
3.1: Sample Spaces, Events, and Their Probabilities
- Page ID
- 530
- To learn the concept of the sample space associated with a random experiment.
- To learn the concept of an event associated with a random experiment.
- To learn the concept of the probability of an event.
Sample Spaces and Events
Rolling an ordinary six-sided die is a familiar example of a random experiment, an action for which all possible outcomes can be listed, but for which the actual outcome on any given trial of the experiment cannot be predicted with certainty. In such a situation we wish to assign to each outcome, such as rolling a two, a number, called the probability of the outcome, that indicates how likely it is that the outcome will occur. Similarly, we would like to assign a probability to any event, or collection of outcomes, such as rolling an even number, which indicates how likely it is that the event will occur if the experiment is performed. This section provides a framework for discussing probability problems, using the terms just mentioned.
A random experiment is a mechanism that produces a definite outcome that cannot be predicted with certainty. The sample space associated with a random experiment is the set of all possible outcomes. An event is a subset of the sample space.
An event \(E\) is said to occur on a particular trial of the experiment if the outcome observed is an element of the set \(E\).
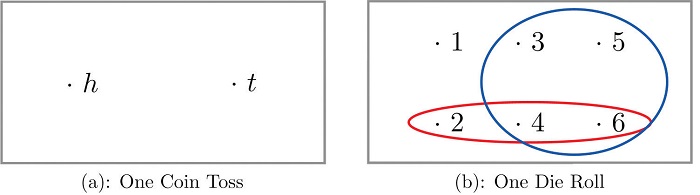
Example \(\PageIndex{1}\): Sample Space for a single coin
Construct a sample space for the experiment that consists of tossing a single coin.
Solution
The outcomes could be labeled \(h\) for heads and \(t\) for tails. Then the sample space is the set: \(S = \{h,t\}\)
Example \(\PageIndex{2}\): Sample Space for a single die
Construct a sample space for the experiment that consists of rolling a single die. Find the events that correspond to the phrases “an even number is rolled” and “a number greater than two is rolled.”
Solution
The outcomes could be labeled according to the number of dots on the top face of the die. Then the sample space is the set \(S = \{1,2,3,4,5,6\}\)
The outcomes that are even are \(2, 4,\; \; \text{and}\; \; 6\), so the event that corresponds to the phrase “an even number is rolled” is the set \(\{2,4,6\}\), which it is natural to denote by the letter \(E\). We write \(E=\{2,4,6\}\).
Similarly the event that corresponds to the phrase “a number greater than two is rolled” is the set \(T=\{3,4,5,6\}\), which we have denoted \(T\).
A graphical representation of a sample space and events is a Venn diagram, as shown in Figure \(\PageIndex{1}\). In general the sample space \(S\) is represented by a rectangle, outcomes by points within the rectangle, and events by ovals that enclose the outcomes that compose them.
Example \(\PageIndex{3}\): Sample Spaces for two coines
A random experiment consists of tossing two coins.
- Construct a sample space for the situation that the coins are indistinguishable, such as two brand new pennies.
- Construct a sample space for the situation that the coins are distinguishable, such as one a penny and the other a nickel.
Solution
- After the coins are tossed one sees either two heads, which could be labeled \(2h\), two tails, which could be labeled \(2t\), or coins that differ, which could be labeled \(d\) Thus a sample space is \(S=\{2h, 2t, d\}\).
- Since we can tell the coins apart, there are now two ways for the coins to differ: the penny heads and the nickel tails, or the penny tails and the nickel heads. We can label each outcome as a pair of letters, the first of which indicates how the penny landed and the second of which indicates how the nickel landed. A sample space is then \(S' = \{hh, ht, th, tt\}\).
A device that can be helpful in identifying all possible outcomes of a random experiment, particularly one that can be viewed as proceeding in stages, is what is called a tree diagram. It is described in the following example.
Example \(\PageIndex{4}\): Tree diagram
Construct a sample space that describes all three-child families according to the genders of the children with respect to birth order.
Solution
Two of the outcomes are “two boys then a girl,” which we might denote \(bbg\), and “a girl then two boys,” which we would denote \(gbb\).
Clearly there are many outcomes, and when we try to list all of them it could be difficult to be sure that we have found them all unless we proceed systematically. The tree diagram shown in Figure \(\PageIndex{2}\), gives a systematic approach.
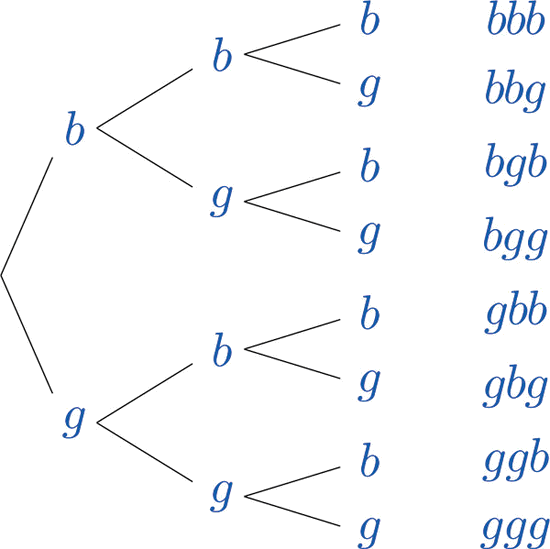
The diagram was constructed as follows. There are two possibilities for the first child, boy or girl, so we draw two line segments coming out of a starting point, one ending in a \(b\) for “boy” and the other ending in a \(g\) for “girl.” For each of these two possibilities for the first child there are two possibilities for the second child, “boy” or “girl,” so from each of the \(b\) and \(g\) we draw two line segments, one segment ending in a \(b\) and one in a \(g\). For each of the four ending points now in the diagram there are two possibilities for the third child, so we repeat the process once more.
The line segments are called branches of the tree. The right ending point of each branch is called a node. The nodes on the extreme right are the final nodes; to each one there corresponds an outcome, as shown in the figure.
From the tree it is easy to read off the eight outcomes of the experiment, so the sample space is, reading from the top to the bottom of the final nodes in the tree,
\[S=\{bbb,\; bbg,\; bgb,\; bgg,\; gbb,\; gbg,\; ggb,\; ggg\} \nonumber \]
Probability
The probability of an outcome \(e\) in a sample space \(S\) is a number \(P\) between \(1\) and \(0\) that measures the likelihood that \(e\) will occur on a single trial of the corresponding random experiment. The value \(P=0\) corresponds to the outcome \(e\) being impossible and the value \(P=1\) corresponds to the outcome \(e\) being certain.
The probability of an event \(A\) is the sum of the probabilities of the individual outcomes of which it is composed. It is denoted \(P(A)\).
The following formula expresses the content of the definition of the probability of an event:
If an event \(E\) is \(E=\{e_1,e_2,...,e_k\}\), then
\[P(E)=P(e_1)+P(e_2)+...+P(e_k) \nonumber \]
The following figure expresses the content of the definition of the probability of an event:
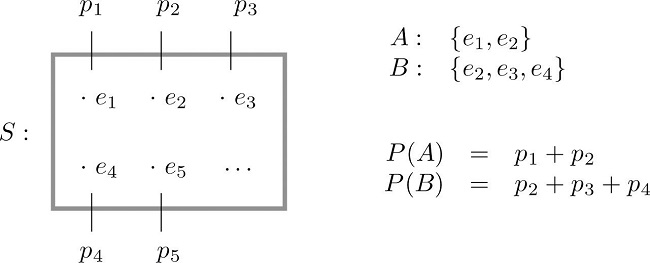
Since the whole sample space \(S\) is an event that is certain to occur, the sum of the probabilities of all the outcomes must be the number \(1\).
In ordinary language probabilities are frequently expressed as percentages. For example, we would say that there is a \(70\%\) chance of rain tomorrow, meaning that the probability of rain is \(0.70\). We will use this practice here, but in all the computational formulas that follow we will use the form \(0.70\) and not \(70\%\).
A coin is called “balanced” or “fair” if each side is equally likely to land up. Assign a probability to each outcome in the sample space for the experiment that consists of tossing a single fair coin.
Solution
With the outcomes labeled \(h\) for heads and \(t\) for tails, the sample space is the set
\[S=\{h,t\} \nonumber \]
Since the outcomes have the same probabilities, which must add up to \(1\), each outcome is assigned probability \(1/2\).
A die is called “balanced” or “fair” if each side is equally likely to land on top. Assign a probability to each outcome in the sample space for the experiment that consists of tossing a single fair die. Find the probabilities of the events \(E\): “an even number is rolled” and \(T\): “a number greater than two is rolled.”
Solution
With outcomes labeled according to the number of dots on the top face of the die, the sample space is the set
\[S=\{1,2,3,4,5,6\} \nonumber \]
Since there are six equally likely outcomes, which must add up to \(1\), each is assigned probability \(1/6\).
Since \(E = \{2,4,6\}\),
\[P(E) = \dfrac{1}{6} + \dfrac{1}{6} + \dfrac{1}{6} = \dfrac{3}{6} = \dfrac{1}{2} \nonumber \]
Since \(T = \{3,4,5,6\}\),
\[P(T) = \dfrac{4}{6} = \dfrac{2}{3} \nonumber \]
Two fair coins are tossed. Find the probability that the coins match, i.e., either both land heads or both land tails.
Solution
In Example \(\PageIndex{3}\) we constructed the sample space \(S=\{2h,2t,d\}\) for the situation in which the coins are identical and the sample space \(S′=\{hh,ht,th,tt\}\) for the situation in which the two coins can be told apart.
The theory of probability does not tell us how to assign probabilities to the outcomes, only what to do with them once they are assigned. Specifically, using sample space \(S\), matching coins is the event \(M=\{2h, 2t\}\) which has probability \(P(2h)+P(2t)\). Using sample space \(S'\), matching coins is the event \(M'=\{hh, tt\}\), which has probability \(P(hh)+P(tt)\). In the physical world it should make no difference whether the coins are identical or not, and so we would like to assign probabilities to the outcomes so that the numbers \(P(M)\) and \(P(M')\) are the same and best match what we observe when actual physical experiments are performed with coins that seem to be fair. Actual experience suggests that the outcomes in S' are equally likely, so we assign to each probability \(\frac{1}{4}\), and then...
\[P(M') = P(hh) + P(tt) = \frac{1}{4} + \frac{1}{4} = \frac{1}{2} \nonumber \]
Similarly, from experience appropriate choices for the outcomes in \(S\) are:
\[P(2h) = \frac{1}{4} \nonumber \]
\[P(2t) = \frac{1}{4} \nonumber \]
\[P(d) = \frac{1}{2} \nonumber \]
The previous three examples illustrate how probabilities can be computed simply by counting when the sample space consists of a finite number of equally likely outcomes. In some situations the individual outcomes of any sample space that represents the experiment are unavoidably unequally likely, in which case probabilities cannot be computed merely by counting, but the computational formula given in the definition of the probability of an event must be used.
The breakdown of the student body in a local high school according to race and ethnicity is \(51\%\) white, \(27\%\) black, \(11\%\) Hispanic, \(6\%\) Asian, and \(5\%\) for all others. A student is randomly selected from this high school. (To select “randomly” means that every student has the same chance of being selected.) Find the probabilities of the following events:
- \(B\): the student is black,
- \(M\): the student is minority (that is, not white),
- \(N\): the student is not black.
Solution
The experiment is the action of randomly selecting a student from the student population of the high school. An obvious sample space is \(S=\{w,b,h,a,o\}\). Since \(51\%\) of the students are white and all students have the same chance of being selected, \(P(w)=0.51\), and similarly for the other outcomes. This information is summarized in the following table:
\[\begin{array}{l|cccc}Outcome & w & b & h & a & o \\ Probability & 0.51 & 0.27 & 0.11 & 0.06 & 0.05\end{array} \nonumber \]
- Since \(B=\{b\},\; \; P(B)=P(b)=0.27\)
- Since \(M=\{b,h,a,o\},\; \; P(M)=P(b)+P(h)+P(a)+P(o)=0.27+0.11+0.06+0.05=0.49\)
- Since \(N=\{w,h,a,o\},\; \; P(N)=P(w)+P(h)+P(a)+P(o)=0.51+0.11+0.06+0.05=0.73\)
The student body in the high school considered in the last example may be broken down into ten categories as follows: \(25\%\) white male, \(26\%\) white female, \(12\%\) black male, \(15\%\) black female, 6% Hispanic male, \(5\%\) Hispanic female, \(3\%\) Asian male, \(3\%\) Asian female, \(1\%\) male of other minorities combined, and \(4\%\) female of other minorities combined. A student is randomly selected from this high school. Find the probabilities of the following events:
- \(B\): the student is black
- \(MF\): the student is a non-white female
- \(FN\): the student is female and is not black
Solution
Now the sample space is \(S=\{wm, bm, hm, am, om, wf, bf, hf, af, of\}\). The information given in the example can be summarized in the following table, called a two-way contingency table:
| Gender | Race / Ethnicity | ||||
|---|---|---|---|---|---|
| White | Black | Hispanic | Asian | Others | |
| Male | 0.25 | 0.12 | 0.06 | 0.03 | 0.01 |
| Female | 0.26 | 0.15 | 0.05 | 0.03 | 0.04 |
- Since \(B=\{bm, bf\},\; \; P(B)=P(bm)+P(bf)=0.12+0.15=0.27\)
- Since \(MF=\{bf, hf, af, of\},\; \; P(M)=P(bf)+P(hf)+P(af)+P(of)=0.15+0.05+0.03+0.04=0.27\)
- Since \(FN=\{wf, hf, af, of\},\; \; P(FN)=P(wf)+P(hf)+P(af)+P(of)=0.26+0.05+0.03+0.04=0.38\)
Key Takeaway
- The sample space of a random experiment is the collection of all possible outcomes.
- An event associated with a random experiment is a subset of the sample space.
- The probability of any outcome is a number between \(0\) and \(1\). The probabilities of all the outcomes add up to \(1\).
- The probability of any event \(A\) is the sum of the probabilities of the outcomes in \(A\).