
1.9: Measurements
- Page ID
- 266

Learning Objectives
- Understand what it means for a scale to be ordinal and its relationship to interval scales.
- Determine whether an investigator can be misled by computing the means of an ordinal scale.
Instructions
This is a demonstration of a very complex issue. Experts in the field disagree on how to interpret differences on an ordinal scale, so do not be discouraged if it takes you a while to catch on. In this demonstration you will explore the relationship between interval and ordinal scales. The demonstration is based on two brands of baked goods.
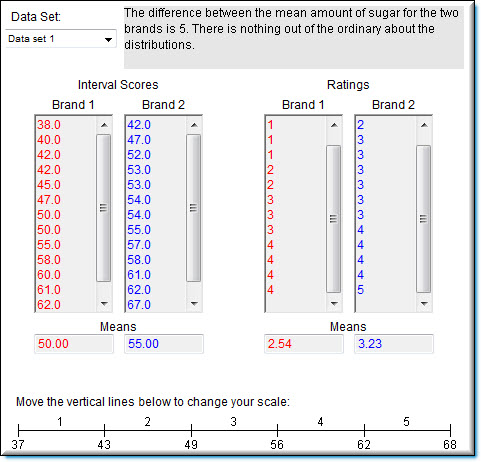
The data on the left side labeled "interval scores" shows the amount of sugar in each of \(12\) products. The column labeled "\(\text{Brand 1}\)" contains the sugar content of each of \(12\) brand-one products. The second column ("\(\text{Brand 1}\)") shows the sugar content of the brand-two products. The amount of sugar is measured on an interval scale.
A rater tastes each of the products and rates them on a \(5\)-point "sweetness" scale. Rating scales are typically ordinal rather than interval.
The scale at the bottom shows the "mapping" of sugar content onto the ratings. Sugar content between \(37\) and \(43\) is rated as \(1\), between \(43\) and \(49, 2, etc.\) Therefore, the difference between a rating of \(1\) and a rating of \(2\) represents, on average a "sugar difference" of \(6\). A difference between a rating of \(2\) and a rating of \(3\) also represents, on average a "sugar difference" of \(6\). The original ratings are rounded off and displayed are on an interval scale. It is likely that rater's ratings would not be on an interval scale. You can change the cutoff points between ratings by moving the vertical lines with the mouse. As you change these cutoffs, the ratings change automatically. For example, you might see what the ratings would look like if people did not consider something very sweet (rating of \(5\)) unless it was very very sweet.
The mean amount of sugar in \(\text{Data Set 1}\) is \(50\) for the first brand and \(55\) for the second brand. The obvious conclusion is that, on average, the second brand is sweeter than the first. However, pretend that you only had the ratings to go by and were not aware of the actual amounts of sugar. Would you reach the correct decision if you compared the mean ratings of the two brands. Change the cutoffs for mapping the interval sugar scale onto the ordinal rating scale. Do any mappings lead to incorrect interpretations? Try this with \(\text{Data Set 1}\) and with \(\text{Data Set 2}\). Try to find a situation where the mean sweetness rating is higher for \(\text{Brand 2}\) even though the mean amount of sugar is greater for \(\text{Brand 1}\). If you find such a situation, then you have found an instance in which using the means of ordinal data lead to incorrect conclusions. It is possible to find this situation, so look hard.
Keep in mind that in realistic situations, you only know the ratings and not the "true" interval scale that underlies them. If you knew the interval scale, you would use it.