
1.E: Introduction to Statistics (Exercises)
- Page ID
- 2072

General Questions
Q1
A teacher wishes to know whether the males in his/her class have more conservative attitudes than the females. A questionnaire is distributed assessing attitudes and the males and the females are compared. Is this an example of descriptive or inferential statistics? ( relevant section 1, relevant section 2 )
Q2
A cognitive psychologist is interested in comparing two ways of presenting stimuli on subsequent memory. Twelve subjects are presented with each method and a memory test is given. What would be the roles of descriptive and inferential statistics in the analysis of these data? (relevant section 1 & relevant section 2 )
Q3
If you are told that you scored in the \(80^{th}\) percentile, from just this information would you know exactly what that means and how it was calculated? Explain. (relevant section)
Q4
A study is conducted to determine whether people learn better with spaced or massed practice. Subjects volunteer from an introductory psychology class. At the beginning of the semester \(12\) subjects volunteer and are assigned to the massed-practice condition. At the end of the semester \(12\) subjects volunteer and are assigned to the spaced-practice condition. This experiment involves two kinds of non-random sampling:
- Subjects are not randomly sampled from some specified population
- Subjects are not randomly assigned to conditions.
Which of the problems relates to the generality of the results? Which of the problems relates to the validity of the results? Which problem is more serious? (relevant section)
Q5
Give an example of an independent and a dependent variable. (relevant section)
Q6
Categorize the following variables as being qualitative or quantitative: (relevant section)
- Rating of the quality of a movie on a \(7\)-point scale
- Age
- Country you were born in
- Favorite Color
- Time to respond to a question
Q7
Specify the level of measurement used for the items in Question 6. (relevant section)
Q8
Which of the following are linear transformations? (relevant section)
- Converting from meters to kilometers
- Squaring each side to find the area
- Converting from ounces to pounds
- Taking the square root of each person's height.
- Multiplying all numbers by \(2\) and then adding \(5\)
- Converting temperature from Fahrenheit to Centigrade
Q9
The formula for finding each student's test grade (\(g\)) from his or her raw score (\(s\)) on a test is as follows: \[g = 16 + 3s\]
Is this a linear transformation? If a student got a raw score of \(20\), what is his test grade? (relevant section)
Q10
For the numbers \(1, 2, 4, 16\), compute the following: (relevant section)
- \(\sum X\)
- \(\sum X^2\)
- \(\left ( \sum X \right )^2\)
Q11
Which of the frequency polygons has a large positive skew? Which has a large negative skew? (relevant section)
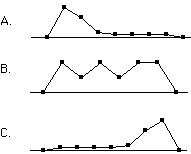
Q12
What is more likely to have a skewed distribution: time to solve an anagram problem (where the letters of a word or phrase are rearranged into another word or phrase like "dear" and "read" or "funeral" and "real fun") or scores on a vocabulary test? (relevant section)
Questions from Case Studies:
The following questions are from the Angry Moods (AM) case study.
Q13
(AM#1) Which variables are the participant variables? (They act as independent variables in this study.) (relevant section)
Q14
(AM#2) What are the dependent variables? (relevant section)
Q15
(AM#3) Is Anger-Out a quantitative or qualitative variable? (relevant section)
The following question is from the Teacher Ratings (TR) case study.
Q16
(TR#1) What is the independent variable in this study? (relevant section)
The following questions are from the ADHD Treatment (AT) case study.
Q17
(AT#1) What is the independent variable of this experiment? How many levels does it have? (relevant section)
Q18
(AT#2) What is the dependent variable? On what scale (nominal, ordinal, interval, ratio) was it measured? (relevant section)
Select Answers
S9
\(76\)
S10
\(23, 277, 529\)