
5.2: The Normal Distribution
- Page ID
- 7226

Figure \(\PageIndex{1}\): The Normal Distribution
Note that the the tails go to ±∞±∞. In addition, the density of a distribution over the range of x is the key to hypothesis testing With a normal distribution, ∼68%∼68% of the observations will fall within 11 standard deviation of the mean, ∼95%∼95% will fall within 2 standard deviations, and ∼99.7%∼99.7% within 3 standard deviations. This is illustrated in Figures 5.2, 5.3, 5.4.
Figure \(\PageIndex{1}\): The Normal Distribution
Note that the the tails go to ±∞±∞. In addition, the density of a distribution over the range of x is the key to hypothesis testing With a normal distribution, ∼68%∼68% of the observations will fall within 11 standard deviation of the mean, ∼95%∼95% will fall within 2 standard deviations, and ∼99.7%∼99.7% within 3 standard deviations. This is illustrated in Figures 5.2, 5.3, 5.4.
For purposes of statistical inference, the normal distribution is one of the most important types of probability distributions. It forms the basis of many of the assumptions needed to do quantitative data analysis, and is the basis for a wide range of hypothesis tests. A standardized normal distribution has a mean, μμ, of 00 and a standard deviation (s.d.), σσ, of 11. The distribution of an outcome variable, YY, can be described:
Y∼N(μY,σ2Y)(5.1)(5.1)Y∼N(μY,σY2)
Where ∼∼ stands for “distributed as”, NN indicates the normal distribution, and mean μYμY and variance σ2YσY2 are the parameters. The probability function of the normal distribution is expressed below:
The Normal Probability Density Function: The probability density function (PDF) of a normal distribution with mean μμ and standard deviation σσ:
$f(x) = \frac{1}{\sigma \sqrt{2 \pi}} e^{-(x-\mu)^{2}/2\sigma^{2}}$The Standard Normal Probability Density Function: The standard normal PDF has a μ=0μ=0 and σ=1σ=1
$f(x) = \frac{1}{\sqrt{2 \pi}}e^{-x^{2}/2}$
Using the standard normal PDF, we can plot a normal distribution in R.
x <- seq(-4,4,length=200)
y <- 1/sqrt(2*pi)*exp(-x^2/2)
plot(x,y, type="l", lwd=2)
Note that the the tails go to ±∞±∞. In addition, the density of a distribution over the range of x is the key to hypothesis testing With a normal distribution, ∼68%∼68% of the observations will fall within 11 standard deviation of the mean, ∼95%∼95% will fall within 2 standard deviations, and ∼99.7%∼99.7% within 3 standard deviations. This is illustrated in Figures 5.2, 5.3, 5.4.
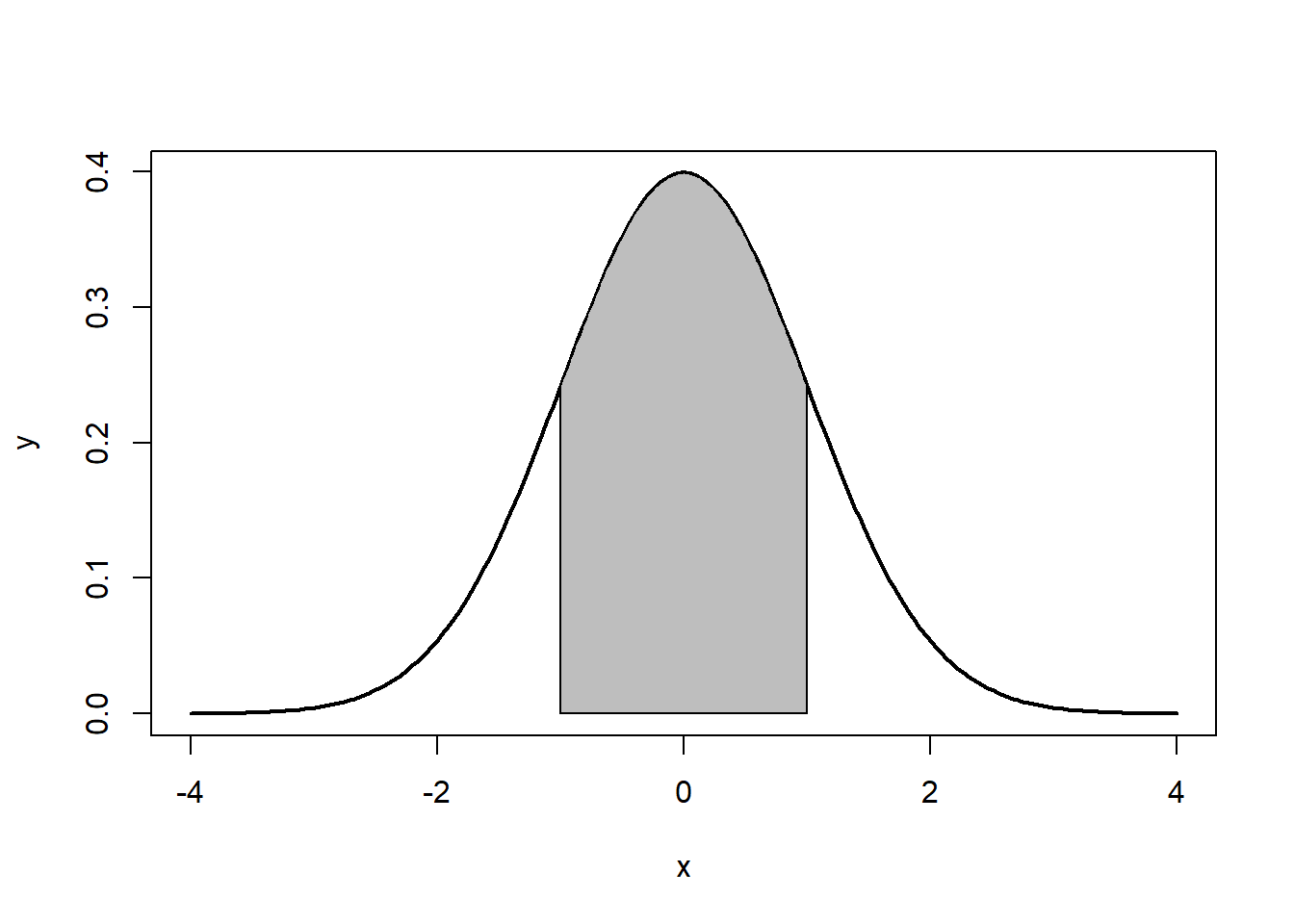
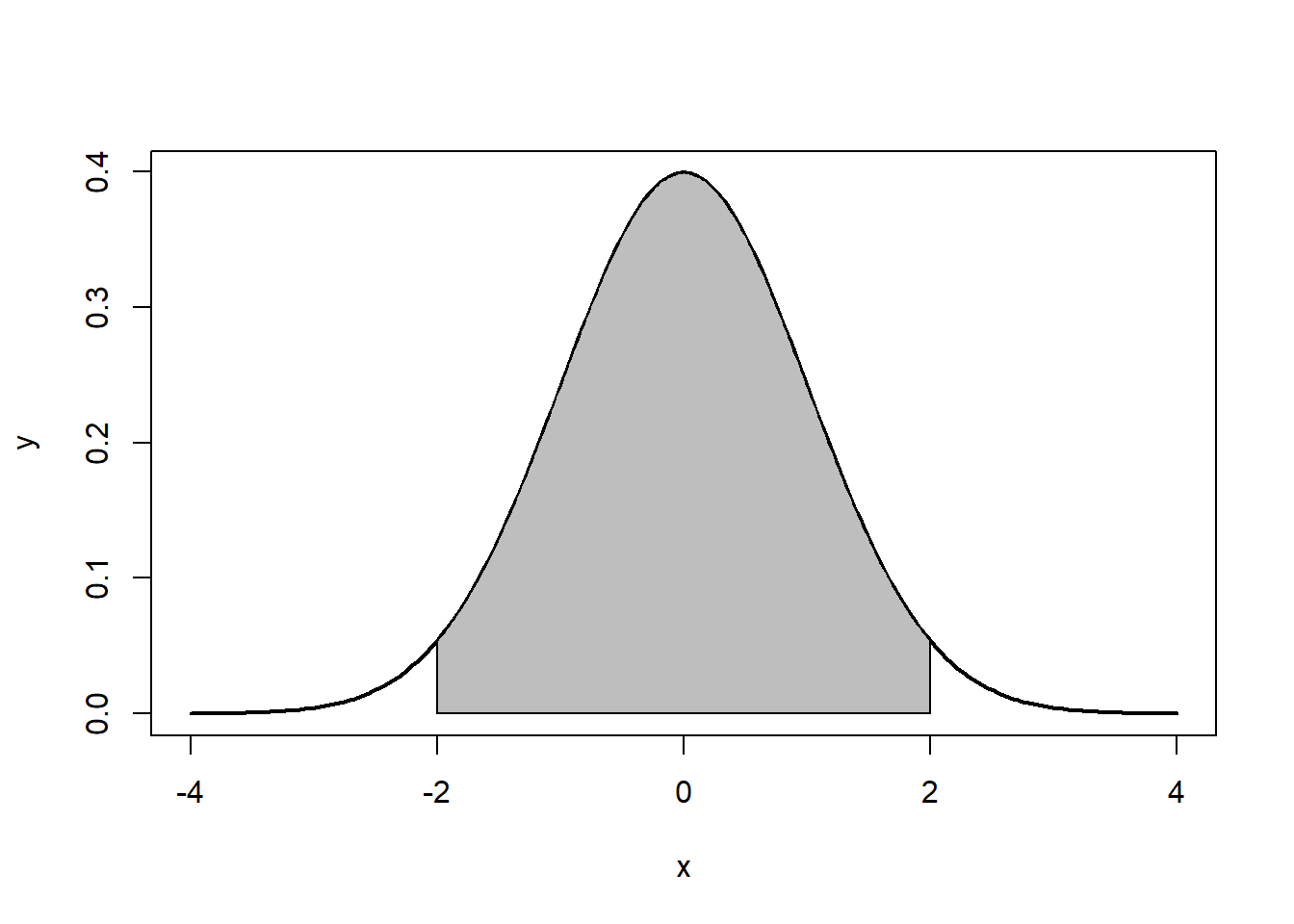
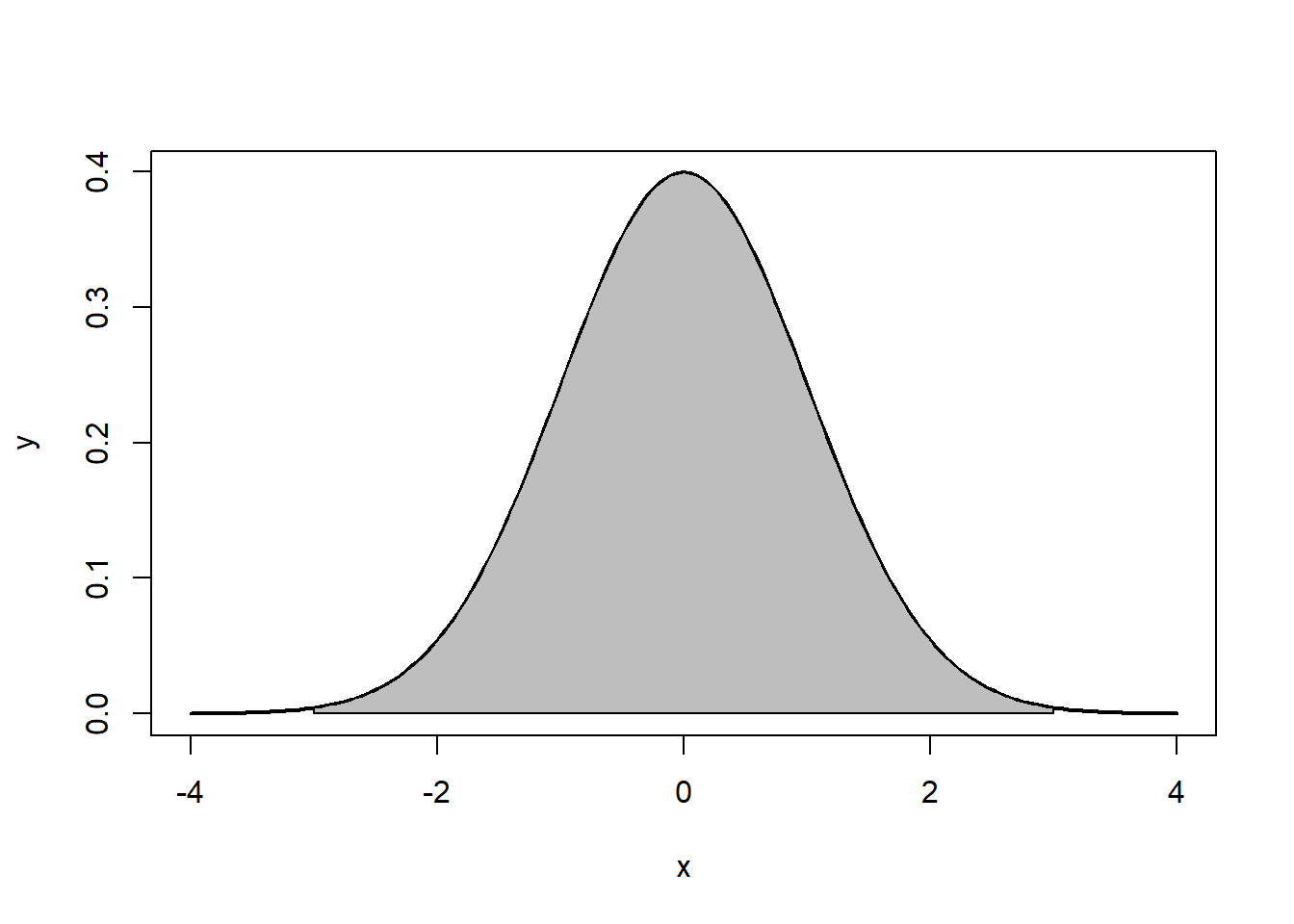
The normal distribution is characterized by several important properties. The distribution of observations is symmetrical around the mean μμ; the frequency of observations is highest (the mode) at μμ, with more extreme values occurring with lower frequency (this can be seen in Figure ??); and only the mean and variance are needed to characterize data and test simple hypotheses.
The Properties of the Normal Distribution
- It is symmetrical around its mean and median, μμ
- The highest probability (aka “the mode”) occurs at its mean value
- Extreme values occur in the tails
- It is fully described by its two parameters, μμ and σ2σ2
If the values for μμ and σ2σ2 are known, which might be the case with a population, then we can calculate a ZZ-score to compare differences in μμ and σ2σ2 between two normal distributions or obtain the probability for a given value given μμ and σ2σ2. The ZZ-score is calculated:
Z=Y−μYσ(5.2)(5.2)Z=Y−μYσ
Therefore, if we have a normal distribution with a μμ of 70 and a σ2σ2 of 9, we can calculate a probability for i=75i=75. First we calculate the ZZ-score, then we determine the probability of that score based on the normal distribution.
z <- (75-70)/3
z## [1] 1.666667p <- pnorm(1.67)
p## [1] 0.9525403p <- 1-p
p## [1] 0.04745968As shown, a score of 7575 falls just outside two standard deviations (>0.95>0.95), and the probability of obtaining that score when μ=70μ=70 and σ2=9σ2=9 is just under 5%.
5.2.1 Standardizing a Normal Distribution and Z-scores
A distribution can be plotted using the raw scores found in the original data. That plot will have a mean and standard deviation calculated from the original data. To utilize the normal curve to determine probability functions and for inferential statistics we will want to convert that data so that it is standardized. We standardize so that the distribution is consistent across all distributions. That standardization produces a set of scores that have a mean of zero and a standard deviation of one. A standardized or Z-score of 1.5 means, therefore, that the score is one and a half standard deviations about the mean. A Z-score of -2.0 means that the score is two standard deviations below the mean.
As formula (4.4) indicated, standardizing is a simple process. To move the mean from its original value to a mean of zero, all you have to do is subtract the mean from each score. To standardize the standard deviation to one all that is necessary is to divide each score the standard deviation.
5.2.2 The Central Limit Theorem
An important property of samples is associated with the Central Limit Theorem (CLT). Imagine for a moment that we have a very large (or even infinite) population, from which we can draw as many samples as we’d like. According to the CLT, as the nn-size (number of observations) within a sample drawn from that population increases, the more the distribution of the means taken from samples of that size will resemble a normal distribution. This is illustrated in Figure \(\PageIndex{5}\). Also note that the population does not need to have a normal distribution for the CLT to apply. Finally, a distribution of means from a normal population will be approximately normal at any sample size.