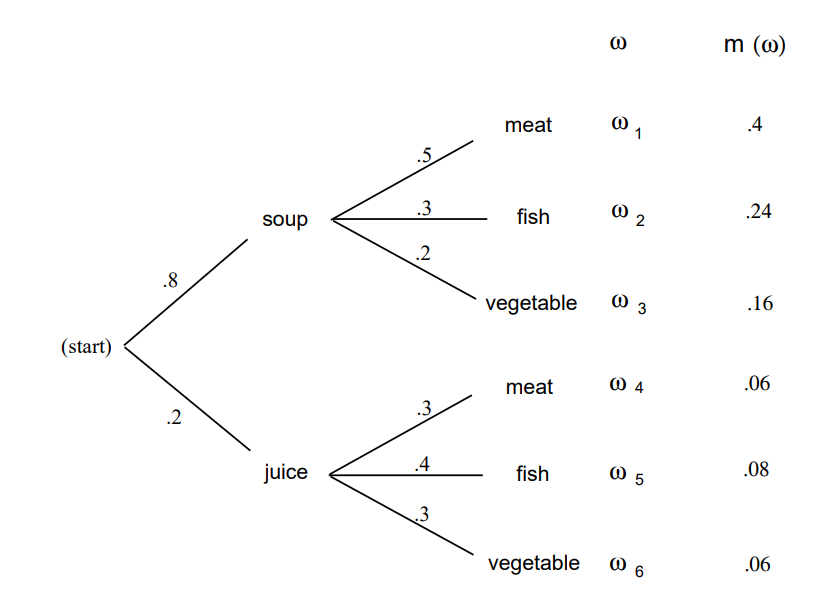
It will often be useful to use a tree diagram when studying probabilities of events relating to experiments that take place in stages and for which we are given the probabilities for the outcomes at each stage. For example, assume that the owner of Émile’s restaurant has observed that 80 percent of his customers choose the soup for an appetizer and 20 percent choose juice. Of those who choose soup, 50 percent choose meat, 30 percent choose fish, and 20 percent choose the vegetable dish. Of those who choose juice for an appetizer, 30 percent choose meat, 40 percent choose fish, and 30 percent choose the vegetable dish. We can use this to estimate the probabilities at the first two stages as indicated on the tree diagram of Figure \(\PageIndex{2}\).
We choose for our sample space the set \(\Omega\) of all possible paths \(\omega = \omega_1\), \(\omega_2\), …, \(\omega_6\) through the tree. How should we assign our probability distribution? For example, what probability should we assign to the customer choosing soup and then the meat? If 8/10 of the customers choose soup and then 1/2 of these choose meat, a proportion \(8/10 \cdot 1/2 = 4/10\) of the customers choose soup and then meat. This suggests choosing our probability distribution for each path through the tree to be the product of the probabilities at each of the stages along the path. This results in the probability distribution for the sample points \(\omega\) indicated in Figure \(\PageIndex{2}\). (Note that \(m(\omega_1) + \cdots + m(\omega_6) = 1\).) From this we see, for example, that the probability that a customer chooses meat is \(m(\omega_1) + m(\omega_4) = .46\).
We shall say more about these tree measures when we discuss the concept of conditional probability in Chapter 4. We return now to more counting problems.
We can show that there are at least two people in Columbus, Ohio, who have the same three initials. Assuming that each person has three initials, there are 26 possibilities for a person’s first initial, 26 for the second, and 26 for the third. Therefore, there are \(26^3 = 17,576\) possible sets of initials. This number is smaller than the number of people living in Columbus, Ohio; hence, there must be at least two people with the same three initials.
We consider next the celebrated birthday problem—often used to show that naive intuition cannot always be trusted in probability.
How many people do we need to have in a room to make it a favorable bet (probability of success greater than 1/2) that two people in the room will have the same birthday?
Solution
Since there are 365 possible birthdays, it is tempting to guess that we would need about 1/2 this number, or 183. You would surely win this bet. In fact, the number required for a favorable bet is only 23. To show this, we find the probability \(p_r\) that, in a room with \(r\) people, there is no duplication of birthdays; we will have a favorable bet if this probability is less than one half.
| Number of people | Probability that all birthdays are different |
|---|---|
| 20 | .5885616 |
| 21 | .5563117 |
| 22 | .5243047 |
| 23 | .4927028 |
| 24 | .4616557 |
| 25 | .4313003 |
Assume that there are 365 possible birthdays for each person (we ignore leap years). Order the people from 1 to \(r\). For a sample point \(\omega\), we choose a possible sequence of length \(r\) of birthdays each chosen as one of the 365 possible dates. There are 365 possibilities for the first element of the sequence, and for each of these choices there are 365 for the second, and so forth, making \(365^r\) possible sequences of birthdays. We must find the number of these sequences that have no duplication of birthdays. For such a sequence, we can choose any of the 365 days for the first element, then any of the remaining 364 for the second, 363 for the third, and so forth, until we make \(r\) choices. For the \(r\)th choice, there will be \(365 - r + 1\) possibilities. Hence, the total number of sequences with no duplications is
\[365 \cdot 364 \cdot 363 \cdot \dots \cdot (365 - r + 1)\ .\]
Thus, assuming that each sequence is equally likely,
\[p_r = \frac{365 \cdot 364 \cdot \dots \cdot (365 - r + 1)}{365^r}\ .\]
We denote the product \[(n)(n-1)\cdots (n - r +1)\] by \((n)_r\) (read “\(n\) down \(r\)," or “\(n\) lower \(r\)"). Thus,
\[p_r = \frac{(365)_r}{(365)^r}\ .\]
The program Birthday carries out this computation and prints the probabilities for \(r = 20\) to 25. Running this program, we get the results shown in Table 3.\(\PageIndex{1}\).
As we asserted above, the probability for no duplication changes from greater than one half to less than one half as we move from 22 to 23 people. To see how unlikely it is that we would lose our bet for larger numbers of people, we have run the program again, printing out values from \(r = 10\) to \(r = 100\) in steps of 10. We see that in a room of 40 people the odds already heavily favor a duplication, and in a room of 100 the odds are overwhelmingly in favor of a duplication.
| Number of people | Probability that all birthdays are different |
|---|---|
| 10 | .8830518 |
| 20 | .5885616 |
| 30 | .2936838 |
| 40 | .1087682 |
| 50 | .0296264 |
| 60 | .0058773 |
| 70 | .0008404 |
| 80 | .0000857 |
| 90 | .0000062 |
| 100 | .0000003 |
We have assumed that birthdays are equally likely to fall on any particular day. Statistical evidence suggests that this is not true. However, it is intuitively clear (but not easy to prove) that this makes it even more likely to have a duplication with a group of 23 people. (See Exercise \(\PageIndex{19}\) to find out what happens on planets with more or fewer than 365 days per year.)
Permutations
We now turn to the topic of permutations.
Let \(A\) be any finite set. A permutation of \(A\) is a one-to-one mapping of \(A\) onto itself.
To specify a particular permutation we list the elements of \(A\) and, under them, show where each element is sent by the one-to-one mapping. For example, if \(A = \{a,b,c\}\) a possible permutation \(\sigma\) would be
\[\sigma = \pmatrix{ a & b & c \cr b & c & a \cr}.\]
By the permutation \(\sigma\), \(a\) is sent to \(b\), \(b\) is sent to \(c\), and \(c\) is sent to \(a\). The condition that the mapping be one-to-one means that no two elements of \(A\) are sent, by the mapping, into the same element of \(A\).
We can put the elements of our set in some order and rename them 1, 2, …, \(n\). Then, a typical permutation of the set \(A = \{a_1,a_2,a_3,a_4\}\) can be written in the form
\[\sigma = \pmatrix{ 1 & 2 & 3 & 4 \cr 2 & 1 & 4 & 3 \cr},\]
indicating that \(a_1\) went to \(a_2\), \(a_2\) to \(a_1\), \(a_3\) to \(a_4\), and \(a_4\) to \(a_3\).
If we always choose the top row to be 1 2 3 4 then, to prescribe the permutation, we need only give the bottom row, with the understanding that this tells us where 1 goes, 2 goes, and so forth, under the mapping. When this is done, the permutation is often called a rearrangement of the \(n\) objects 1, 2, 3, …, \(n\). For example, all possible permutations, or rearrangements, of the numbers \(A = \{1,2,3\}\) are: \[123,\ 132,\ 213,\ 231,\ 312,\ 321\ .\]
It is an easy matter to count the number of possible permutations of \(n\) objects. By our general counting principle, there are \(n\) ways to assign the first element, for each of these we have \(n - 1\) ways to assign the second object, \(n - 2\) for the third, and so forth. This proves the following theorem.
The total number of permutations of a set \(A\) of \(n\) elements is given by \(n \cdot (n-1) \cdot (n - 2) \cdot \ldots \cdot 1\).
It is sometimes helpful to consider orderings of subsets of a given set. This prompts the following definition.
Let \(A\) be an \(n\)-element set, and let \(k\) be an integer between 0 and \(n\). Then a \(k\)-permutation of \(A\) is an ordered listing of a subset of \(A\) of size \(k\).
Using the same techniques as in the last theorem, the following result is easily proved.
The total number of \(k\)-permutations of a set \(A\) of \(n\) elements is given by \(n \cdot (n-1) \cdot (n-2) \cdot \ldots \cdot (n - k + 1)\).
Factorials
The number given in Theorem \(\PageIndex{1}\) is called \(n\) factorial, and is denoted by \(n!\). The expression 0! is defined to be 1 to make certain formulas come out simpler. The first few values of this function are shown in Table \(\PageIndex{2}\). The reader will note that this function grows very rapidly.
Table \(\PageIndex{3}\): Values of the factorial function
| n | n! |
| 0 | 1 |
| 1 | 1 |
| 2 | 2 |
| 3 | 6 |
| 4 | 24 |
| 5 | 120 |
| 6 | 720 |
| 7 | 5040 |
| 8 | 40320 |
| 9 | 362880 |
| 10 | 3628800 |
The expression \(n!\) will enter into many of our calculations, and we shall need to have some estimate of its magnitude when \(n\) is large. It is clearly not practical to make exact calculations in this case. We shall instead use a result called Stirling’s formula. Before stating this formula we need a definition.
Definition \(PageIndex{3}\)
Let \(a_n\) and \(b_n\) be two sequences of numbers. We say that \(a_n\) is asymptotically equal to \(b_n\), and write \(a_n \sim b_n\), if
\[\lim_{n \to \infty} \frac{a_n}{b_n} = 1\ .\]
[exam 3.4] If \(a_n = n + \sqrt n\) and \(b_n = n\) then, since \(a_n/b_n = 1 + 1/\sqrt n\) and this ratio tends to 1 as \(n\) tends to infinity, we have \(a_n \sim b_n\).
The sequence \(n!\) is asymptotically equal to
\[n^ne^{-n}\sqrt{2\pi n}\ .\].
The proof of Stirling’s formula may be found in most analysis texts. Let us verify this approximation by using the computer. The program StirlingApproximations prints \(n!\), the Stirling approximation, and, finally, the ratio of these two numbers. Sample output of this program is shown in Table 3.4. Note that, while the ratio of the numbers is getting closer to 1, the difference between the exact value and the approximation is increasing, and indeed, this difference will tend to infinity as \(n\) tends to infinity, even though the ratio tends to 1. (This was also true in our Example \(\PageIndex{4}\) where \(n + \sqrt n \sim n\), but the difference is \(\sqrt n\).)
| \(n\) | \(n!\) | Approximation | Ratio |
|---|---|---|---|
| 1 | 1 | 0.922 | 1.084 |
| 2 | 2 | 1.919 | 1.042 |
| 3 | 6 | 5.836 | 1.028 |
| 4 | 24 | 23.506 | 1.021 |
| 5 | 120 | 118.019 | 1.016 |
| 6 | 720 | 710.078 | 1.013 |
| 7 | 5040 | 4980.396 | 1.011 |
| 8 | 40320 | 39902.395 | 1.010 |
| 9 | 362880 | 359536.873 | 1.009 |
| 10 | 3628800 | 3598696.619 | 1.008 |
Generating Random Permutations
We now consider the question of generating a random permutation of the integers between 1 and \(n\). Consider the following experiment. We start with a deck of \(n\) cards, labelled 1 through \(n\). We choose a random card out of the deck, note its label, and put the card aside. We repeat this process until all \(n\) cards have been chosen. It is clear that each permutation of the integers from 1 to \(n\) can occur as a sequence of labels in this experiment, and that each sequence of labels is equally likely to occur. In our implementations of the computer algorithms, the above procedure is called Random Permutation.
Fixed Points
There are many interesting problems that relate to properties of a permutation chosen at random from the set of all permutations of a given finite set. For example, since a permutation is a one-to-one mapping of the set onto itself, it is interesting to ask how many points are mapped onto themselves. We call such points fixed points of the mapping.
Let \(p_k(n)\) be the probability that a random permutation of the set \(\{1, 2, \ldots, n\}\) has exactly \(k\) fixed points. We will attempt to learn something about these probabilities using simulation. The program FixedPoints uses the procedure RandomPermutation to generate random permutations and count fixed points. The program prints the proportion of times that there are \(k\) fixed points as well as the average number of fixed points. The results of this program for 500 simulations for the cases \(n = 10\), 20, and 30 are shown in Table \(\PageIndex{5}\).
| Number of fixed points | Fraction of permutations | ||
| n = 10 | n = 20 | n = 30 | |
| 0 | 0.362 | 0.370 | 0.358 |
| 1 | 0.368 | 0.396 | 0.358 |
| 2 | 0.202 | 0.164 | 0.192 |
| 3 | 0.052 | 0.060 | 0.070 |
| 4 | 0.012 | 0.008 | 0.020 |
| 5 | 0.004 | 0.002 | 0.002 |
| Average number of fixed points | 0.996 | 0.948 | 1.042 |
Notice the rather surprising fact that our estimates for the probabilities do not seem to depend very heavily on the number of elements in the permutation. For example, the probability that there are no fixed points, when \(n = 10,\ 20,\) or 30 is estimated to be between .35 and .37. We shall see later (see Example \(\PageIndex{12}\) that for \(n \geq 10\) the exact probabilities \(p_n(0)\) are, to six decimal place accuracy, equal to \(1/e \approx .367879\). Thus, for all practical purposes, after \(n = 10\) the probability that a random permutation of the set \(\{1, 2, \ldots, n\}\) has no fixed points does not depend upon \(n\). These simulations also suggest that the average number of fixed points is close to 1. It can be shown (see Example \(\PageIndex{1}\) ) that the average is exactly equal to 1 for all \(n\).
More picturesque versions of the fixed-point problem are: You have arranged the books on your book shelf in alphabetical order by author and they get returned to your shelf at random; what is the probability that exactly \(k\) of the books end up in their correct position? (The library problem.) In a restaurant \(n\) hats are checked and they are hopelessly scrambled; what is the probability that no one gets his own hat back? (The hat check problem.) In the Historical Remarks at the end of this section, we give one method for solving the hat check problem exactly. Another method is given in Example \(\PageIndex{12}\)
Records
Here is another interesting probability problem that involves permutations. Estimates for the amount of measured snow in inches in Hanover, New Hampshire, in the ten years from 1974 to 1983 are shown in Table \(\PageIndex{6}\)
| Date | Snowfall in inches |
|---|---|
| 1974 |
75 |
|
1975 |
88 |
|
1976 |
72 |
|
1977 |
110 |
|
1978 |
85 |
|
1979 |
30 |
|
1980 |
55 |
|
1981 |
86 |
|
1982 |
51 |
|
1983 |
64 |
Suppose we have started keeping records in 1974. Then our first year’s snowfall could be considered a record snowfall starting from this year. A new record was established in 1975; the next record was established in 1977, and there were no new records established after this year. Thus, in this ten-year period, there were three records established: 1974, 1975, and 1977. The question that we ask is: How many records should we expect to be established in such a ten-year period? We can count the number of records in terms of a permutation as follows: We number the years from 1 to 10. The actual amounts of snowfall are not important but their relative sizes are. We can, therefore, change the numbers measuring snowfalls to numbers 1 to 10 by replacing the smallest number by 1, the next smallest by 2, and so forth. (We assume that there are no ties.) For our example, we obtain the data shown in Table \(\PageIndex{6}\).
Table \(\PageIndex{7}\) Ranking of total snowfall
| Year | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Ranking | 6 | 9 | 5 | 10 | 7 | 1 | 3 | 8 | 2 | 4 |
This gives us a permutation of the numbers from 1 to 10 and, from this permutation, we can read off the records; they are in years 1, 2, and 4. Thus we can define records for a permutation as follows:
Let \(\sigma\) be a permutation of the set \(\{1, 2, \ldots, n\}\). Then \(i\) is a record of \(\sigma\) if either \(i = 1\) or \(\sigma(j) < \sigma(i)\) for every \(j = 1,\ldots,\,i - 1\).
Now if we regard all rankings of snowfalls over an \(n\)-year period to be equally likely (and allow no ties), we can estimate the probability that there will be \(k\) records in \(n\) years as well as the average number of records by simulation.
We have written a program Records that counts the number of records in randomly chosen permutations. We have run this program for the cases \(n = 10\), 20, 30. For \(n = 10\) the average number of records is 2.968, for 20 it is 3.656, and for 30 it is 3.960. We see now that the averages increase, but very slowly. We shall see later (see Example \(\PageIndex{11}\)) that the average number is approximately \(\log n\). Since \(\log 10 = 2.3\), \(\log 20 = 3\), and \(\log 30 = 3.4\), this is consistent with the results of our simulations.
As remarked earlier, we shall be able to obtain formulas for exact results of certain problems of the above type. However, only minor changes in the problem make this impossible. The power of simulation is that minor changes in a problem do not make the simulation much more difficult. (See Exercise \(\PageIndex{20}\) for an interesting variation of the hat check problem.)
List of Permutations
Another method to solve problems that is not sensitive to small changes in the problem is to have the computer simply list all possible permutations and count the fraction that have the desired property. The program AllPermutations produces a list of all of the permutations of \(n\). When we try running this program, we run into a limitation on the use of the computer. The number of permutations of \(n\) increases so rapidly that even to list all permutations of 20 objects is impractical.
Historical Remarks
Our basic counting principle stated that if you can do one thing in \(r\) ways and for each of these another thing in \(s\) ways, then you can do the pair in \(rs\) ways. This is such a self-evident result that you might expect that it occurred very early in mathematics. N. L. Biggs suggests that we might trace an example of this principle as follows: First, he relates a popular nursery rhyme dating back to at least 1730:
As I was going to St. Ives,
I met a man with seven wives,
Each wife had seven sacks,
Each sack had seven cats,
Each cat had seven kits.
Kits, cats, sacks and wives,
How many were going to St. Ives?
(You need our principle only if you are not clever enough to realize that you are supposed to answer one, since only the narrator is going to St. Ives; the others are going in the other direction!)
He also gives a problem appearing on one of the oldest surviving mathematical manuscripts of about 1650 B.C., roughly translated as:
Table Table \(\PageIndex{8}\):
|
Houses |
7 |
|
Cats |
49 |
|
Mice |
343 |
|
Wheat |
2401 |
|
Hekat |
16807 |
| Total | 19607 |
The following interpretation has been suggested: there are seven houses, each with seven cats; each cat kills seven mice; each mouse would have eaten seven heads of wheat, each of which would have produced seven hekat measures of grain. With this interpretation, the table answers the question of how many hekat measures were saved by the cats’ actions. It is not clear why the writer of the table wanted to add the numbers together.1
One of the earliest uses of factorials occurred in Euclid’s proof that there are infinitely many prime numbers. Euclid argued that there must be a prime number between \(n\) and \(n! + 1\) as follows: \(n!\) and \(n! + 1\) cannot have common factors. Either \(n! + 1\) is prime or it has a proper factor. In the latter case, this factor cannot divide \(n!\) and hence must be between \(n\) and \(n! + 1\). If this factor is not prime, then it has a factor that, by the same argument, must be bigger than \(n\). In this way, we eventually reach a prime bigger than \(n\), and this holds for all \(n\).
The “\(n!\)" rule for the number of permutations seems to have occurred first in India. Examples have been found as early as 300 B.C., and by the eleventh century the general formula seems to have been well known in India and then in the Arab countries.
The hat check problem is found in an early probability book written by de Montmort and first printed in 1708.2 It appears in the form of a game called Treize. In a simplified version of this game considered by de Montmort one turns over cards numbered 1 to 13, calling out 1, 2, …, 13 as the cards are examined. De Montmort asked for the probability that no card that is turned up agrees with the number called out.
This probability is the same as the probability that a random permutation of 13 elements has no fixed point. De Montmort solved this problem by the use of a recursion relation as follows: let \(w_n\) be the number of permutations of \(n\) elements with no fixed point (such permutations are called derangements). Then \(w_1 = 0\) and \(w_2 = 1\).
Now assume that \(n \ge 3\) and choose a derangement of the integers between 1 and \(n\). Let \(k\) be the integer in the first position in this derangement. By the definition of derangement, we have \(k \ne 1\). There are two possibilities of interest concerning the position of 1 in the derangement: either 1 is in the \(k\)th position or it is elsewhere. In the first case, the \(n-2\) remaining integers can be positioned in \(w_{n-2}\) ways without resulting in any fixed points. In the second case, we consider the set of integers \(\{1, 2, \ldots, k-1, k+1, \ldots, n\}\). The numbers in this set must occupy the positions \(\{2, 3, \ldots, n\}\) so that none of the numbers other than 1 in this set are fixed, and also so that 1 is not in position \(k\). The number of ways of achieving this kind of arrangement is just \(w_{n-1}\). Since there are \(n-1\) possible values of \(k\), we see that \[w_n = (n - 1)w_{n - 1} + (n - 1)w_{n -2}\] for \(n \ge 3\). One might conjecture from this last equation that the sequence \(\{w_n\}\) grows like the sequence \(\{n!\}\).
In fact, it is easy to prove by induction that \[w_n = nw_{n - 1} + (-1)^n\ .\] Then \(p_i = w_i/i!\) satisfies \[p_i - p_{i - 1} = \frac{(-1)^i}{i!}\ .\] If we sum from \(i = 2\) to \(n\), and use the fact that \(p_1 = 0\), we obtain \[p_n = \frac1{2!} - \frac1{3!} + \cdots + \frac{(-1)^n}{n!}\ .\] This agrees with the first \(n + 1\) terms of the expansion for \(e^x\) for \(x = -1\) and hence for large \(n\) is approximately \(e^{-1} \approx .368\). David remarks that this was possibly the first use of the exponential function in probability.3 We shall see another way to derive de Montmort’s result in the next section, using a method known as the Inclusion-Exclusion method.
Recently, a related problem appeared in a column of Marilyn vos Savant.4 Charles Price wrote to ask about his experience playing a certain form of solitaire, sometimes called “frustration solitaire." In this particular game, a deck of cards is shuffled, and then dealt out, one card at a time. As the cards are being dealt, the player counts from 1 to 13, and then starts again at 1. (Thus, each number is counted four times.) If a number that is being counted coincides with the rank of the card that is being turned up, then the player loses the game. Price found that he rarely won and wondered how often he should win. Vos Savant remarked that the expected number of matches is 4 so it should be difficult to win the game.
Finding the chance of winning is a harder problem than the one that de Montmort solved because, when one goes through the entire deck, there are different patterns for the matches that might occur. For example matches may occur for two cards of the same rank, say two aces, or for two different ranks, say a two and a three.
A discussion of this problem can be found in Riordan.5 In this book, it is shown that as \(n \rightarrow \infty\), the probability of no matches tends to \(1/e^4\).
The original game of Treize is more difficult to analyze than frustration solitaire. The game of Treize is played as follows. One person is chosen as dealer and the others are players. Each player, other than the dealer, puts up a stake. The dealer shuffles the cards and turns them up one at a time calling out, “Ace, two, three,..., king," just as in frustration solitaire. If the dealer goes through the 13 cards without a match he pays the players an amount equal to their stake, and the deal passes to someone else. If there is a match the dealer collects the players’ stakes; the players put up new stakes, and the dealer continues through the deck, calling out, “Ace, two, three, ...." If the dealer runs out of cards he reshuffles and continues the count where he left off. He continues until there is a run of 13 without a match and then a new dealer is chosen.
The question at this point is how much money can the dealer expect to win from each player. De Montmort found that if each player puts up a stake of 1, say, then the dealer will win approximately .801 from each player.
Peter Doyle calculated the exact amount that the dealer can expect to win. The answer is:
265160721560102185822276079127341827846421204821360914467153719620899315231134354172455433491287054144029923925160769411350008077591781851201382176876653563173852874555859367254632009477403727395572807459384342747876649650760639905382611893881435135473663160170049455072017642788283066011710795363314273438247792270983528175329903598858141368836765583311324476153310720627474169719301806649152698704084383914217907906954976036285282115901403162021206015491269208808249133255538826920554278308103685781886120875824880068097864043811858283487754256095555066287892712304826997601700116233592793308297533642193505074540268925683193887821301442705197918823303692913358259222011722071315607111497510114983106336407213896987800799647204708825303387525892236581323015628005621143427290625658974433971 657194541229080070862898413060875613028189911673578636237560671849864913535355362219744889022326710115880101628593135197929438722327703339696779797069933475802423676949873661605184031477561560393380257070970711959696412682424550133198797470546935178093837505934888586986723648469505398886862858260990558627100131815062113440705698321474022185156770667208094586589378459432799868706334161812988630496327287254818458879353024498 00322425586446741048147720934108061350613503856973048971213063937040515 59533731591.
This is .803 to 3 decimal places. A description of the algorithm used to find this answer can be found on his Web page.6 A discussion of this problem and other problems can be found in Doyle et al.7
The birthday problem does not seem to have a very old history. Problems of this type were first discussed by von Mises.8 It was made popular in the 1950s by Feller’s book.9
Stirling presented his formula
\[n! \sim \sqrt{2\pi n}\left(\frac{n}{e}\right)^n\]
in his work Methodus Differentialis published in 1730.10 This approximation was used by de Moivre in establishing his celebrated central limit theorem that we will study in Chapter 9. De Moivre himself had independently established this approximation, but without identifying the constant \(\pi\). Having established the approximation
\[\frac{2B}{\sqrt n}\]
for the central term of the binomial distribution, where the constant \(B\) was determined by an infinite series, de Moivre writes:
… my worthy and learned Friend, Mr. James Stirling, who had applied himself after me to that inquiry, found that the Quantity \(B\) did denote the Square-root of the Circumference of a Circle whose Radius is Unity, so that if that Circumference be called \(c\) the Ratio of the middle Term to the Sum of all Terms will be expressed by \(2/\sqrt{nc}\,\)….11
Exercises
\(\PageIndex{1}\)
Four people are to be arranged in a row to have their picture taken. In how many ways can this be done?
\(\PageIndex{2}\)
An automobile manufacturer has four colors available for automobile exteriors and three for interiors. How many different color combinations can he produce?
\(\PageIndex{3}\)
In a digital computer, a bit is one of the integers {0,1}, and a word is any string of 32 bits. How many different words are possible?
\(\PageIndex{4}\)
What is the probability that at least 2 of the presidents of the United States have died on the same day of the year? If you bet this has happened, would you win your bet?
\(\PageIndex{5}\)
There are three different routes connecting city A to city B. How many ways can a round trip be made from A to B and back? How many ways if it is desired to take a different route on the way back?
\(\PageIndex{6}\)
In arranging people around a circular table, we take into account their seats relative to each other, not the actual position of any one person. Show that \(n\) people can be arranged around a circular table in \((n - 1)!\) ways.
\(\PageIndex{7}\)
Five people get on an elevator that stops at five floors. Assuming that each has an equal probability of going to any one floor, find the probability that they all get off at different floors.
\(\PageIndex{8}\)
A finite set \(\Omega\) has \(n\) elements. Show that if we count the empty set and \(\Omega\) as subsets, there are \(2^n\) subsets of \(\Omega\).
\(\PageIndex{9}\)
A more refined inequality for approximating \(n!\) is given by \[\sqrt{2\pi n}\left(\frac ne\right)^n e^{1/(12n + 1)} < n! < \sqrt{2\pi n}\left(\frac ne\right)^n e^{1/(12n)}\ .\] Write a computer program to illustrate this inequality for \(n = 1\) to 9.
\(\PageIndex{10}\)
A deck of ordinary cards is shuffled and 13 cards are dealt. What is the probability that the last card dealt is an ace?
\(\PageIndex{11}\)
There are \(n\) applicants for the director of computing. The applicants are interviewed independently by each member of the three-person search committee and ranked from 1 to \(n\). A candidate will be hired if he or she is ranked first by at least two of the three interviewers. Find the probability that a candidate will be accepted if the members of the committee really have no ability at all to judge the candidates and just rank the candidates randomly. In particular, compare this probability for the case of three candidates and the case of ten candidates.
\(\PageIndex{12}\)
A symphony orchestra has in its repertoire 30 Haydn symphonies, 15 modern works, and 9 Beethoven symphonies. Its program always consists of a Haydn symphony followed by a modern work, and then a Beethoven symphony.
- How many different programs can it play?
- How many different programs are there if the three pieces can be played in any order?
- How many different three-piece programs are there if more than one piece from the same category can be played and they can be played in any order?
\(\PageIndex{13}\)
A certain state has license plates showing three numbers and three letters. How many different license plates are possible
- if the numbers must come before the letters?
- if there is no restriction on where the letters and numbers appear?
\(\PageIndex{14}\)
The door on the computer center has a lock which has five buttons numbered from 1 to 5. The combination of numbers that opens the lock is a sequence of five numbers and is reset every week.
- How many combinations are possible if every button must be used once?
- Assume that the lock can also have combinations that require you to push two buttons simultaneously and then the other three one at a time. How many more combinations does this permit?
\(\PageIndex{15}\)
A computing center has 3 processors that receive \(n\) jobs, with the jobs assigned to the processors purely at random so that all of the \(3^n\) possible assignments are equally likely. Find the probability that exactly one processor has no jobs.
\(\PageIndex{16}\)
Prove that at least two people in Atlanta, Georgia, have the same initials, assuming no one has more than four initials.
\(\PageIndex{17}\)
Find a formula for the probability that among a set of \(n\) people, at least two have their birthdays in the same month of the year (assuming the months are equally likely for birthdays).
\(\PageIndex{18}\)
Consider the problem of finding the probability of more than one coincidence of birthdays in a group of \(n\) people. These include, for example, three people with the same birthday, or two pairs of people with the same birthday, or larger coincidences. Show how you could compute this probability, and write a computer program to carry out this computation. Use your program to find the smallest number of people for which it would be a favorable bet that there would be more than one coincidence of birthdays.
\(\PageIndex{19}\)
Suppose that on planet Zorg a year has \(n\) days, and that the lifeforms there are equally likely to have hatched on any day of the year. We would like to estimate \(d\), which is the minimum number of lifeforms needed so that the probability of at least two sharing a birthday exceeds 1/2.
- In Example \(\PageIndex{3}\), it was shown that in a set of \(d\) lifeforms, the probability that no two life forms share a birthday is \[ \frac{(n)_d}{n^d} ,\]
- where \((n)_d = (n)(n-1)\cdots (n-d+1)\). Thus, we would like to set this equal to 1/2 and solve for \(d\).
- Using Stirling’s Formula, show that \[(click for details)\sim \biggl(1 + {d\over{n-d}}\biggr)^{n-d + 1/2} e^{-d}\ .\]
Callstack: at (Bookshelves/Probability_Theory/Book:_Introductory_Probability_(Grinstead_and_Snell)/03:_Combinatorics/3.01:_Permutations), /content/body/div[11]/div[19]/ol/li[3]/span, line 1, column 4 - Now take the logarithm of the right-hand expression, and use the fact that for small values of \(x\), we have \[\log(1+x) \sim x - {{x^2}\over 2}\ .\] (We are implicitly using the fact that \(d\) is of smaller order of magnitude than \(n\). We will also use this fact in part (d).)
- Set the expression found in part (c) equal to \(-\log(2)\), and solve for \(d\) as a function of \(n\), thereby showing that \[d \sim \sqrt{2(\log 2)\,n}\ .\] : If all three summands in the expression found in part (b) are used, one obtains a cubic equation in \(d\). If the smallest of the three terms is thrown away, one obtains a quadratic equation in \(d\).
- Use a computer to calculate the exact values of \(d\) for various values of \(n\). Compare these values with the approximate values obtained by using the answer to part d).
i(\PageIndex{20}\)
At a mathematical conference, ten participants are randomly seated around a circular table for meals. Using simulation, estimate the probability that no two people sit next to each other at both lunch and dinner. Can you make an intelligent conjecture for the case of \(n\) participants when \(n\) is large?
\(\PageIndex{21}\)
Modify the program AllPermutations to count the number of permutations of \(n\) objects that have exactly \(j\) fixed points for \(j = 0\), 1, 2, …, \(n\). Run your program for \(n = 2\) to 6. Make a conjecture for the relation between the number that have 0 fixed points and the number that have exactly 1 fixed point. A proof of the correct conjecture can be found in Wilf.12
\(\PageIndex{22}\)
Mr. Wimply Dimple, one of London’s most prestigious watch makers, has come to Sherlock Holmes in a panic, having discovered that someone has been producing and selling crude counterfeits of his best selling watch. The 16 counterfeits so far discovered bear stamped numbers, all of which fall between 1 and 56, and Dimple is anxious to know the extent of the forger’s work. All present agree that it seems reasonable to assume that the counterfeits thus far produced bear consecutive numbers from 1 to whatever the total number is.
“Chin up, Dimple," opines Dr. Watson. “I shouldn’t worry overly much if I were you; the Maximum Likelihood Principle, which estimates the total number as precisely that which gives the highest probability for the series of numbers found, suggests that we guess 56 itself as the total. Thus, your forgers are not a big operation, and we shall have them safely behind bars before your business suffers significantly."
“Stuff, nonsense, and bother your fancy principles, Watson," counters Holmes. “Anyone can see that, of course, there must be quite a few more than 56 watches—why the odds of our having discovered precisely the highest numbered watch made are laughably negligible. A much better guess would be 56."
- Show that Watson is correct that the Maximum Likelihood Principle gives 56.
- Write a computer program to compare Holmes’s and Watson’s guessing strategies as follows: fix a total \(N\) and choose 16 integers randomly between 1 and \(N\). Let \(m\) denote the largest of these. Then Watson’s guess for \(N\) is \(m\), while Holmes’s is \(2m\). See which of these is closer to \(N\). Repeat this experiment (with \(N\) still fixed) a hundred or more times, and determine the proportion of times that each comes closer. Whose seems to be the better strategy?
\(\PageIndex{23}\)
Barbara Smith is interviewing candidates to be her secretary. As she interviews the candidates, she can determine the relative rank of the candidates but not the true rank. Thus, if there are six candidates and their true rank is 6, 1, 4, 2, 3, 5, (where 1 is best) then after she had interviewed the first three candidates she would rank them 3, 1, 2. As she interviews each candidate, she must either accept or reject the candidate. If she does not accept the candidate after the interview, the candidate is lost to her. She wants to decide on a strategy for deciding when to stop and accept a candidate that will maximize the probability of getting the best candidate. Assume that there are \(n\) candidates and they arrive in a random rank order.
- What is the probability that Barbara gets the best candidate if she interviews all of the candidates? What is it if she chooses the first candidate?
- Assume that Barbara decides to interview the first half of the candidates and then continue interviewing until getting a candidate better than any candidate seen so far. Show that she has a better than 25 percent chance of ending up with the best candidate.
\(\PageIndex{24}\)
For the task described in Exercise 23, it can be shown13 that the best strategy is to pass over the first \(k - 1\) candidates where \(k\) is the smallest integer for which \[\frac 1k + \frac 1{k + 1} + \cdots + \frac 1{n - 1} \leq 1\ .\] Using this strategy the probability of getting the best candidate is approximately \(1/e = .368\). Write a program to simulate Barbara Smith’s interviewing if she uses this optimal strategy, using \(n = 10\), and see if you can verify that the probability of success is approximately \(1/e\).