
10.8: Answers to exercises
- Page ID
- 4327
Answer to the sundew wetness question. Let us apply the approach we used for the leaf shape:
Code \(\PageIndex{1}\) (R):
(Plots are not shown, please make them yourself.)
There is some periodicity with 0.2 (5 hours) period. However, trend is likely absent.
Answer to the dodder infestation question. Inspect the data, load and check:
Code \(\PageIndex{2}\) (R):
(Note that two last columns are ranked. Consequently, only nonparametric methods are applicable here.)
Then we need to select two hosts of question and drop unused levels:
Code \(\PageIndex{3}\) (R):
It is better to convert this to the short form:
Code \(\PageIndex{4}\) (R):
No look on these samples graphically:
Code \(\PageIndex{5}\) (R):
There is a prominent difference. Now to numbers:
Code \(\PageIndex{6}\) (R):
Interesting! Despite on the difference between medians and large effect size, Wilcoxon test failed to support it statistically. Why? Were shapes of distributions similar?
Code \(\PageIndex{7}\) (R):
(Please note how to make complex layout with layout() command. This commands takes matrix as argument, and then simply place plot number something to the position where this number occurs in the matrix. After layout was created, you can check it with command layout.show(la).)
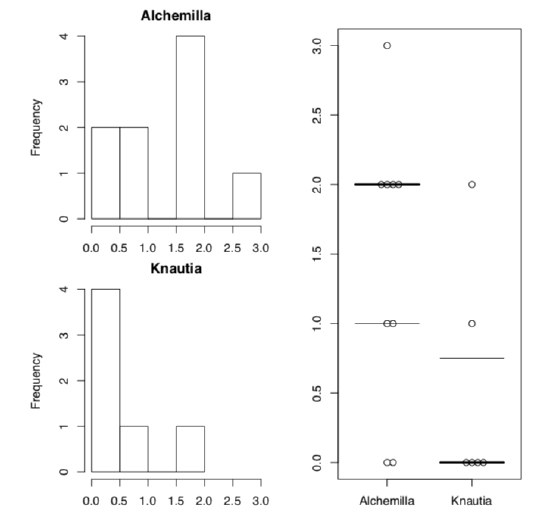
As both Ansari-Bradley test and plots suggest, distributions are really different (Figure \(\PageIndex{2}\)). One workaround is to use robust rank order test which is not so sensitive to the differences in variation:
Code \(\PageIndex{8}\) (R):
This test found the significance.
Now we will try to bootstrap the difference between medians:
Code \(\PageIndex{9}\) (R):
(Please note how strata was applied to avoid mixing of two different hosts.)
This is not dissimilar to what we saw above in the effect size output: large difference but 0 included. This could be described as “prominent but unstable” difference.
That was not asked in assignment but how to analyze whole data in case of so different shapes of distributions. One possibility is the Kruskal test with Monte-Carlo replications. By default, it makes 1000 tries:
Code \(\PageIndex{10}\) (R):
There is no overall significance. It is not a surprise, ANOVA-like tests could sometimes contradict with individual or pairwise.
Another possibility is a post hoc robust rank order test:
Code \(\PageIndex{11}\) (R):
Now it found some significant differences but did not reveal it for our marginal, unstable case of Alchemilla and Knautia.