
11.8: Effect Size, Sample Size and Power
- Page ID
- 8245

In previous sections I’ve emphasised the fact that the major design principle behind statistical hypothesis testing is that we try to control our Type I error rate. When we fix α=.05 we are attempting to ensure that only 5% of true null hypotheses are incorrectly rejected. However, this doesn’t mean that we don’t care about Type II errors. In fact, from the researcher’s perspective, the error of failing to reject the null when it is actually false is an extremely annoying one. With that in mind, a secondary goal of hypothesis testing is to try to minimise β, the Type II error rate, although we don’t usually talk in terms of minimising Type II errors. Instead, we talk about maximising the power of the test. Since power is defined as 1−β, this is the same thing.
power function

Let’s take a moment to think about what a Type II error actually is. A Type II error occurs when the alternative hypothesis is true, but we are nevertheless unable to reject the null hypothesis. Ideally, we’d be able to calculate a single number β that tells us the Type II error rate, in the same way that we can set α=.05 for the Type I error rate. Unfortunately, this is a lot trickier to do. To see this, notice that in my ESP study the alternative hypothesis actually corresponds to lots of possible values of θ. In fact, the alternative hypothesis corresponds to every value of θ except 0.5. Let’s suppose that the true probability of someone choosing the correct response is 55% (i.e., θ=.55). If so, then the true sampling distribution for X is not the same one that the null hypothesis predicts: the most likely value for X is now 55 out of 100. Not only that, the whole sampling distribution has now shifted, as shown in Figure 11.4. The critical regions, of course, do not change: by definition, the critical regions are based on what the null hypothesis predicts. What we’re seeing in this figure is the fact that when the null hypothesis is wrong, a much larger proportion of the sampling distribution distribution falls in the critical region. And of course that’s what should happen: the probability of rejecting the null hypothesis is larger when the null hypothesis is actually false! However θ=.55 is not the only possibility consistent with the alternative hypothesis. Let’s instead suppose that the true value of θ is actually 0.7. What happens to the sampling distribution when this occurs? The answer, shown in Figure 11.5, is that almost the entirety of the sampling distribution has now moved into the critical region. Therefore, if θ=0.7 the probability of us correctly rejecting the null hypothesis (i.e., the power of the test) is much larger than if θ=0.55. In short, while θ=.55 and θ=.70 are both part of the alternative hypothesis, the Type II error rate is different.


What all this means is that the power of a test (i.e., 1−β) depends on the true value of θ. To illustrate this, I’ve calculated the expected probability of rejecting the null hypothesis for all values of θ, and plotted it in Figure 11.6. This plot describes what is usually called the power function of the test. It’s a nice summary of how good the test is, because it actually tells you the power (1−β) for all possible values of θ. As you can see, when the true value of θ is very close to 0.5, the power of the test drops very sharply, but when it is further away, the power is large.
Effect size
Since all models are wrong the scientist must be alert to what is importantly wrong. It is inappropriate to be concerned with mice when there are tigers abroad
– George Box 1976
The plot shown in Figure 11.6 captures a fairly basic point about hypothesis testing. If the true state of the world is very different from what the null hypothesis predicts, then your power will be very high; but if the true state of the world is similar to the null (but not identical) then the power of the test is going to be very low. Therefore, it’s useful to be able to have some way of quantifying how “similar” the true state of the world is to the null hypothesis. A statistic that does this is called a measure of effect size (e.g. Cohen 1988; Ellis 2010). Effect size is defined slightly differently in different contexts,165 (and so this section just talks in general terms) but the qualitative idea that it tries to capture is always the same: how big is the difference between the true population parameters, and the parameter values that are assumed by the null hypothesis? In our ESP example, if we let θ0=0.5 denote the value assumed by the null hypothesis, and let θ denote the true value, then a simple measure of effect size could be something like the difference between the true value and null (i.e., θ−θ0), or possibly just the magnitude of this difference, abs(θ−θ0).
| big effect size | small effect size | |
|---|---|---|
| significant result | difference is real, and of practical importance | difference is real, but might not be interesting |
| non-significant result | no effect observed | no effect observed |
Why calculate effect size? Let’s assume that you’ve run your experiment, collected the data, and gotten a significant effect when you ran your hypothesis test. Isn’t it enough just to say that you’ve gotten a significant effect? Surely that’s the point of hypothesis testing? Well, sort of. Yes, the point of doing a hypothesis test is to try to demonstrate that the null hypothesis is wrong, but that’s hardly the only thing we’re interested in. If the null hypothesis claimed that θ=.5, and we show that it’s wrong, we’ve only really told half of the story. Rejecting the null hypothesis implies that we believe that θ≠.5, but there’s a big difference between θ=.51 and θ=.8. If we find that θ=.8, then not only have we found that the null hypothesis is wrong, it appears to be very wrong. On the other hand, suppose we’ve successfully rejected the null hypothesis, but it looks like the true value of θ is only .51 (this would only be possible with a large study). Sure, the null hypothesis is wrong, but it’s not at all clear that we actually care, because the effect size is so small. In the context of my ESP study we might still care, since any demonstration of real psychic powers would actually be pretty cool166, but in other contexts a 1% difference isn’t very interesting, even if it is a real difference. For instance, suppose we’re looking at differences in high school exam scores between males and females, and it turns out that the female scores are 1% higher on average than the males. If I’ve got data from thousands of students, then this difference will almost certainly be statistically significant, but regardless of how small the p value is it’s just not very interesting. You’d hardly want to go around proclaiming a crisis in boys education on the basis of such a tiny difference would you? It’s for this reason that it is becoming more standard (slowly, but surely) to report some kind of standard measure of effect size along with the the results of the hypothesis test. The hypothesis test itself tells you whether you should believe that the effect you have observed is real (i.e., not just due to chance); the effect size tells you whether or not you should care.
Increasing the power of your study
Not surprisingly, scientists are fairly obsessed with maximising the power of their experiments. We want our experiments to work, and so we want to maximise the chance of rejecting the null hypothesis if it is false (and of course we usually want to believe that it is false!) As we’ve seen, one factor that influences power is the effect size. So the first thing you can do to increase your power is to increase the effect size. In practice, what this means is that you want to design your study in such a way that the effect size gets magnified. For instance, in my ESP study I might believe that psychic powers work best in a quiet, darkened room; with fewer distractions to cloud the mind. Therefore I would try to conduct my experiments in just such an environment: if I can strengthen people’s ESP abilities somehow, then the true value of θ will go up167 and therefore my effect size will be larger. In short, clever experimental design is one way to boost power; because it can alter the effect size.
Unfortunately, it’s often the case that even with the best of experimental designs you may have only a small effect. Perhaps, for example, ESP really does exist, but even under the best of conditions it’s very very weak. Under those circumstances, your best bet for increasing power is to increase the sample size. In general, the more observations that you have available, the more likely it is that you can discriminate between two hypotheses. If I ran my ESP experiment with 10 participants, and 7 of them correctly guessed the colour of the hidden card, you wouldn’t be terribly impressed. But if I ran it with 10,000 participants and 7,000 of them got the answer right, you would be much more likely to think I had discovered something. In other words, power increases with the sample size. This is illustrated in Figure 11.7, which shows the power of the test for a true parameter of θ=0.7, for all sample sizes N from 1 to 100, where I’m assuming that the null hypothesis predicts that θ0=0.5.
## [1] 0.00000000 0.00000000 0.00000000 0.00000000 0.00000000 0.11837800
## [7] 0.08257300 0.05771362 0.19643626 0.14945203 0.11303734 0.25302172
## [13] 0.20255096 0.16086106 0.29695959 0.24588947 0.38879291 0.33269435
## [19] 0.28223844 0.41641377 0.36272868 0.31341925 0.43996501 0.38859619
## [25] 0.51186665 0.46049782 0.41129777 0.52752694 0.47870819 0.58881596
## [31] 0.54162450 0.49507894 0.59933871 0.55446069 0.65155826 0.60907715
## [37] 0.69828554 0.65867614 0.61815357 0.70325017 0.66542910 0.74296156
## [43] 0.70807163 0.77808343 0.74621569 0.71275488 0.78009449 0.74946571
## [49] 0.81000236 0.78219322 0.83626633 0.81119597 0.78435605 0.83676444
## [55] 0.81250680 0.85920268 0.83741123 0.87881491 0.85934395 0.83818214
## [61] 0.87858194 0.85962510 0.89539581 0.87849413 0.91004390 0.89503851
## [67] 0.92276845 0.90949768 0.89480727 0.92209753 0.90907263 0.93304809
## [73] 0.92153987 0.94254237 0.93240638 0.92108426 0.94185449 0.93185881
## [79] 0.95005094 0.94125189 0.95714694 0.94942195 0.96327866 0.95651332
## [85] 0.94886329 0.96265653 0.95594208 0.96796884 0.96208909 0.97255504
## [91] 0.96741721 0.97650832 0.97202770 0.97991117 0.97601093 0.97153910
## [97] 0.97944717 0.97554675 0.98240749 0.97901142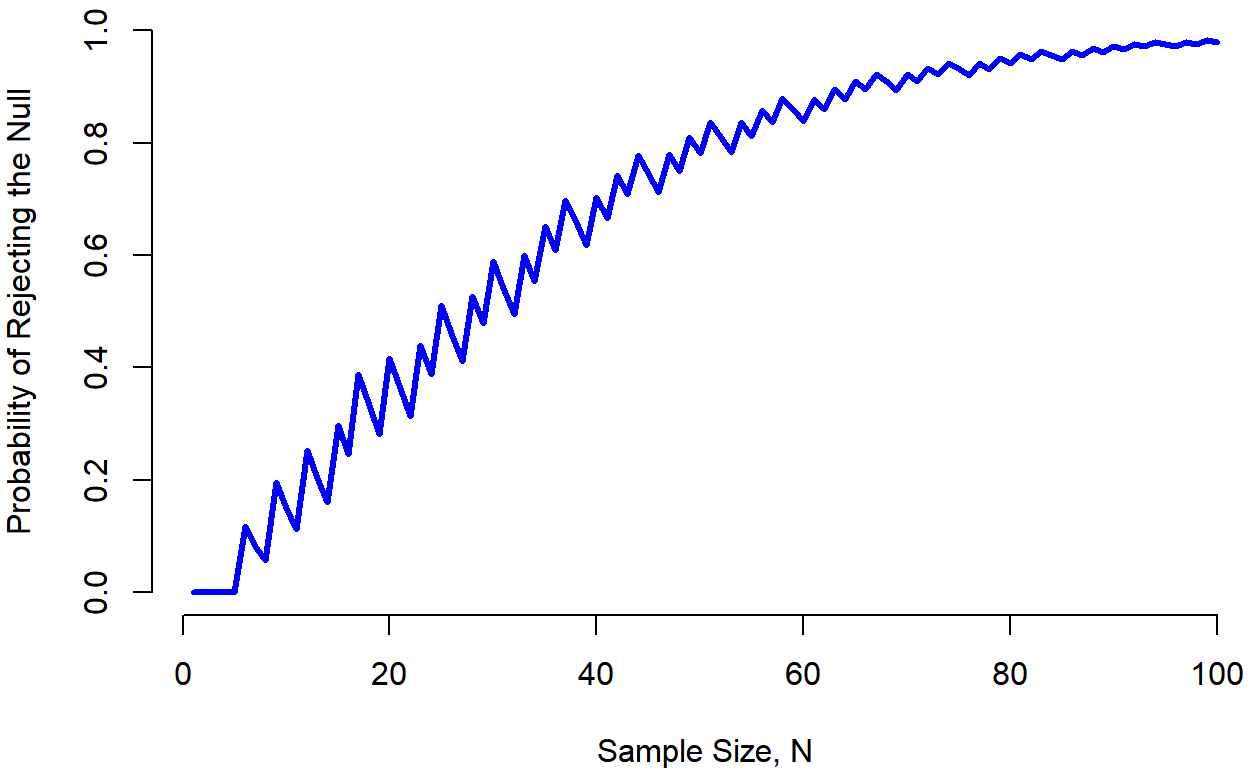
Because power is important, whenever you’re contemplating running an experiment it would be pretty useful to know how much power you’re likely to have. It’s never possible to know for sure, since you can’t possibly know what your effect size is. However, it’s often (well, sometimes) possible to guess how big it should be. If so, you can guess what sample size you need! This idea is called power analysis, and if it’s feasible to do it, then it’s very helpful, since it can tell you something about whether you have enough time or money to be able to run the experiment successfully. It’s increasingly common to see people arguing that power analysis should be a required part of experimental design, so it’s worth knowing about. I don’t discuss power analysis in this book, however. This is partly for a boring reason and partly for a substantive one. The boring reason is that I haven’t had time to write about power analysis yet. The substantive one is that I’m still a little suspicious of power analysis. Speaking as a researcher, I have very rarely found myself in a position to be able to do one – it’s either the case that (a) my experiment is a bit non-standard and I don’t know how to define effect size properly, (b) I literally have so little idea about what the effect size will be that I wouldn’t know how to interpret the answers. Not only that, after extensive conversations with someone who does stats consulting for a living (my wife, as it happens), I can’t help but notice that in practice the only time anyone ever asks her for a power analysis is when she’s helping someone write a grant application. In other words, the only time any scientist ever seems to want a power analysis in real life is when they’re being forced to do it by bureaucratic process. It’s not part of anyone’s day to day work. In short, I’ve always been of the view that while power is an important concept, power analysis is not as useful as people make it sound, except in the rare cases where (a) someone has figured out how to calculate power for your actual experimental design and (b) you have a pretty good idea what the effect size is likely to be. Maybe other people have had better experiences than me, but I’ve personally never been in a situation where both (a) and (b) were true. Maybe I’ll be convinced otherwise in the future, and probably a future version of this book would include a more detailed discussion of power analysis, but for now this is about as much as I’m comfortable saying about the topic.