
7.4: Semi-supervised learning
- Page ID
- 3585

There is no deep distinction between supervised and non-supevised methods, some of non-supervised (like SOM or PCA) could use training whereas some supervised (LDA, Random Forest, recursive partitioning) are useful directly as visualizations.
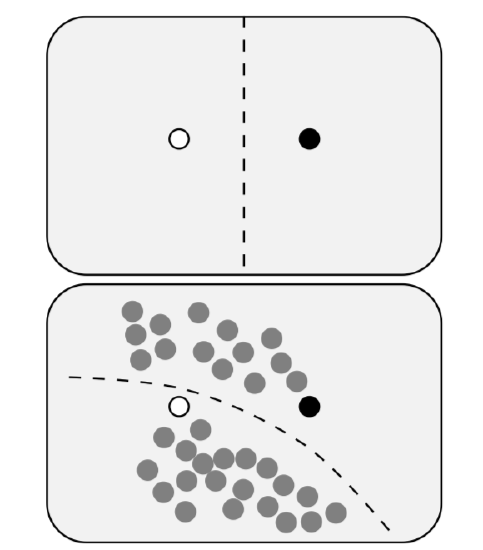
And there is a in-between semi-supervised learning. It takes into account both data features and data labeling (Figure \(\PageIndex{2}\)).
One of the most important features of SSL is an ability to work with the very small training sample. Many really bright ideas are embedded in SSL, here we illustrate two of them. Self-learning is when classification is developed in multiple cycles. On each cycle, testing points which are most confident, are labeled and added to the training set:
Code \(\PageIndex{1}\) (R):
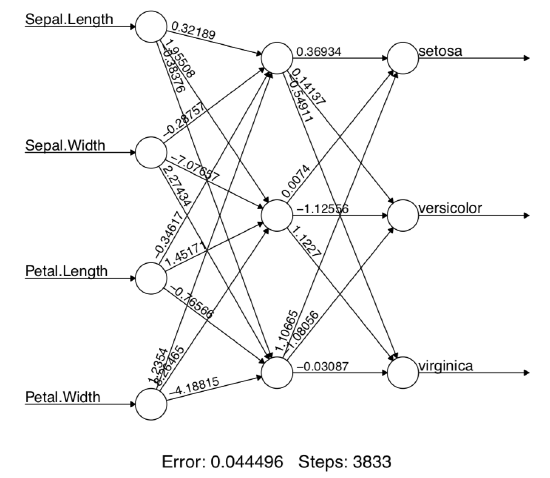
As you see, with only 5 data points (approximately 3% of data vs. 33% of data in iris.train), semi-supervised self-leaning (based on gradient boosting in this case) reached 73% of accuracy.
Another semi-supervised approach is based on graph theory and uses graph label propagation:
Code \(\PageIndex{2}\) (R):
The idea of this algorithm is similar to what was shown on the illustration (Figure \(\PageIndex{2}\)) above. Label propagation with 10 points outperforms Randon Forest (see above) which used 30 points.